ПАРАМЕТРИЧЕСКОЕ ОПИСАНИЕ МОДЕЛЕЙ ГЛУБОКИХ НЕЙРОННЫХ СЕТЕЙ В БИБЛИОТЕКЕ KERAS
Авторы: Ткачёв Н.М., Федяев О.И.
Источник: Программная инженерия: методы и технологии разработки информационно–вычислительных систем (ПИИВС–2018): сборник материалов II Международной научно–практической конференции (студенческая секция). 14–15 ноября 2018 г. — Донецк, ГОУ ВПО Донецкий национальный технический университет
, 2018. — с. 253–256.
Аннотация
Ткачёв Н.М., Федяев О.И. Параметрическое описание моделей глубоких нейронных сетей в библиотеке Keras. В статье представлен обзор различных видов глубоких нейронных сетей, их свойств, особенностей и предназначения. Рассмотрена высокоуровневая библиотека Keras, предназначенная для прототипирования нейронных сетей. На примерах рассмотрено описание элементов архитектуры нейронной сети на языке Python.
Ключевые слова: искусственная нейронная сеть, Keras, Python, глубокая свёрточная нейросеть, рекуррентная нейросеть.
Введение
Нейросетевые технологии являются одним из ведущих направлений искусственного интеллекта. Построенные с задумкой имитации работы головного мозга человека, искусственные нейронные сети позволяют автоматизировать широкий спектр трудноформализуемых задач. Распознавание и генерация визуальных образов и речи, обработка естественных языков, различного рода прогнозирование и даже создание произведений искусства — лишь немногие из широкого спектра решаемых нейросетями задач.
Долгое время нейронные сети считались непрактичными и развивались лишь теоретически [1]. Однако, новые теоретические разработки в этой области в значительной мере способствовала их популярности. В 2006–2007 гг. в своих публикациях Джеффри Хинтон продемонстрировал возросший потенциал глубоких нейронных сетей созданием нового способа их обучения [2]. Он показал, что каждый слой глубокой сети можно обучать по отдельности на большом объеме данных, а затем провести остаточную тонкую настройку всей сети методом обратного распространения ошибки; полученная в результате сеть обладала высокой производительностью. Значительным фактором в распространении нейросетей стали возможности аппаратного ускорения вычислений при помощи таких библиотек, как Nvidia CUDA и OpenCL. Делегация матричных вычислений графическим процессорам позволила ускорить обучение и работу глубоких сетей в отдельных случаях на несколько порядков. В 2014 году была продемонстрирована модель глубокой свёрточной сети VGG–16, достигшая значительных результатов в точности распознавания изображений. Эта модель показала, что точность работы глубокой сети значительно вырастает при увеличении количества слоёв до 16–19 по сравнению со старыми моделями, использовавшими до 10 слоёв [3].
В наше время приложения с функционалом, построенным на глубоких нейронных сетях, широко распространены в потребительском секторе. Современные мобильные устройства могут с высокой точностью распознавать рукописный текст, активно улучшаются автономные системы распознавания речи, программы автоматической корректировки и дополнения набираемого текста способны подстраиваться под каждого отдельного пользователя. Функция распознавания лиц из видеопотока с камеры показывает, что нейронные сети с современными архитектурами способны работать в режиме реального времени даже на устройствах с ограниченными ресурсами.
Архитектуры глубоких нейронных сетей
Cвёрточные нейронные сети (convolutional neural networks, CNN) [4] являются самой распространённой формой глубоких сетей. Главной особенностью CNN является то, что они способны обрабатывать входные данные сразу на нескольких уровнях абстракции путём поиска различного рода признаков, что позволяет более точно и с лучшей производительностью проводить классификацию входных данных. Также свёрточные сети частично устойчивы к различного рода искажениям (например, поворот изображения). Одним из главных достоинств CNN является простота распараллеливания работы и обучения, что даёт значительный прирост в производительности, в том числе благодаря возможности проведения вычислений на графических процессорах. Типичная свёрточная сеть состоит из входного слоя, нескольких последовательностей свёрточных слоёв, закрываемых подвыборочным (pooling) слоем, пары полносвязных (dense) слоёв и выходного слоя (см. рис. 1).

Рисунок 1 — Пример структуры свёрточной сети
Свёрточный слой генерирует матрицу выходных сигналов путём последовательного обхода матрицы входных данных матрицей весов. На каждом этапе матрице весов в соответствие ставится некоторый фрагмент исходной матрицы, соответствующие ячейки матриц умножаются, затем все результаты умножения суммируются и конечный результат записывается в ячейку матрицы выхода. Затем матрица весов смещается в сторону на одну ячейку (реже — на две или более) и процесс повторяется, пока матрица выходов не заполнится. Размеры матрицы выходов зависят от размеров исходной матрицы и матрицы весов. Количество возможных смещений в каждом направлении вычисляется по формуле: длина_матрицы_входа — длина_матрицы_весов + длина_смещения. Например, при обработке изображения размером 5x5 матрицей весов размером 2x2 матрица выходов будет иметь размер 4x4 (рис. 2), при матрице весов 3x3 — 3x3, 3x2 — 3x4. Каждая последовательность свёрточных слоёв решает задачу поиска признаков. Количество нейронов в каждом последующем слою уменьшается.
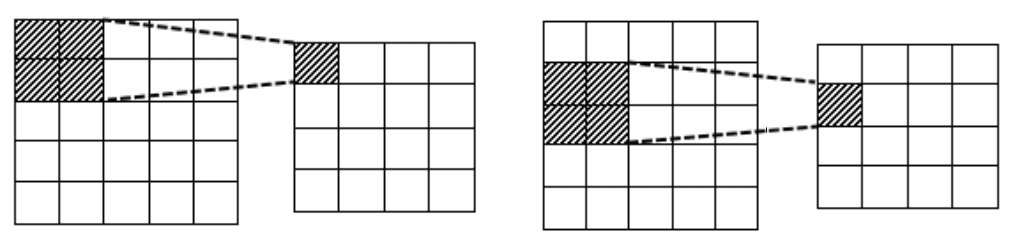
Рисунок 2 — Примеры шагов операции свёртки изображения 5x5 матрицей весов 2x2
Подвыборочный, или пулинговый слой используется для значительного уменьшения размерности матриц с целью повышения производительности (см. рис. 3). Пулинг применим тогда, когда предыдущие слои способны точно определить ярко выраженные признаки. После пулинга следующие слои пытаются найти признаки более высокого уровня абстракции. Аналогично свёрточному слою, подвыборочный слой генерирует свою выходную матрицу путём последовательного обхода матрицы входных данных, но с двумя различиями: 1) фрагменты входной матрицы не пересекаются (потому длина матрицы выхода будет равна длине матрицы входа, делённой на длину матрицы пулинга); 2) пулинговый слой не имеет весовых коэффициентов, и проводит операцию исключительно на входах. Существует множество видов операций пулинга, из них основные: max–pooling (выбор наибольшего значения) и усреднённый пулинг (вычисление среднего арифметического).
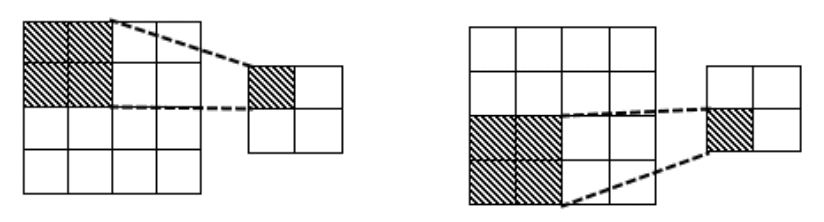
Рисунок 3 — Примеры шагов операции подвыборки изображения 4x4 матрицей 2x2
Полносвязные слои выполняют задачу классификации на основе данных о найденных признаках, полученных из предыдущих слоёв. Вместе с выходным слоем они работают по принципу многослойного перцептрона. Результатом работы полносвязных слоёв является вектор вероятностей принадлежности входного сигнала к каждому из классов.
Основной сферой применения свёрточных нейросетей является распознавание изображений (определения как одного, так и множества образов на сцене), но также они могут использоваться в других сферах, требующих комплексного распознавания признаков и классификации (таких, как распознавание текстов на естественных языках и определение диагнозов пациентов). Свёрточные сети могут объединяться с другими типами нейросетей для решения более сложных задач. Например, распознавание действий на видео или генерация голосового описания изображения решаются путём сложения свёрточной и рекуррентной сети.
Рекуррентные нейронные сети (recurrent neural networks, RNN) [5] содержат нейроны, которые способны сохранять входные данные для будущего использования. Такие сети способны определять зависимости между последовательными наборами входных сигналов, потому они идеально подходят для анализа любых сигналов, зависящих от времени. На практике они применяются для распознавания голоса, рукописного ввода, прогнозирования временных рядов, обработки естественных языков, перевода, распознавания эмоциональных оттенков и т.п.
Классические RNN анализируют каждый новый входной сигнал с учётом предыдущего. Такой подход достаточно прост и мало чем отличается от обыкновенных многослойных перцептронов в плане реализации, но при этом может происходить потеря контекста. Зачастую контекст, в котором необходимо распознавать текущий входной сигнал, может определяться множеством входных сигналов более ранних, чем предыдущий. Проблему запоминания долгосрочных зависимостей решают сети с долгой краткосрочной памятью (long short–term memory, LSTM). Существует множество вариаций LSTM–сетей, но в общем случае LSTM–нейроны содержат 3 вентиля: вентиль входа (определяет, насколько данные в памяти влияют на текущий вход), вентиль забытия (насколько вход влияет на данные в памяти) и вентиль выхода (насколько данные в памяти влияют на выход). Весовые коэффициенты этих вентилей настраиваются при обучении.
Нейросетевая библиотека Keras
Библиотека Keras [6] является высокоуровневым решением для создания нейронных сетей различных архитектур. Написанная на языке Python, Keras позиционируется как средство быстрого прототипирования и тестирования конфигураций нейросетей различной сложности, максимально упрощая процесс создания новых слоёв и их совмещения в единую модель.
При установке Keras необходимо установить back–end, который представляет собой более
низкоуровневую реализацию всех используемых возможностей нейросетей. Основными back–end–ами
являются TensorFlow и Theano, при этом разрабатывается поддержка других. По умолчанию Keras пытается
использовать TensorFlow, но в файле $HOME/.keras/keras.json (%USERPROFILE% вместо $HOME
при использовании ОС Windows)значение поля backend
можно установить в нужное. Также можно задать
новое значение переменной среды KERAS_BACKEND, тогда конфигурационный файл будет изменён
автоматически. Также Keras может автоматически использовать графические процессоры для ускорения
работы, если установлена поддерживающая это версия back–end–а. При написании кода можно как полностью
абстрагироваться от back–end–а, используя общий API, так и использовать специализированные функции
конкретного back–end–а.
Keras имеет две модели построения нейросети: последовательная (sequential) и функциональная (functional). Последовательная модель представлена классом Sequential (рис. 4). Эта функция в качестве аргументов принимает список слоёв нейронов. Также эту функцию можно вызвать без аргументов, а слои добавить с помощью функции add().

Рисунок 4 — Создание последовательной модели в Keras
При использовании функциональной модели каждый последующий слой после создания должен получить в качестве аргумента модели, построенной из предыдущих слоёв.
Первый слой модели должен также определить форму входных данных аргументом input_shape (например, для изображений размером 50x50 пикселей с тремя цветовыми каналами input_shape = (50, 50, 3) [7]). Для последующих слоёв модели этот параметр определяется автоматически, основываясь на количестве выходов предыдущих слоёв.
После создания модели она компилируется при помощи метода compile(), принимающего в качестве аргументов функцию потерь и оптимизатор; среди дополнительных параметров можно указать измеряемые метрики (рис. 5).

Рисунок 5 — Компиляция модели
Затем полученная сеть обучается при помощи метода fit(). Данный метод принимает в качестве аргументов некоторый входной сигнал и поставленный ему в соответствие желаемый выходной сигнал. Данные должны быть представлены в форме массивов NumPy. Среди дополнительных параметров можно указать, например, количество эпох.

Рисунок 6 — Обучение сети на случайно сгенерированных данных
После обучения нейронную сеть можно проверить с использованием метода evaluate(), передав в него входной и желаемый выходной сигнал; на выходе будет получена потеря и желаемые метрики. Для вычисления выходного сигнала на основе входа используется метод predict().
Примеры параметрического описания типовых нейросетей с использованием Keras
Простые свёрточные слои в библиотеке Keras представлены классами Conv1D, Conv2D и Conv3D, соответствующим одно–, двух– и трёхмерным обрабатываемым данным. Обязательными аргументами при создании этих слоёв являются filters (количество фильтров — свёрточных нейронов) и kernel_size (размерности ядра — матрицы весов). Параметр stride указывает, насколько смещается ядро при обходе матрицы входа (по умолчанию 1).
Параметр padding расширяет матрицу входа. Установка его значения в same
позволяет дополнять
матрицу входа нулями, чтобы размеры матрицы выхода были равны размерам матрицы входа. По умолчанию
его значение равно valid
, что соответствует отсутствию расширения. Аналогичного поведения можно
добиться, используя перед свёрточным слоем специальный слой ZeroPadding(1D, 2D, 3D), но при этом
количества ячеек, на которые матрица расширяется в каждом измерении и в каждом направлении, можно
задать вручную через аргумент padding.
Параметр activation задаёт функцию активации. По умолчанию функция активации в свёрточных слоях
линейная (linear
), т.е. выход равнозначен входу. В Keras уже встроено множество часто используемых
функций активации. В свёрточных сетях чаще всего используется функция ReLU (rectified linear unit,
выпрямленный линейный элемент), которая даёт достаточно точные результаты при своей низкой
ресурсозатратности (при отрицательных входах она передаёт 0, при положительных — сам вход). Также часто
используются гиперболический тангенс (tanh
) и сигмоида (sigmoid
). На практике вместо передачи
функции активации в качестве параметра свёрточной сети её выделяют в отдельный слой Activation. Также
существуют продвинутые слои активации, имеющие обучаемые элементы (LeakyReLU, PReLU, Softmax и
пр.).
Слои подвыборки, аналогично свёрточным слоям, имеют 1D, 2D и 3D–версии. Классы MaxPooling при обходе матрицы входа выбирают максимальные значения, AveragePooling — вычисляют средние. Параметр pool_size определяет размеры окна подвыборки (по умолчанию каждое измерение равно 2). У каждого подвыборочного класса есть Global–аналог (например, GlobalMaxPooling2D), который устанавливает размерами окна размеры исходной матрицы (т.е. на выходе получается единственное значение).
Параметр strides, аналогично свёрточным слоям, определяет шаг смещения окна подвыборки в каждом измерении (по умолчанию оно равно размерам окна подвыборки). Параметр padding работает так же, как и в свёрточных слоях. Подвыборочные слои в качестве функции активации всегда используют ReLU, поэтому параметр, который задаёт функцию активации, отсутствует.
Полносвязные слои представлены классом Dense. Обязательный параметр units описывает количество нейронов (и, соответственно, выходных сигналов) в слое. Параметр useBias указывает, стоит ли использовать вектор смещений (по умолчанию — True). Слои Dense всегда принимают одномерный входной сигнал, поэтому в свёрточных сетях, использующих более одного измерения, перед первым полносвязным слоем добавляется слой Flatten, преобразующий данные в одномерную форму.
На практике иногда нейронные сети могут переобучаться и становиться слишком требовательными к входным данным, отказываясь распознавать некоторые признаки даже при малейших отличиях входных данных от тренировочных. В случае возникновения этой проблемы на некоторых этапах обучения сети можно случайно отбрасывать [8] выходы нейронов, устанавливая их в 0. В библиотеке Keras этим занимается слой Dropout. Параметр rate слоя Dropout задаёт, какая доля нейронов будет случайно отброшена. Отброс осуществляется только на этапе обучения, при работе с реальными данными слой полностью игнорируется.
Заключение
Библиотека Keras является мощным инструментом для моделирования нейронных сетей. В библиотеке реализован широкий набор видов слоёв глубоких нейронных сетей, каждый из которых обладает широким спектром параметров для тонкой настройки. При этом количество обязательных параметров при настройке каждого слоя сведено к минимуму, а необязательные устанавливаются в наиболее часто используемые либо рассчитываются автоматически. Композиция слоёв проста, нет необходимости писать какой–либо код для передачи или адаптации данных между слоями. Использование в качестве языка программирования Python, ввиду его простоты в использовании, ёмкости и распространенности, позволяет даже малоопытным программистам решать трудноформализуемые задачи наподобие распознавания изображений.
Список литературы
- Искусственная нейронная сеть — Википедия [Электронный ресурс] — Режим доступа: https://ru.wikipedia.org/wiki/Искусственная_нейронная_сеть
- Deep Learning — Wikipedia [Электронный ресурс] — Режим доступа: https://en.wikipedia.org/wiki/Deep_learning
- Джулли, А, Пал С. Библиотека Keras — инструмент глубокого обучения. Реализация нейронных сетей с помощью библиотек Theano и TensorFlow / пер. с англ. Слинкин А.А. — М.: ДМК Пресс, 2018 — c.101.
- Сверточная нейронная сеть, часть 1: структура, топология, функции активации и обучающее множество — Хабр [Электронный ресурс] — Режим доступа: https://habr.com/post/348000/
- Рекуррентные нейронные сети: типы, обучение, примеры и применение — Neurohive [Электронный ресурс] — Режим доступа: https://neurohive.io/ru/osnovy-data-science/rekurrentnye-nejronnye-seti/
- Keras: The Python Deep Learning library [Электронный ресурс] — Режим доступа: https://keras.io/
- Keras input explanation: input_shape, units, batch_size, dim, etc — Stack Overflow [Электронный ресурс] — Режим доступа: https://stackoverflow.com/questions/44747343/keras-input-explanation-input-shape-units-batchsize-dim-etc
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting [Электронный ресурс] — Режим доступа: https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf