Анализ существующих алгоритмов классификации текстов и их применение в экономически ориентированных системах
М.Г. Титаренко, И.А. Коломойцева
Материалы студенческой секции IX Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2018). – Донецк: ДонНТУ, 2018.
М.Г. Титаренко, И.А. Коломойцева Анализ существующих алгоритмов классификации текстов и их применение в экономически ориентированных системах. Представлен анализ существующих алгоритмов классификации, используемых в современных информационно-поисковых системах экономического характера. Определен алгоритм с наивысшей чувствительностью для классификации экономических текстов.
Классификация текстов является составляющей частью информационно – поисковой системы. Задачей классификации - соотнесение текста, документа с одной из нескольких определенных категорий. Для осуществления автоматической классификации применяются множество методов и алгоритмов, которые дают различную степень точности результатов на разных наборах тестовых данных.
В связи с необходимостью дальнейшей работы над разработкой информационно-поисковой системы в области внешнеэкономических связей между государствами, было принято решение проанализировать результаты исследований по эффективности работы базовых алгоритмов классификации на общих наборах тестов, а также на наборах, связанных с экономической деятельностью.
Целью данной работы является анализ существующих алгоритмов классификации тестов, которые могут быть использованы в информационно-поисковых системах, ориентированных на сбор и анализ экономической информации.
Согласно исследованию [1] алгоритмы классификации делятся на 3 семейства: индивидуальные классификаторы, гомогенные ансамбли и гетерогенные ансамбли.
Индивидуальные текстовые классификаторы – это методы классификации текстов, которые не требуют взаимодействия этих методов с другими. Одними из представителей данного семейства являются алгоритмы: CART, k-ближайших соседей, наивный байесовский алгоритм, SVN и другие.
Гомогенные ансамбли представляют собой набор классификаторов, которые объединяют прогнозы нескольких базовых моделей. Множество исследований показали, что при таком подходе увеличивается процент успешных прогнозов со стороны классификаторов [2]. Главной особенностью таких моделей является то, что они расширяют и дополняют базовые модели, используя те же алгоритмы классификации. Представителями гомогенных ансамблей являются: альтернативное дерево принятия решений, Random forest, Boosted decision trees и другие.
Гетерогенные ансамбли также объединяют несколько классификационных моделей, но создаются уже с использованием различных алгоритмов классификации. В себе они объединяют индивидуальные классификаторы и, в отдельных случаях, гомогенные ансамбли. Идея гетерогенных ансамблей состоит в том, что разные алгоритмы имеют разные представления о одних и тех же данных и могут дополнять друг друга. Именно гетерогенные ансамбли являются наиболее перспективным видом классификационных моделей [3]. Представителями гетерогенных ансамблей являются: Hill-climbing ensemble selection, HCES with bootstrap sampling, k-nearest oracle и другие.
Исходя из вышенаписанного, на сегодняшний день для обеспечения универсальной классификации данных одним из лучших вариантов будет являться гомогенный ансамбль или гетерогенный ансамбль с анализом наибольшей точности при классификации универсальной тематики. Однако для обеспечения наибольшей точности в специфической сфере наилучшим образом себя показывает гетерогенный ансамбль с методами, подобранными для специфической задачи.
Основными составными частями этих трех семейств являются индивидуальные классификаторы, поэтому в данной статье будут рассмотрены некоторые из алгоритмов индивидуальной классификации.
Опираясь на исследование [4], проведем анализ базовых алгоритмов SVM, KNN и NB.
Машина опорных векторов (SVM) принимает набор данных, состоящий из чисел, и пытается спрогнозировать, в какую категорию он попадает. Машина опорных векторов находит линию, наилучшим образом разделяющую данные. Это означает, что она проходит на максимальном расстоянии от расположенных вблизи нее точек. Для определения того, где должна пройти линия, необходимы лишь ближайшие к ней точки, они и называются опорными векторами. Благодаря этому методу обеспечивается высокая обобщающая способность [5].
Рассмотрим результаты исследования по этому методу для классификации экономических текстов. В качестве критериев были выбраны IG и критерий Фишера.
Согласно данным исследования [4] при использовании критерия Фишера данный метод показывает параметры чувствительности на уровне 60%, 72%, 73% на выборках уровня 1000, 5000 и 10000 соответственно. На критерии IG (Information Gain) зафиксирована чувствительность уровня 66%, 74%, 75%. А по исследованию [6] на критерии распределения хи-квадрат выявлена чувствительность 83% на уровне выборки 13000.

Основой метода ближайшего соседа является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Для классификации текста в данном методе в качестве объектов выбираются слова, предложения и абзацы, которые уже определены в данном тексте. Так, если первый и третий абзацы текста имеют экономический стиль, то скорее всего и второй абзац также относится данному стилю.
Для метода ближайших соседей существуют теоремы, утверждающие, что на бесконечных
выборках это оптимальный метод классификации.
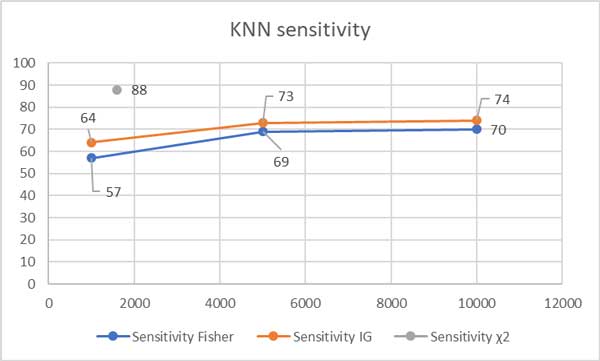
Рассмотрим результаты исследования по этому методу для классификации экономических текстов. В качестве критериев остаются IG и критерий Фишера.
Согласно данным исследования [4] при использовании критерия Фишера данный метод показывает параметры чувствительности на уровне 57%, 69%, 70% на выборках уровня 1000, 5000 и 10000 соответственно. На критерии IG (Information Gain) зафиксирована чувствительность уровня 64%, 73%, 74%.
Следуя исследованию [7] на критерии распределения хи-квадрат выявлена чувствительность к экономическим текстам в 88% на уровне выборки 1600.
Цель классификации состоит в том, чтобы понять к какому классу принадлежит документ, поэтому нужна не сама вероятность, а наиболее вероятный класс. Байесовский классификатор использует оценку апостериорного максимума для определения наиболее вероятного класса.
То есть надо рассчитать вероятность для всех классов и выбрать тот класс, который обладает максимальной вероятностью.
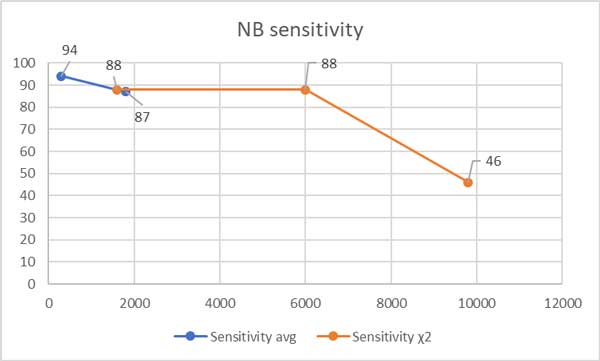
Согласно данным исследования [7] при использовании критерия хи-квадрат метод показывает параметры чувствительности на уровне 88%, 88%, 46% на выборках уровня 1600, 6000 и 9800 соответственно.
Из исследования [8] усредненная по критериям чувствительность к текстам в 87% на уровне выборки 1800, а к экономическим текстам – 94% на уровне выборки 300.
Описанные выше алгоритмы были реализованы и протестированы на наборе статей агентства Рейтерс, которые уже были предварительно классифицированы. Для обучающей выборки были отобраны 471 статья. Тестовый набор составил 9420 статей. В качестве признаков были выбраны доля экономических терминов, коэффициент связности экономических словосочетаний, а также доля числовых данных с привязкой к денежному знаку.
Для определения уровня доверия результатов был использован принцип Парето, то есть при вероятности 80% и больше текст считается принадлежащим к установленной категории.
В качестве критериев были выбраны IG (Information Gain), критерий Фишера и хи-квадрат.
Согласно полученным данным по алгоритму SVM на критерии Фишера чувствительность составила 57%, по IG - 71%, и по хи-квадрат – 81%. По алгоритму KNN: Фишер – 64%, IG – 67%, хи-квадрат - 76%. По алгоритму NB: Фишер – 72%, IG – 88%, хи-квадрат - 78%. Эти данные представлены на рисунке 4.

Для более удобного сравнения усредним отобранные результаты по среднему геометрическому. Так, для SVM чувствительность составляет 70.75%, для KNN - 69.76%, а для NB - 78.48%. Таким образом, согласно исследованиям, наиболее точным является байесовский классификатор.

Был проведен анализ базовых алгоритмов классификации, выявлены значения средней чувствительности алгоритмов SVM, KNN и NB. Установлено, что NB - наиболее чувствительный алгоритм для классификации экономических текстов на основе результатов исследований и собственного по заранее определенных признаков.
- Stefan Lessmann. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research / Stefan Lessmann, Bart Baesens, Hsin-Vonn Seow, Lyn C. Thomas // European Journal of Operational Research. – 2015. – Volume 247, Issue 1. – С.124-136.
- Zeynep Hilal Kilimci. The effectiveness of homogenous ensemble classifiers for Turkish and English texts / Zeynep Hilal Kilimci, Selim Akyokus, Sevinc Ilhan Omurca // INnovations in Intelligent SysTems and Applications (INISTA). – 2016.
- Suppawong Tuarob. An ensemble heterogeneous classification methodology for discovering health-related knowledge in social media messages / Suppawong Tuaroba, Conrad S.Tuckerba, Marcel Salathec, Nilam Ramd // Journal of Biomedical Informatics. – 2014. – Volume 49. – С. 255-268.
- Wen Li. Two-level hierarchical combination method for text classification / Wen Li, Duoqian Miao, Weili Wang // Expert Systems with Applications. – 2011. – Volume 38, Issue 3. – С. 2030-2039.
- Corinna Cortes. Support-vector networks / Corinna Cortes, Vladimir Vapnik // Machine Learning. – 1995. – Volume 20, Issue 3. – С. 273–297.
- Grazyna Suchacka. Classification of E-Customer sessions based on support vector machine / Grazyna Suchacka, Magdalena Skolimowska-Kulig, Aneta Potempa // ECMS 2015. – 2015.
- Shengyi Jiang. An improved K-nearest-neighbor algorithm for text categorization / Shengyi Jiang, Guansong Pang, Meiling Wu, Limin Kuang // Expert Systems with Applications. – 2012. – Volume 39, Issue 1. – С. 1503-1509.
- Li Dan. Research of Text Categorization on WEKA / Li Dan, Liu Lihua, Zhang Zhaoxin // Intelligent System Design and Engineering Applications (ISDEA). – 2013.