Аннотация
Сторожук Н.О., Коломойцева И.А. - Реализация прототипа анализатора жанровой принадлежности произведений на основании векторно – пространственной модели представления документов В работе представлено описание прототипа программной системы, реализующей анализ жанровой принадлежности документа с использованием векторно–пространственной модели. Приведен алгоритм работы программы, выполнен анализ результатов, на основании которого сделаны выводы о недостатках построенной модели, определены последующие направления работы.
Общая постановка проблемы
Поиск семантического сходства между текстами является серьёзной проблемой для автоматической обработки текста. Необходимость поиска расстояния между документами возникает в различных задачах, таких как обнаружение плагиата, определение авторства документа, поиск информации, машинный перевод, формирование тестов и задач, автоматическое построение рефератов и пр. Близка к классификации задача рубрицирования текста – его отнесение к одной из заранее известных тематических рубрик или жанру.
Целью данной работы является обоснование выбора модели представления документов в системе, описание программной реализации прототипа программы, определяющей жанровую принадлежность документа, анализ результатов и формирование направлений дальнейшей работы.
Анализ основных моделей информационного поиска
Полнотекстовый поиск документов в больших массивах документов, проводится обычно на основе их поисковых образов, под которыми понимается набор ключевых слов – слов, отражающих основную тему документа. В качестве ключевых слов можно рассматривать отдельные слова, словосочетания, однако в силу особенностей русского языка (наличия склонений и различных словоформ) такие методы не являются приемлемыми. Запрос на поиск можно представить в виде набора слов, тогда подходящие документы можно определить на основе похожести запроса и поискового образа документа. Создание поискового образа документа предполагает индексирование его текста, т.е. выделение в нем ключевых слов.
В основу традиционных методов поиска положены три главных подхода, первый из которых базируется на теории множеств (булева модель), второй — на векторной алгебре (векторно-пространственная модель), а третий — на теории вероятностей (вероятностная модель). Эти подходы могут применяться на практике и в каноническом виде, однако у них есть общий недостаток, обусловленный предположением, что содержание документа определяется множеством слов и устойчивых словосочетаний — термов, которые входят в него без учета взаимосвязей, как «мешок слов», и, более того, считаются независимыми. Такое предположение ведет к потере содержательных оттенков, тем не менее, оно позволяет реализовать поиск и группирование документов по формальным признакам.
Классическая булева модель базируется на теории множеств и математической логике. Популярность этой модели связана, прежде всего, с простотой ее реализации, которая позволяет индексировать и выполнять поиск в больших документальных массивах [1, c. 34].
В рамках булевой модели документы и запросы представляются в виде множества термов — ключевых слов и устойчивых словосочетаний. Каждый терм представлен как булева переменная: 0, если данный терм из запроса отсутствует в документе, или 1 в противном случае. При этом весовое значение терма в документе принимает лишь два этих значения и число повторов терма в документе и их местоположение не учитывается.
В булевой модели запрос пользователя представляет собой логическое выражение, в котором термы связываются логическими операторами конъюнкции, дизъюнкции и отрицания. Так как любое логическое выражение можно представить дизъюнкцией некоторых выражений, соединенных между собой операцией конъюнкции (дизъюнктивной нормальной формой), то для любого запроса можно выполнить ряд операций поиска по каждому слову запроса и выполнить необходимые логические операции, представленные выше.
На основании этой информации можно перечислить следующие недостатки булевой модели:
- отсутствие весовых и частотных различий использованных термов, что не предоставляет возможности в дальнейшем классифицировать и ранжировать ряд документов по их уровню соответствия булевой модели запроса;
- отсутствие контекстных операторов, невысокая эффективность поиска;
- алгоритмическая необходимость хранения исходных документов, таблиц с булевыми значениями для термов и документов, инверсной таблицы и прочей вспомогательной информации большого объема.
Усовершенствованная булева модель устраняет первые два недостатка введением показателя частоты встречаемости документа, которая нормируется с помощью деления частоты текущего терма в документе на максимальную частоту. Тогда близость между двумя документами можно определить как нормированное расстояние между частотами соответствующих термов. Если предположить, что в запросе каждый терм также имеет какой-то вес, то модель усложняется представлением запроса в рамках булевой модели и усложнением вычислительной сложности получения результата. Кроме того, такая модель усугубляет объем хранимой информации.
В вероятностной модели поиска вероятность того, что документ соответствует запросу, основывается на предположении, что термы запроса по-разному распределены среди релевантных и нерелевантных документов. При этом используются формулы расчета вероятности, базирующиеся на теореме Байеса.
Основной вопрос, который решается с помощью модели: как велика вероятность того, что документ d релевантен запросу q? Релевантность в данном случае рассматривается как вероятность того, что данный документ может оказаться подходящим для пользователя. Функционирование модели основывается как на экспертных оценках, получаемых в результате обучения модели, которые признают документы из учебной коллекции релевантными/нерелевантными, так и на последующих оценках вероятности того, что документ является релевантным запросу, исходя из состава его термов.
Вероятностная модель поиска предполагает вычисление вероятности соответствия запросу документов из множества, сортировку результатов по релевантности. Следует отметить, что в вероятностной модели поиска предполагается наличие учебных наборов релевантных и нерелевантных документов, показатели которых определяются экспертами, или полученных автоматически при каком-то начальном предположении. Вероятность того, что поступивший документ является релевантным, рассчитывается на основании соотношения появления термов в релевантном и нерелевантном массиве документов.
В случае применения экспертных оценок процесс поиска является итерационным: на каждом шаге итерации, благодаря режиму обратной связи, определяется множество документов, отмеченных пользователем как удовлетворяющих его информационным потребностям.
Недостатками векторной модели являются:
- низкая вычислительная масштабируемость (существенное снижение эффективности при росте объемов данных);
- высокая вычислительная сложность;
- необходимость постоянного задействования узкоспециализированых экспертов для подготовки обучающего множества.
Другой подход к анализу текстов – использование векторно–пространственной модели - предполагает выявление схожести документов на основании пропорций вхождения слов в каждый из документов. Для подготовки данных для использования этого подхода используется метод под названием «мешок слов». Его суть состоит в том, что для дальнейшего анализа важно число вхождения конкретных слов, а не морфологически формы слов и их порядок в документе.
В данной модели документ описывается вектором в евклидовом пространстве, в котором каждому терму, использующемуся в документе, ставится в соответствие его весовое значение, определяемое на основе статистической информации о его появлении как в отдельном документе, так и во всем документальном массиве. Описание запроса, соответствующего необходимой пользователю тематике, также представляет собой вектор в том же евклидовом пространстве термов.
Предположим, что каждый документ можно охарактеризовать определенным набором слов и частотой их появления. Тогда при условии, что если в документе конкретный набор слов употребляется с определенными частотами, то этот документ отвечает требованиям этого запроса. На основании этой информации строится таблица «слово-документ», где строки соответствуют терминам, а столбцы – исследуемым документам. В каждой ячейке может храниться булево значение, которое показывает наличие хотя бы одного вхождения термина в документ, частота слова в документе или вес термина [2, с. 143]. Теперь, для того чтобы сравнить документ d и запрос q, нужно определить меру схожести двух столбцов таблицы.
В рамках этой модели каждому терму ti документе dj соответствует некоторый неотрицательный вес wj. Каждому запросу q, который представляет собой множество термов, не соединенных между собой никакими логическими операторами, также соответствует вектор весовых значений wij.
При этом вес отдельных термов можно вычислять разными способами. Один из возможных простейших подходов – использование нормализованной частоты появления терма в документе (см. формулу 1):

где freq_i^j – число употребления терма в документе.
Такой показатель веса терма в документе обозначают аббревиатурой tfj (от английского term frequency – частота термина). Однако этот подход не учитывает, насколько часто рассматриваемый терм используется во всем массиве документов, иными словами - дискриминационную силу терма. Поэтому в случае, когда доступна статистика использования термов во всем документальном массиве, более эффективно следующее правило вычисления веса (см. формулу 2):

где ni – количество документов, в которых используется терм ti,
N - общее количество документов в массиве.
Следует отметить, что основание логарифма может быть любым, для простоты чаще всего используют 2 или 10. Приведенная выше формула многократно уточнялась с целью наиболее точного соответствия выдаваемых документов запросам пользователей. В 1988 году Солтоном был предложен такой вариант для вычисления веса терма ti из запроса в документе, представленный в формуле 3 [3, с.41]:
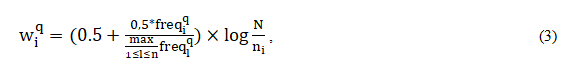
где freqiq – частота терма ti из запроса в тексте этого документа.
Использование такого показателя позволяет усилить отличие термина, если он встречается часто в небольшом количестве документов и уменьшить значение термина и релевантность документа, если термин встречается во многих документах или используется всего несколько раз.
Векторно-пространственная модель представления данных обеспечивает системам, построенным на ее основе, следующие возможности:
- обработку запросов без ограничений их длины;
- простоту реализации режима поиска подобных документов (каждый документ может рассматриваться как запрос);
- сохранение результатов поиска с возможностью выполнения уточняющего поиска;
- возможность установки дополнительных весовых коэффициентов для усовершенствования более узконаправленного поиска и анализа сходства документов [4].
Вместе с тем в векторно-пространственной модели не предусмотрено использование логических операций в запросах, что определенным образом ограничивает ее применимость.
Описание прототипа программной системы
Рассмотрим этапы работы программной модели анализатора документов (см. рис.1). Для разработки прототипа системы и тестирования её работы, цель которой состоит в определении принадлежности документа к некоторому литературному жанру, были выбраны 2 жанра – детектив и любовный роман, подобрано по 5 книг каждого жанра. По нажатию на кнопку в систему загружается 6 файлов – первый файл является запросом, ещё 5 – предварительно отобранные файлы одного жанра. Программный модуль, отвечающий за лексический анализ, запускается в первую очередь и готовит данные для последующих этапов анализа. Основная задача лексического анализа - распознать лексические единицы текста, удалить стоп-слова и привести их к единому представлению с помощью стемминга. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Наборы стоп-слов могут быть разными и зависеть от целей и задач исследования. В данном случае используется список стоп-слов, состоящий из частиц, предлогов и некоторых местоимений. По результатам собственных исследований, удаление стоп-слов отсекает в среднем 30% слов (см. рис.2), что ускоряет дальнейшую обработку данных и повышает точность результатов.
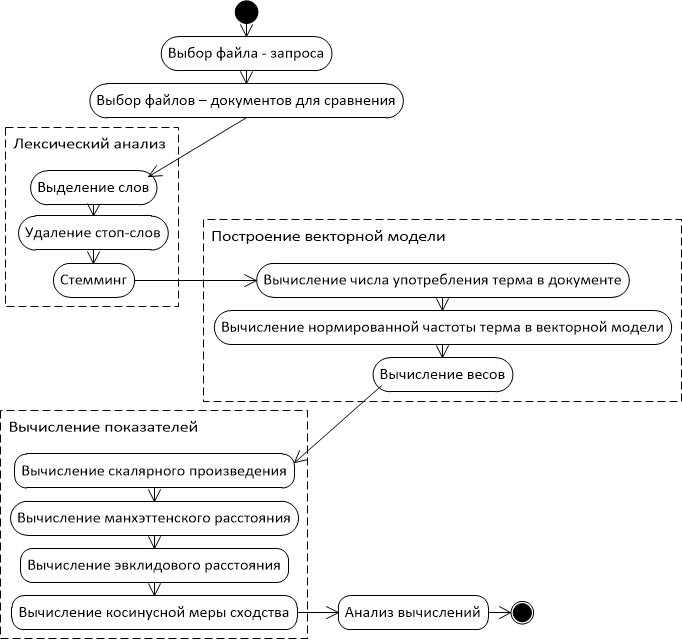
В процессе доработки программной модели и дальнейшего анализа полученных токенов метод первичной обработки текста будет усовершенствован на основании экспериментальных данных.
Далее все 6 файлов преобразуются в векторно–пространственную модель согласно описанию выше, т.е. в список весов термов в каждом документе. На данном этапе разработки вычисление весов происходит по формуле Солтона (см. формулу 3), которая предполагает расчет весов одинаково для всех термов. Однако для последующего определения жанровой принадлежности следует выделить термы, которые имеют наибольший вес в интересуемом жанре и присутствуют в произведениях другого в минимальном количестве, либо отсутствуют вообще. С этой целью программа сохраняет промежуточные результаты работы для дальнейшего анализа. Так как готовых словарей или прочих вспомогательных материалов инженерного либо литературного характера не найдено, возникла необходимость анализировать данные самостоятельно, т.е. проводить экспертное оценивание. В дальнейшем будет разработан вспомогательный инструмент, анализирующий веса и термы на базовом, «грубом» уровне, на основании полученных им данных будет произведены элементы ручной обработки списка.
Для определения жанровой принадлежности текста в реализовываемом прототипе программной системы был разработан анализатор близости загружаемого документа к документам, жанровая принадлежность которых уже определена. С этой целью была использована векторно–пространственная модель, как наиболее подходящая для решения поставленной задачи. Для определения близости документов были использованы 4 наиболее популярных показателя:
- скалярное произведение векторов;
- евклидово расстояние;
- манхэттенское расстояние;
- метод косинусной меры сходства.
Анализируя эти методы, следует обратить внимание, что значения схожести по евклидовому и манхэттенскому методам на самом деле являются расстояниями между векторами. Таким образом, чем расстояние меньше, тем более документ схож с запросом. Методы, использующие скалярное произведение и косинусные показатели, в результате возвращают именно сходство, то есть наилучший документ тот, который имеет наибольший показатель сходства. Весомым недостатком методов манхэттенского расстояния и евклидового расстояния является полный перебор векторов и вычисление расстояний даже для нулевых точек, что несет за собой увеличение требований к производительности.
Одна из причин популярности косинусного сходства состоит в том, что оно эффективно в качестве оценочной меры, особенно для разреженных векторов, так как необходимо учитывать только ненулевые измерения [5]. На основании проделанных расчетов и анализа описанных методов, основанных на векторной модели, лучшим методом для определения близости документов был определен метод косинусного сходства (см. рис. 2).
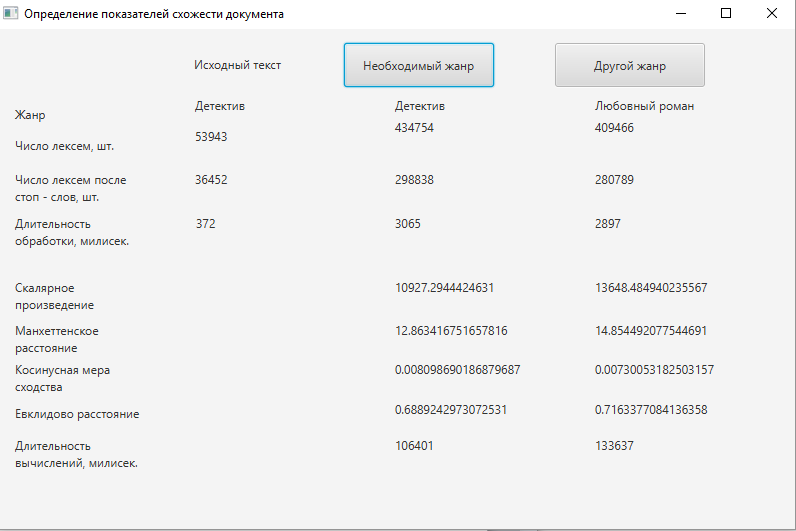
Так как показатели расстояний между запросом и документами численно меньше у выборки детективного жанра, а значения скалярного произведения и косинусной меры сходства наоборот, больше, можно сделать вывод, что исследуемый документ детективного жанра. Однако разительной разницы заметить не удастся – выбранная для дальнейшего исследования косинусная мера сходства в общем случае принадлежит промежутку [0, 1], т.е., чем ближе значение к единице, тем более вероятно, что жанр определен верно.
Следовательно, показатели в 0,0081 и 0,0073 являются недостаточно весомыми, чтобы с уверенностью классифицировать выбранный текст. Для того, чтобы считать документ принадлежащим к определенному жанру, следует максимально приблизить показатель косинусной меры к единице, следовательно, необходимо доработать систему.
Выводы
В статье представлен обзор моделей представления документов для последующего анализа, описание прототипа программной системы, установлены основные направления работы в рамках дальнейшей работы. На данном этапе разработки были выявлены следующие недостатки программной системы:
- высокая продолжительность первичной обработки текстов;
- низкие показатели схожести документов, релевантность которых определена на основе экспертных оценок;
- методы манхэттенского и евклидового расстояния требуют большей временной и вычислительной сложности;
- отсутствует возможность дообучения, то есть дополнения обучающей выборки документами, которые в результате программного анализа были определены как принадлежащие к выбранному жанру;
- требуется выполнять загрузку обучающей выборки каждый раз в начале работы программы.
В связи с этим следует исследовать следующие направления работы:
- доработать первичную обработку документов посредством удаления личных имен, названий населенных пунктов, других малозначащих конструкций;
- использовать распараллеливание в процессе обработки документов;
- использовать для определения схожести документов метод косинусного сходства;
- использовать для определения схожести документов метод косинусного сходства;
- разработать методологию сохранения результатов анализа для последующего обучения модели;
- увеличить число обучающей выборки минимум до 100 книг выбранного жанра;
- с помощью экспертов выполнить анализ весов часто употребляемых термов в документах определенного жанра, повысить степень их влияния на конечное вычисление схожести документов.
Список использованной литературы
- Ландэ, Д. В. Интернетика: Навигация в сложных сетях: модели и алгоритмы / Д. В. Ландэ, А. А. Снарский, И. В. Безсуднов. – Москва : М.: Книжный дом «ЛИБРОКОМ», 2009. – 264 с.
- Маннинг, К.Д. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с.
- Salton G., Fox E., Wu H. Extended Boolean information retrieval. Communica- tions of the ACM. 2001./ G.Salton, E,Fox, H.Wu.- Vol. 26. № 4. P. 35–43.
- Векторно-пространственная модель поиска [Электронный ресурс] / Д.В.Ландэ [и др.] // Информатика. – Электрон. дан. 2015. Режим доступа: https://pidruchniki.com/71826/informatika/zadachi_poiska_setyah#42
- Сторожук, Н. О. Анализ методов определения текстовой близости документов / Н. О. Сторожук, И. А. Коломойцева // Материалы студенческой секции IX Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2018). – Донецк: ДонНТУ, 2018. – С. 43-47.