Обзор и анализ алгоритмов для осуществления бинарной классификации информации о внешнеторговой деятельности государств
М.Г. Титаренко, И.А. Коломойцева
Материалы международной научно-практическаой конференции «Программная инженерия: методы и технологии разработки информационновычислительных систем» (ПИИВС-2018) – Донецк: ДонНТУ, 2018.
М.Г. Титаренко, И.А. Коломойцева Обзор и анализ алгоритмов для осуществления бинарной классификации информации о внешнеторговой деятельности государств. Представлен анализ существующих алгоритмов классификации, выполнен отбор признаков и тестовых данных, произведено тестирование классификаторов, их оценка и сравнение результатов по бинарной классификации внешнеторговой информации.
В современном мире в интернете ежедневно появляется огромное количество новостных заголовков о внешнеторговой деятельности государств, однако часто эти статьи, заметки и обзоры представляются пользователю общим списком, который, обычно отсортирован по времени добавления и не позволяет оценить полезность информации, действительно ли она соответствует искомой категории. В связи с этим, возникает необходимость автоматической классификации внешнеторговой информации. Данная работа является актуальной для информационно-поисковых систем, направленных на поиск и обработку информации по международной торговле.
В статье приведен обзор алгоритмов классификации информации и их сравнение при работе с данными по внешнеторговой экономической деятельности государств.
Любая классификация производится на основе каких-либо признаков. Для того чтобы классифицировать текст прежде всего необходимо определить значения выбранных признаков для этого текста. На сегодняшний день одной из наиболее эффективных для автоматического определения необходимых признаков является TF-IDF мера [1]. TF-IDF - cтатистическая мера, которая используется для оценки значимости слова в документе, который является частью набора документов. Вес слова пропорционален частоте его употребления в документе и обратно пропорционален частоте его употребления во всем наборе (документах). Количество признаков было выбрано 10 произвольно, однако при его выборе учитывалось изменение f1 метрики на более высоких показателях данного параметра.
Для тестирования алгоритмов классификации решено использовать набор классифицированных статей от reuters в количестве 10788 штук, из которых 7769 приходятся на обучающую выборку и 3019 – на тестируемую. Статьи классифицированы на 90 категорий. В исследовании реализован бинарный классификатор статей по внешнеторговым признакам, поэтому остальные 89 категорий были помечены, как «other».
В качестве классификаторов в исследовании выбраны следующие алгоритмы: SVM (support vector machine), KNearestNeighbours, Гауссов классификатор, Деревья решений, классификатор RandomForest и Наивный Байесовский классификатор.
SVM (support vector machine) - набор алгоритмов классификации, которые переводят полученные исходные векторы в пространство большей размерности и находят разделяющую гиперплоскость, которая разделяет представленные классы [2].
В исследовании проводилось тестирование данного классификатора на разных показателях вводимого ядра, гаммы и параметр штрафа. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 1.
| Пар-ры | Precision | Recall | F1 |
|
kernel = "linear",
C = 0.025
|
0.924 | 0.9612 | 0.9423 |
| gamma = 2, C = 1 | 0.9578 | 0.9626 | 0.946 |
| gamma = 3, C = 1 | 0.9522 | 0.9626 | 0.9477 |
Согласно полученным данным третье значение является оптимальным согласно F1 - мере. В дальнейшем сравнении будут использованы данные по этим параметрам.
В основе алгоритма ближайших соседей (kNN) лежит правило, что тестируемый объект со своим набором признаков принадлежит классу, которому принадлежат большинство из k его ближайших соседей [3].
В исследовании проводилось тестирование данного классификатора на разных показателях вводимого k, а именно на 3-х, 5-ти и 10-ти соседях. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 2.
| k | Precision | Recall | F1 |
| 3 | 0.946 | 0.9559 | 0.95 |
| 5 | 0.9494 | 0.9603 | 0.9527 |
| 10 | 0.9528 | 0.9566 | 0.9498 |
Согласно полученным данным значение кол-ва соседей 5 является оптимальным согласно F1 - мере. В дальнейшем сравнении будут использованы данные по этому параметру.
Основная идея гауссовского классификатора заключается в предположении того, что функция правдоподобия (тренировочный набор) известна для каждого класса и равна плотности гауссовского нормального распределения [4].
В исследовании проводилось тестирование данного классификатора на разных показателях вводимого аргумента радиально-базисной функции. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 3.
| RBF(x) | Precision | Recall | F1 |
| 1.0 | 0.924 | 0.9612 | 0.9423 |
| 0.5 | 0.924 | 0.9612 | 0.9423 |
| 1.5 | 0.924 | 0.9612 | 0.9423 |
Согласно полученным данным значение RBF слабо влияет на показатели согласно F1 - мере.
Дерево решений – классификатор, который на тренировочных данных выстраивает структуру, узлам которого являются атрибуты различий, в листьях записаны атрибуты целевой функции, а на ребрах – необходимое множество атрибутов. Задача дерева решений – создать модель, которая предсказывает значение целевой функции на основе нескольких входов [4].
В исследовании проводилось тестирование данного классификатора на разных показателях вводимого аргумента максимальной глубины дерева. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 4.
| max | Precision | Recall | F1 |
| 5 | 0.9458 | 0.9573 | 0.9501 |
| 10 | 0.9421 | 0.9523 | 0.9465 |
| 15 | 0.943 | 0.95 | 0.9462 |
Согласно полученным данным глубина дерева 5 является оптимальным согласно F1 - мере. В дальнейшем сравнении будут использованы данные по этому параметру.
RandomForest – это алгоритм машинного обучения, который заключается в использовании гомогенного ансамбля деревьев решений. Основная идея состоит в использовании большого ансамбля деревьев решений, который за счет их большого количества улучшает результат классификации [5].
В исследовании проводилось тестирование данного классификатора на разных показателях вводимого аргумента максимальной глубины дерева. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 5.
| max | Precision | Recall | F1 |
| 5 | 0.924 | 0.9502 | 0.9487 |
| 10 | 0.9606 | 0.9626 | 0.9612 |
| 15 | 0.9419 | 0.953 | 0.9527 |
Согласно полученным данным глубина дерева 10 является оптимальным согласно F1 - мере. В дальнейшем сравнении будут использованы данные по этому параметру.
В основе наивного Байесовского классификатора лежит теорема Байеса. Данный классификатор стал одним из стандартных универсальных методов классификации. Достоинством данного классификатора является относительно небольшое количество данных, необходимых для обучения [6].
В исследовании проведено тестирование данного классификатора. При этом были рассчитаны метрики точности, полноты и f1 метрика. Результаты приведены в таблице 6.
| Precision | Recall | F1 |
| 0.9551 | 0.6568 | 0.7602 |
После проведения тестирования выполнен сравнительный анализ классификаторов по точности, полноте и f1 мере. В связи с тем, что была использована достаточно большая коллекция тренировочных документов, а также благодаря использованию алгоритма отбора признаков TF-IDF, полученные результаты отличаются достаточно незначительно и все имеют хорошие показатели распознавания текстов с внешнеторговой международной информацией. Исключение составляет лишь наивный Байесовский алгоритм, который показал уровень F1 в 0.7602, что не является удовлетворительным результатом для бинарной классификации. Результаты сравнения представлены на рисунке 1. По взвешенной оценке, наилучшим образом себя показал гомогенный ансамбль RandomForest на глубине дерева 10.
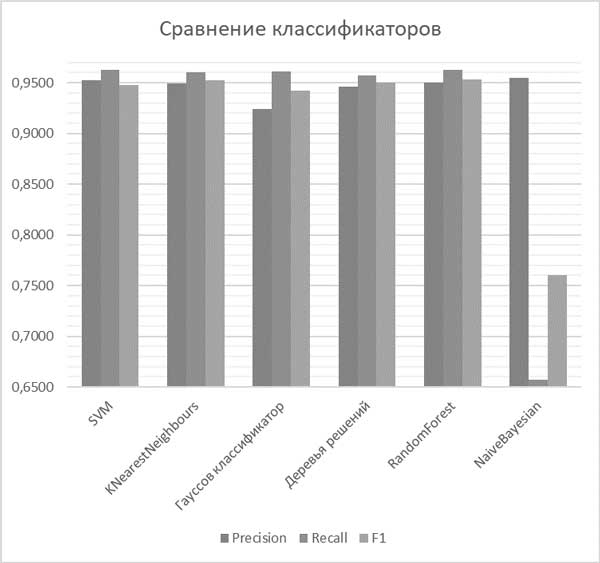
Проведен анализ алгоритмов классификации, таких как SVM (support vector machine), KNearestNeighbours, Гауссов классификатор, Деревья решений, классификатор RandomForest и Наивный Байесовский классификатор. Реализован алгоритм отбора и отобраны признаки классификации по TF-IDF. Проведено тестирование алгоритмов с различными параметрами по тренировочным и тестовым данным, определены оптимальные параметры для каждого алгоритма на основании оценки F1 меры. Проведено сравнение алгоритмов сравнением оптимального значения F1 меры, полноты и точности для каждого из них. Гомогенный ансамбль RandomForest установлен, как оптимальный классификатор для бинарной классификации внешнеторговой информации. Установлены неудовлетворительные результаты классификации наивным Байесовским классификатором.
- Salton, G. and Buckley, C. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 1988
- Nello Cristianini, John Shawe-Taylor An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. — Cambridge University Press, 2000
- Brett Lantz Machine Learning with R. Pack Publishing. Birmongham-Mumbai, 2013
- Breiman, Leo; Friedman, J. H., Olshen, R. A., & Stone, C. J. Classification and regression trees. Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software, 1984
- Hastie, T., Tibshirani R., Friedman J. Chapter 15. Random Forests // The Elements of Statistical Learning: Data Mining, Inference, and Prediction. — 2nd ed. — Springer-Verlag, 2009. — 746 с.
- Hand, DJ, & Yu, K. «Idiot’s Bayes — not so stupid after all?» International Statistical Review, 2001. - с 385—399.
- Е.И. Большакова Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб. пособие / Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. — М.: МИЭМ, 2011. — 272 с.