Analysis of existing methods of classification of information and its application in the system GrabTheTrade
M.G. Titarenko, I.A. Kolomoytseva, R.R. Gilmanova
Материалы V Международной научно-технической конференции «Современные информационные технологии в образовании и научных исследованиях» (СИТОНИ-2017). – Донецк: ДонНТУ, 2017
M.G. Titarenko, I.A. Kolomoytseva, R.R. Gilmanova Analysis of existing methods of classification of information and its application in the system "GrabTheTrade". The analysis of existing classification algorithms used in modern information retrieval systems is presented. Classification methods that can be used in the GrabTheTrade
information system are defined..
Classification is an important part of any information retrieval system. To date, there are several basic approaches to classification and many options for implementing these approaches. Not all classification algorithms provide the same level of correctness of results and, usually, have their own scope. In this regard, it was decided to consider, within the framework of this article, the approaches that are used in modern information retrieval systems.
In the information system GrabTheTrade
, which is working on collecting and analyzing trade and political information, it is planned to develop an internal information retrieval system, part of which is the classification of the data.
The purpose of this work is to analyze approaches to classification, to consider the principles of application of these approaches used in modern information retrieval systems, to determine the possibility of using them in the GrabTheTrade
system..
Any classification is made on the basis of some signs. In order to classify the text, you first need to determine the values of the selected characteristics for this text. To use mathematical methods, the signs, as a rule, should have a quantitative expression. The quantitative expression of the attributes associated with the presence, interaction, or interposition of certain elements in the text can be the frequencies of the appearance of these elements (for example, the frequency of occurrence of alphabetic or word combinations). There are also other types of quantitative representation of characteristics (for example, when the characteristic characterizes the text entirely). [1].
The choice of a set of quantitative characteristics plays a decisive role in the classification of texts. The number of occurrences of frequently encountered words is much more informative in terms of classifying texts according to the individual style than the number of paragraphs and the number of occurrences of sentences consisting of a certain number of words.
One of the classes of methods of classification are the methods associated with machine learning. With these approaches, overfitting is possible.
Overfitting is a phenomenon in which a machine learning algorithm is configured to noise, errors and anomalous data in the training set.
A decision tree is a plan presented in the form of an acyclic graph, according to which a classification of objects described by a set of attributes is made for a certain target attribute. In the task of classifying texts, objects are texts (fragments of texts), the target attribute is a class of texts (style, genre, etc.). As attributes describing the text, we will use quantitative signs of the text.
Each tree node contains a branch condition for one of the attributes.
Following the trained tree in accordance with the values of the attributes of an arbitrary object, we will end up in one of the leaves of the tree. The value of this sheet will determine the value of the target attribute (class) of the object.
When using decision trees to over overfitting, pruning techniques are used. When thinning, on the basis of a certain criterion, those nodes of the tree that are most likely tuned to noise are discarded and the tree's ability to generalize is reduced. In the task of classifying texts, uncharacteristic data and noise are a frequent phenomenon (for example, text fragments 302 written in a slightly different than supposed style), so it is necessary to use decimation [2].
To find out the effectiveness of the classification of the decision tree method itself (without taking into account the informativeness of the characteristics), one can only compare the results of its work with the results of the work of other classification methods on the same data.
Neural networks are the kind of mathematical models that are built on the principle of networking nerve cells of the brain. At the heart of their construction is the idea that arbitrarily complex processes can be modeled with rather simple elements (neurons), and all the basic functionality of a neural network consisting of a set of neurons is provided by connections between neurons.
There are many types of neural networks of different structures. Neural network of direct distribution is the form of neural networks that is the most popular and well-tested on different tasks. They allow non-linear approximation of arbitrary functions (in our case, the functions belonging to the class) on a set of examples. Neurons in these networks are United in layers. The network consists of an arbitrary number of layers. The neurons of each layer are connected with neurons of the previous and subsequent layers according to the principle each with each
[3].
However, the following problems occur:
- the network learns too slowly;
- the value of the attribute depends on the size of the text, so when learning and testing on texts of different sizes, the network will not be able to find the right solution.
On the task of classifying texts by quantitative characteristics, neural networks noticeably exceed the decision trees in efficiency. But at the same time, their adjustment takes much longer (by 10 or more times) than the decision trees are built, and further data normalization is necessary before learning. In addition, decision trees give an easily interpreted answer in the form of a set of rules for selecting a particular class, and neural networks are only information about the degree of belonging to classes. Therefore, the choice of this or that method depends on the task: if high accuracy of classification of texts is required, then neural networks should be used, but if a clear and fast response is needed than decision trees required.
NBC (Naive Bayes Classifier) is based on the Bayes theorem.
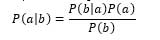
where,
- P(a|b) — the probability that document b belongs to class a, it is we need to calculate it;
- P(b|a) — probability of meeting document b among all documents of class a;
- P(a) — unconditional probability of meeting a document of class a in the body of documents;
- P(b) — unconditional probability of document b in the body of documents.
Bayes theorem allows you to rearrange the cause and effect. Knowing with what probability the cause leads to an event, this theorem allows us to calculate the probability that this particular reason led to the observed event [4].
The purpose of the classification is to understand to which class the document belongs, so it is not the probability itself, but the most likely class that is needed. The Bayesian classifier uses the estimate of a posteriori maximum to determine the most probable class.
That is, we need to calculate the probability for all classes and choose the class that has the maximum probability.
Advantages of the method [5]:
- the model defines the dependencies between all variables, which makes it easy to handle situations in which the values of some variables are unknown;
- bayesian networks are fairly easy to interpret and allow for easy analysis at the stage of predictive modeling in the "what if";
- the Bayesian method allows us to naturally combine the patterns derived from the data, and, for example, expert knowledge obtained in explicit form;
- the use of Bayesian networks avoids the problem of overfitting.
Disadvantages of the method:
- the result of the classification in the naive Bayesian approach is affected only by individual values of the input variables, the combined effect of pairs or triples of values of different attributes is not taken into account here. This could improve the quality of the classification model in terms of its predictive accuracy, however, would increase the number of verifiable options.
The support vector machine (SVM) takes a set of data consisting of numbers, and tries to predict which category it falls into. You can, for example, determine the role of the player in the football team for its height and running speed. For simplicity, consider only two possibilities: the position in the defense, which requires high height, and in the attack, where the player must move quickly [6].
SVM builds a prognostic model, looking for a line dividing the two categories. If you postpone one axis of height, and the other - the speed and put the best position for each player, you get the diagram shown in the picture. Defenders are crosses, and attackers are circles. Also, the diagram shows several lines that separate data into two categories.
The support vector machine finds the line that best divides the data. This means that it passes at the maximum distance from the points located near it. There are several dividing lines in the figure, but the best one is marked with the inscription "The best". To determine where the line must pass, only the nearest points are needed, they are called support vectors.
After the dividing line is found, to classify new samples, you only need to put them on the diagram and see which side of the separator they will be. It is not needed to view learning data when classifying new samples, so the classification is very fast.
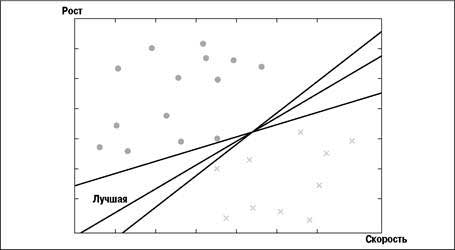
The disadvantage is that the optimal function and its parameters depend on the particular data set, so that each time it is necessary to select them again.
This method is more suited to large amounts of data, whereas decision trees provide information on a small set of data. Also, like neural networks, it is a "black box".
The method of nearest neighbors (k Nearest Neighbors, or kNN) is a very popular method of classification. This is one of the most understandable approaches to classification. At the level of intuition, the essence of the method is this: look at the neighbors, and I will name you. Formally, the basis of the method is the compactness hypothesis: if the distance metric between examples is introduced quite successfully, then similar examples are much more often in one class than in different classes [7].
According to the method of the nearest neighbors, the test case (green ball) will be classified as "blue", not "red".
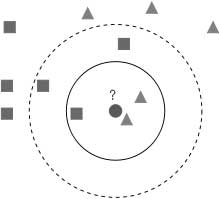
To classify each of the test sample objects, you must perform the following operations sequentially [8]:
- calculate the distance to each of the learning sample objects;
- select k learning sample objects, the distance to which is minimally;
- the class of the object being classified is the class that is the most often encountered among the k nearest neighbors.
To classify text in this method, words, sentences and paragraphs that are already defined in this text are selected as objects. So, if the first and third paragraphs of the text have an economic style, then most likely the second paragraph also applies to this style.
For the method of nearest neighbors, there are many important theorems that assert that on "infinite" samples this is the optimal method of classification. This is both a plus, because the correctness of the classification is high, and the minus of this method, cause the need to have large samples of data.
The analysis of existing classification algorithms was carried out, methods of obtaining reliable information in information retrieval systems were considered.
The information system "GrabTheTrade" is a system for collecting, analyzing and demonstrating the output of trade and economic information. It provides data from specified Internet sources, analysis of the reliability of the data received, aggregation and quarterly automatic updating of the data.
In this system planned to implement an information retrieval system for obtaining trade and political information. After carrying out search and ranking of the information in the system, the classification of the received data will be carried out. For the classification in this system, we can use methods that require a large amount of data, namely neural networks or SVM. It is also possible to use a combination of different methods for different stages of classification, as well as optimizing the correctness of the data obtained.
- Маннинг, К.Д. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце – М: ООО «И.Д. Вильямс», 2011. – 528 с.
- Чубукова, И.А. Data Mining / И.А. Чубукова – Киев: SmartBook, 2014 - 326 с.
- Батура, Т.В. Методы автоматической классификации текстов / Т.В. Батура, 2017
- Наивный байесовский классификатор. [Электронный ресурс] // Суровая реальность – Режим доступа: http://bazhenov.me/blog/2012/06/11/naive-bayes.
- Методы классификации и прогнозирования. [Электронный ресурс] // Интуит – Режим доступа: http://www.intuit.ru/studies/courses/6/6/lecture/176?page=5.
- Метод опорных векторов. [Электронный ресурс] // Блог о шифровании – Режим доступа: http://crypto.pp.ua/2011/05/metod-opornyx-vektorov/.
- Открытый курс машинного обучения. Тема 3. Классификация, деревья решений и метод ближайших соседей. [Электронный ресурс] // Хабрахабр – Режим доступа: https://habrahabr.ru/company/ods/blog/322534/#metod-blizhayshih-sosedey.
- Топ-10 data mining-алгоритмов простым языком. [Электронный ресурс] // Хабрахабр – Режим доступа: https://habrahabr.ru/company/itinvest/blog/262155/.
- Титаренко, М. Г. Информационная система «GrabTheTrade» / М. Г. Титаренко, И. А. Коломойцева // Информатика, управляющие системы, математическое и компьютерное моделирование в рамках III форума «Инновационные перспективы Донбасса» (ИУСМКМ – 2017): VIII Международная научно-техническая конференция. – Донецк: ДонНТУ, 2017. – С. 167-172.
- Оценка классификатора (точность, полнота, F-мера). [Электронный ресурс] // Суровая реальность – Режим доступа: http://bazhenov.me/blog/2012/07/21/classification-performance-evaluation.htm.