СОЗДАНИЕ ИНТЕЛЛЕКТУАЛЬНОЙ СИСТЕМЫ СТИЛИСТИЧЕСКОЙ ОЦЕНКИ ТЕКСТА
Авторы: А.С. Столбунская, Т.Н. Кравец
Источник: Программная инженерия: методы и технологии разработки информационно–вычислительных систем (ПИИВС–2018): сборник материалов II Международной научно–практической конференции (студенческая секция). 14–15 ноября 2018 г. — Донецк, ГОУ ВПО Донецкий национальный технический университет
, 2018. — с. 253–256.
Аннотация
Столбунская А.С., Кравец Т.Н. Создание интеллектуальной системы стилистической оценки текста. Исследование обработки естественного языка — одно из направлений искусственного интеллекта и математической лингвистики, которое занимается изучением проблем компьютерного анализа и синтеза естественных языков. Сложностью оценки как процесса и результата познавательной деятельности является проблема статуса категории оценки на уровне слова, высказывания и текста. Разработка алгоритма анализа оценки решает ряд вопросов в области исследования текста.
Ключевые слова: статья, интеллектуальные системы, обработка текста, обработка естественного языка, чат-боты, машинное обучение.
Введение
В настоящее время основными проблемами лингвистики является изучение лексики и семантики, быстрый автоматизированный перевод. В этих исследованиях невозможно обойтись без работы со словарями и архивами. Но у учёных не всегда существует возможность доступа к необходимым информационным ресурсам. Помочь в этом современным лингвистам может такая отрасль науки, как компьютерная прикладная лингвистика, которая занимается созданием разнообразных систем по обработке естественного языка.
Целью данной работы является исследование обработки естественного языка — одного из направлений искусственного интеллекта и математической лингвистики, которое занимается изучением проблем компьютерного анализа и синтеза естественных языков.
Данная цель обусловила следующие задачи:
- определить понятие
обработка естественного языка
; - выявить основные задачи обработки естественного языка;
- выявить трудности, возникающие при выполнении задач естественного языка.
Обработка естественного языка
Обработка естественного языка — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста. Решение этих проблем будет означать создание более удобной формы взаимодействия компьютера и человека.
Понимание, распознавание естественного языка — ключевая задача, поскольку узнавание и распознавание языка живого требует колоссальных знаний языковой системы, языкового строя, их особенностей и закономерностей.
Существует 10 основных и наиболее актуальных задач обработки естественного языка.
- Распознавание речи — процесс, ведущий к преобразованию речевого сигнала человеческого голоса в цифровую информацию.
- Синтез речи — формирование по печатному тексту сигналов речи, то есть искусственное производство человеческой речи.
- Анализ текста — процесс извлечения содержательной, высокого качества информации из текста на естественном языке для автоматизации процесса извлечения и анализа данных.
- Синтез текста — это объединение слов в предложения, предложений в текст по заданной на этапе анализа прагматической структуре. Задача синтеза может рассматриваться как обратная по отношению к анализу.
- Машинный, или автоматический перевод — процесс перевода устных текстов, написанных на естественном языке, на другой, тоже естественный, язык при помощи электронно-вычислительных машин в предназначенных для данного типа задач компьютерных программах.
- Создание вопросно-ответных систем — системы, которые способны принимать, распознавать, классифицировать вопросы и давать ответы на них на естественном языке.
- Информационный поиск — процесс выявления информации в документах, содержащихся в доступных системе поиска базах данных, которые соответствуют заданному запросу по тематике.
- Извлечение информации — задачи обработки естественного языка, выполняющая автоматическое извлечение необходимых данных из источника информации, текста.
- Анализ тональности текста — анализ лексем текста, оценка их эмоциональной окрашенности и классификация по принадлежности к нейтральному, позитивному или негативному лексическому слою языка.
- Реферирование — сокращение объёма текста за счёт выделения основных тезисов путём поиска соответствий заданным в поиске ключевым словам и его краткое изложение.
Трудности при выполнении задач
В процессе выполнения задач возникают препятствия, создаваемые теми или иными особенностями естественного языка. Например, на качество понимания текста могут повлиять такие факторы, как:
- отнесённость языка к той или иной языковой семье, группе;
- порядок речи (прямой, обратный или свободный);
- характерные особенности национальной культуры носителей естественного языка;
- логический строй речи;
- синтаксическое построение речи;
- грамматический строй речи;
- грамотность;
- фонетические особенности речи;
- полисемичность языка;
- наличие омонимов в данном естественном языке;
- способы словообразования, присущие определённому языку;
- неологизмы, окказионализмы;
- фразеологические обороты и устойчивые выражения.
Структурирование естественного языка
Компьютеры замечательно работают со структурированной информацией, например таблицами в базах данных. Но люди общаются друг с другом не таблицами, а словами. Для компьютеров это слишком сложно.
Проблемой извлечения данных машиной из обычного текста занимается особое направление искусственного интеллекта: обработка естественного языка, или NLP (Natural Language Processing).
Компьютеры не могут в полной мере понимать живой человеческий язык, однако они на многое способны. NLP может делать по-настоящему волшебные вещи и экономить огромное количество времени.
Процесс чтения и понимания текста сам по себе очень сложен. Люди часто не соблюдают логику и последовательность повествования.
Реализация какой-либо сложной комплексной задачи в машинном обучении обычно означает построение конвейера. Смысл этого подхода в том, чтобы разбить проблему на очень маленькие части и решать их отдельно. Соединив несколько таких моделей, поставляющих друг другу данные, вы можете получать замечательные результаты.
Сначала нужно разбить процесс языкового анализа на стадии и понять, как они работают.
- Выделение предложений. Можно предположить, что каждое предложение — это самостоятельная мысль или идея. Проще научить программу понимать единственное предложение, а не целый параграф.
Можно было бы просто разделять текст по определенным знакам препинания. Но современные NLP конвейеры имеют в запасе более сложные методы, подходящие даже для работы с неформатированными фрагментами.
- Токенизация, или выделение слов. Выделение отдельных слов или токенов — токенизация. Отделение фрагмента текста, когда встречаем пробел. Знаки препинания тоже являются токенами, поскольку могут иметь важное значение.
- Определение частей речи. Просматривает каждый токен и старается угадать, какой частью речи он является: существительным, глаголом, прилагательным или чем-то другим. Зная роль каждого слова в предложении, можно понять его общий смысл.
Анализирует каждое слово вместе с его ближайшим окружением с помощью предварительно подготовленной классификационной модели. Она была обучена на миллионе предложений с уже обозначенными частями речи для каждого слова и теперь способна их распознавать. Данный анализ основан на статистике — на самом деле модель не понимает смысла слов, вложенного в них человеком.
- Лемматизация. В языках слова могут иметь различные формы. Если тексты обрабатывает компьютер, он должен знать основную форму каждого слова, чтобы понимать, что речь идет об одной и той же концепции. В NLP этот процесс называется лемматизацией — нахождением основной формы (леммы) каждого слова в предложении.
- Определение стоп-слов. Определение важности каждого слова в предложении. Например, в английском языке очень много вспомогательных слов, таких как:
and
,the
,a
. При статистическом анализе текста эти токены создают много шума, так как появляются чаще, чем остальные. Некоторые NLP пайплайны отмечают их как стоп-слова и отсеивают перед подсчетом количества. Для обнаружения стоп-слов обычно используются готовые таблицы. - Парсинг зависимостей. Установление взаимосвязей между словами в предложении. Это называется парсингом зависимостей. Конечная цель — построение дерева, в котором каждый токен имеет единственного родителя. Корнем может быть главный глагол. Модель получает слова и возвращает результат. Однако это более сложная задача.
6.1. Поиск групп существительных. Рассматривает каждое слово в нашем предложении как отдельную сущность. Но иногда нужно сгруппировать токены, которые относятся к одной и той же идее или вещи. Используется полученное дерево парсинга, чтобы автоматически объединить такие слова.
- Распознавание именованных сущностей (Named Entity Recognition, NER). Обнаружение существительных и связей их с реальными концепциями. NER-системы не просто просматривают словари. Они анализируют контекст токена в предложении и используют статистические модели, чтобы угадать какой объект он представляет.
- Разрешение кореференции. Разрешением кореференции называется отслеживание местоимений в предложениях с целью выбрать все слова, относящиеся к одной сущности. Скомбинировав эту методику с деревом парсинга и информацией об именованных сущностях и получить возможность извлечь из документа огромное количество полезных данных.
Конвейер NLP на Python
На рисунке 1 изображены стандартные этапы обычного NLP-конвейера, но в зависимости от конечной цели проекта и особенностей реализации модели, некоторые из них можно пропускать или менять местами. Все перечисленные шаги уже написаны и готовы к использованию.
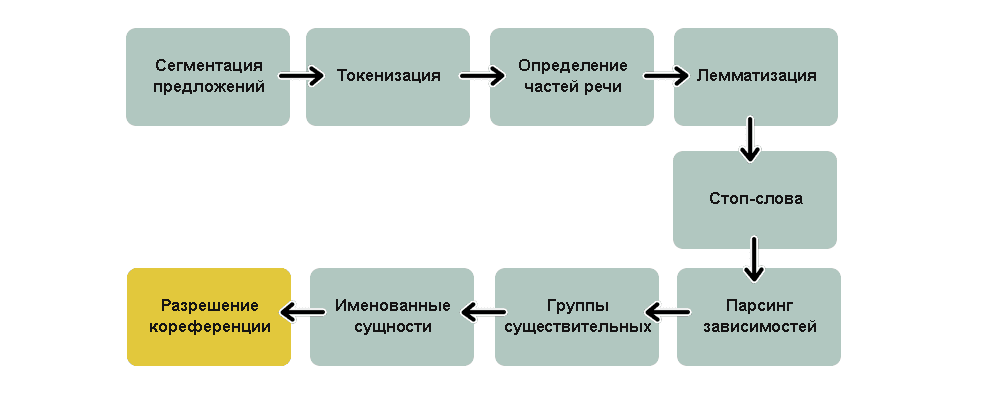
Рисунок 1 — Резюмирующая схема конвейера
Обработка естественного языка и машинное обучение
Благодаря обработке естественного языка и машинному обучению чат-боты могут интерпретировать данные, поступившие на естественном языке. Диалоговые системы помогают расшифровать эти данные в значимую информацию, и предоставляют ответ за запрос.
Многие компании пытаются разработать идеального чат-бота, который, ведёт диалог, неотличимый от обычного общения между людьми. Новые чат-боты используют глубокое обучение не только для анализа ввода человеческой речи, но и для генерирования ответов. Анализ и создание ответа достигается в результате использования алгоритма глубокого обучения, который применяется в декодировке ввода и генерировании ответа. NLP также переводит ввод и вывод в текстовый формат, понятный и компьютеру, и человеку.
Список задач, которые искусственная обработка языка должна решать. Многие из них могут быть связаны с распознаванием как текста, так и речи или даже картинок.
- Реферирование. Задача состоит в том, чтобы создать реферат или резюме большого текста.
- Открытые и закрытые вопросы. От современных чат–ботов ожидают готовности ответить на вопросы независимо от того, открытые они или закрытые.
- Сопоставление. Бот должен сопоставлять объекты со словами, и понимать, когда разные слова относятся к одному объекту.
- Двусмысленность. Двусмысленность, которая часто содержится в явлениях естественного языка, пока что представляют серьёзную проблему для ботов. Одна только омонимия требует, чтоб было выбранное правильное значение в зависимости от контекста.
- Морфология. Чат-бот должен уметь разделить слова на морфемы.
- Семантика. Собственно, это задача определения смысла предложений или слов в естественном языке, и генерация высказываний на естественном языке.
- Структура текста. Связанность со структурой текста и пунктуацией.
- Тональность. Чат-бот должен различать эмоциональную окраску высказываний человека, его отношение к предмету разговора. Должен распознавать по манере человека изъясняться, строению предложений и выбору слов, в каком настроении человек: зол, счастлив, печален.
Заключение
В статье было дано определение понятию обработка естественного языка
, а также выявлены основные задачи обработки естественного языка, и трудности, возникающие при выполнении задач. Не смотря на наличие большого количества научных публикаций и обучающих руководств на тему NLP в интернете, на сегодняшний день практически не существует полноценных рекомендаций и советов на тему того, как эффективно справляться с задачами NLP, при этом рассматривающих решения этих задач с самых основ.
Также в данной работе рассматривается понятие искусственного интеллекта, подходы к разработке и направления искусственного интеллекта.
Обработка естественного языка позволяет получать новые восхитительные результаты и является очень широкой областью.
Список литературы
- Корн, Г. Справочник по математике для научных работников и инженеров / Г. Корн, Т. Корн. — М.: Наука. Главная редакция физико-математической литературы, 1974. — 832 с.
- Джаратано, Джозеф. Экспертные системы: принципы разработки и программирование / Джозеф Джаратано. — М.: Высшая школа, 2002. — 1152 с.
- Ясницкий, Л. Н. Введение в искусственный интеллект / Л. Н. Ясницкий. — М.: Издат. центр
Академия
, 2005. — 176 с. - Джексон, Питер Введение в экспертные системы / Питер Джексон. — Харьков, 1997. — 112 с.
- Большакова, Е.И. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика / Е.И. Большакова, Э.С. Клышинский, Д.Э. Ланде, А.А. Носков, О.В. Пескова. Е.В. Ягунова — М.: СССР-США СП
Параграф
, 1990. — 160 с.