
Реферат за темою випускної роботи
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: червень 2019 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Аналіз методів вилучення знань з мережі Інтернет і їх зберігання
- 4.1 Автоматичне вилучення і обробка інформації
- 4.2 Моделі баз даних і зберігання інформації про спортивні змагання
- Висновки
- Перелік посилань
Вступ
У наш час існує величезна кількість інформації, яка знаходиться в глобальній мережі Інтернет. Дані являють собою неструктурований матеріал, серед якого зазвичай знаходиться велика кількість повторюваних відомостей, а також не актуальних для користувача. Також відбувається процес постійного зростання інформації, а значить, існує необхідність в розвитку технологій, які дозволять використовувати дані для виконання певних завдань.
1. Актуальність теми
Попередня обробка інформації розділяється на кілька етапів, таких як, консолідація, трансформація і очищення. Найбільш складним є консолідація, так як саме вона і включає в себе отримання та збір інформації.
Для того щоб вручну зібрати і проаналізувати дані хоча б з одного джерела піде багато часу, тому автоматичний збір і обробка інформації вкрай необхідний для сучасності. Обрана тема є актуальною, так як отримані відомості можна використовувати в різних напрямках, в тому числі і для прогнозування майбутніх подій, наприклад, результатів спортивних змагань.
2. Мета і задачі дослідження та заплановані результати
Метою дослідження є аналіз етапів обробки інформації, а також методів прогнозування з точки зору застосування їх в системі передбачення спортивних змагань.
Основні завдання дослідження:
- розглянути методи і алгоритми вилучення знань з html сторінок;
- вивчити підходи до первинної обробки отриманої інформації, її систематизації і фільтрації;
- розглянути підходи до зберігання інформації;
- виділити і дослідити подальші напрямки використання отриманих даних.
3. Огляд досліджень та розробок
Досліджувана тема популярна не тільки в міжнародних, але і в національних наукових спільнотах.
3.1 Огляд міжнародних джерел
Серед міжнародних джерел були знайдені матеріали, присвячені автоматизованого прогнозу результату спортивних змагань, розглянуті і опрацьовані методи вилучення, зберігання і обробки інформації, отриманої з html-сторінок.
Так у работі Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz и пр. Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion
[1] автори розглядають методи машинного навчання для злиття окремих джерел інформації, її синтезу і доповнення новими матеріалами без повторів. У статті наведені результати декількох досліджень, які демонструють відносну корисність різної інформації, джерела і методи вилучення.
Eftim Zdravevski и Andrea Kulakov в статье System for prediction of the winner in a sports game
[2] представляють систему, яка полегшує прогнозування переможці спортивних змагань. Система складається з методів для: збору даних з інтернету про різні види спорту, первинної обробки отриманих даних, вибору інформації і побудова моделі. Використані алгоритми були перевірені на придатність для такого роду питань, результати так само наведені в матеріалах статті.
У статті Rory P. Bunker и Fadi Thabtah A machine learning framework for sport result prediction
[3] представлений критичний аналіз літератури по машинному навчання, в якому основна увага приділяється застосуванню штучної нейронної мережі (ANN) для прогнозування спортивних результатів. При цьому определенеи використовувані методики навчання, джерела даних, відповідні кошти оцінки моделей і конкретні проблеми прогнозування спортивних результатів. В подальшому було розроблено новий підхід до спортивного прогнозування, за допомогою якого машинне навчання можна використовувати в якості навчальної стратегії.
3.2 Огляд національних джерел
Серед національних джерел можна відзначити роботу Полякової М.Ю. і Судакова Б.Н. Разработка подхода к созданию алгоритма синтаксического анализа естественно-языкового текста информационно-поисковых систем
[4]. У статті розглянуті існуючі методи синтаксичного аналізу природно-мовного тексту і виділені основні переваги та недоліки, розроблений вдосконалений алгоритм синтаксичного аналізу. Автори доводять і обґрунтовують досвідченим шляхом, що паралельне використання синтаксичного і семантичного аналізу дозволяє скоротити часові витрати на обробку природно-мовного тексту.
У книзі Интернетика. Навигация в сложных сетях: модели и алгоритмы
Ландэ Д.В, Снарского А.А. та Безсуднова И.В. [5] розглядаються питання, що відносяться до інформаційної структурі веб-простору, теорії складних мереж, моделям інформаційного пошуку та глибинного аналізу текстів, загальним закономірностям сучасних інформаційних потоків і їх моделювання.
Завдяки взаємодії вчених різних напрямків, компанія Яндекс провела захід, присвячений аналізу даних в спорті. У статті Анализ данных в спорте: взаимодействие учёных, клубов и федераций. Лекция в Яндексе
[6] коротко розказано про завдання і прийняті рішення за допомогою аналізу даних в спорті. Розглянуто потенціал спортивного ринку, аналіз даних в світовому спорті, наведені посилання на журнали, які ведуть роботу в даному напрямку.
3.3 Огляд локальних джерел
У рефераті Арбузової О.В. Разработка и исследование алгоритмов для повышения эффективности интеллектуального анализа web-контента
[7] описаний аналіз існуючих підходів до вилучення даних і знань з Web, розглянуті етапи вилучення значущих документів з Web-сторінок і фільтрація шуму. Розроблено алгоритми вилучення об'єктів з текстових документів на основі шаблонного методу.
Анохіна В. С. в авторефераті на тему Автоматизация извлечения знаний из Internet в форме онтологии для построения прикладных баз знаний
[8] наводить теоретичні поняття семантичних мереж, оповідає про онтологію як спосіб представлення знань.
4. Аналіз методів вилучення знань з мережі Інтернет і їх зберігання
4.1 Автоматичне вилучення і обробка інформації
Як було сказано раніше, обробка інформації розділяється на 3 етапи, такі як консолідація, трансформація і очищення.
Консолідація - комплекс методів і процедур, спрямованих на вилучення даних з різних джерел, забезпечення необхідного рівня їх інформативності та якості, перетворення в єдиний формат, в якому вони можуть бути завантажені в сховище даних або аналітичну систему [9].
Консолідація даних є початковим етапом реалізації будь-якої аналітичної задачі або проекту. В основі консолідації лежить процес збору та організації зберігання даних у вигляді, оптимальному з точки зору їх обробки на конкретній аналітичної платформі або вирішення конкретної аналітичної задачі. Супутніми завданнями консолідації є оцінка якості даних і їх збагачення.
Основні критерії оптимальності з точки зору консолідації даних [9]:
- забезпечення високої швидкості доступу до даних;
- компактність зберігання;
- автоматична підтримка цілісності структури даних;
- контроль несуперечності даних.
Ключовим поняттям консолідації є джерело даних - об'єкт, що містить структуровані дані, які можуть виявитися корисними для вирішення аналітичної задачі. Необхідно, щоб використовувана аналітична платформа могла здійснювати доступ до даних з цього об'єкта безпосередньо або після їх перетворення в інший формат [10].
Аналітичні додатки, як правило, не містять розвинених засобів введення і редагування даних, а працюють з вже сформованими вибірками. Таким чином, формування масивів даних для аналізу в більшості випадків лягає на плечі замовників аналітичних рішень. У процесі консолідації даних вирішуються наступні завдання [9]:
- вибір джерел даних;
- розробка стратегії консолідації;
- оцінка якості даних;
- збагачення;
- очищення;
- перенесення в сховище даних.
Спочатку здійснюється вибір джерел, що містять дані, які можуть мати відношення до розв'язуваної задачі, потім визначаються тип джерел і методика організації доступу до них.
При розробці стратегії консолідації даних необхідно враховувати характер розташування джерел даних - локальний, коли вони розміщені на тому ж ПК, що і аналітичне додаток, або віддалений, якщо джерела доступні тільки через локальну або Глобальну комп'ютерні мережі. Характер розташування джерел даних може істотно вплинути на якість зібраних даних (втрата фрагментів, неузгодженість в часі їх поновлення, суперечливість тощо).
Іншим важливим завданням, яку потрібно вирішити в рамках консолідації, є оцінка якості даних з точки зору їх придатності для обробки за допомогою різних аналітичних алгоритмів і методів. У більшості випадків вихідні дані є брудними
, тобто містять фактори, які не дозволяють їх коректно аналізувати, виявляти приховані структури і закономірності, встановлювати зв'язки між елементами даних і виконувати інші дії, які можуть знадобитися для отримання аналітичного рішення. До таких факторів належать помилки введення, пропуски, аномальні значення, шуми, протиріччя і т.д. Тому перед тим, як приступити до аналізу даних, необхідно оцінити їх якість і відповідність вимогам, що пред'являються аналітичною платформою. Якщо в процесі оцінки якості будуть виявлені фактори, які не дозволяють коректно застосувати до даних ті чи інші аналітичні методи, необхідно виконати відповідну очистку даних [9].
Трансформація - комплекс методів і алгоритмів, спрямованих на оптимізацію уявлення і форматів даних з точки зору вирішуваних завдань і цілей аналізу. Трансформація не ставить за мету змінити інформаційний зміст даних. Її завдання - представити цю інформацію в такому вигляді, щоб вона могла бути використана найбільш ефективно. Даний етап є важливим в процесі аналізу, тому що ефективність аналізу, достовірність і точність результатів залежить від того, наскільки грамотно буде виконаний даний етап [11].
Очищення даних - комплекс методів і процедур, спрямованих на усунення причин, що заважають коректній обробці: аномалій, пропусків, дублікатів, протиріч і шумів [9].
Автоматичний збір інформації був би набагато легше, якби існувала єдина система побудови сайтів і розміщення інформації в них. Однак не існує таких стандартів, а значить необхідно витягувати інформацію іншим способом. Такий підхід має свої переваги і недоліки. До переваг можна віднести:
- швидкість обробки даних досить висока;
- автоматична настройка системи дозволити отримувати інформацію з практично будь-яких джерел;
- отримані дані можна аналізувати і використовувати для подальшого прогнозування.
Недоліками є те, що необхідно чітко відловлювати виключення і помилки, тому що найменша з них може привести до втрати даних.
4.2 Моделі баз даних і зберігання інформації про спортивні змагання
База даних - сукупність даних, організованих відповідно до концептуальної структурою, яка описує характеристики цих даних і взаємини між ними, причому такі збори даних, яке підтримує одну або більше областей застосування [12].
За моделлю даних розглянемо таку класифікацію:
- ієрархічна;
- мережева;
- об'єктно-орієнтована;
- реляційна
Ієрархічна модель даних - це модель даних, де використовується уявлення бази даних у вигляді дерева (ієрархічної) структури, що складається з об'єктів різних рівнів [13]. Файлова система комп'ютера є наочним прикладом ієрархічної бази даних.
Такий тип бази добре оптимізований для читання інформації, що дає можливість швидко вибирати і видавати необхідну інформацію користувачеві. Однак недоліком такої структури є те, що не можна швидко перебирати інформацію, так як необхідно послідовно проходити по всій гілці, що вимагає багато часу і ресурсів. На малюнку 1 представлена ??структура ієрархічної бази даних.
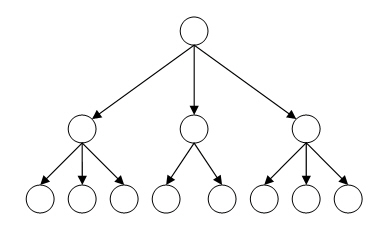
Рисунок 1 – Структура ієрархічної моделі даних
Мережеві бази даних являють собою якусь модифікацію ієрархічної бази даних, якщо порівняти структури ієрархічної і мережної моделей даних (рис. 1-2), то можна помітити що вони схожі між собою, відмінністю є лише те, що в мережевій моделі у дочірнього елемента може бути кілька предків, тобто, елементів що стоять вище нього.
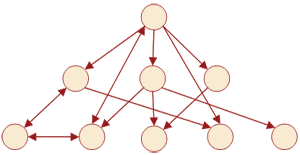
Рисунок 2 – Структура мережевої моделі даних
Об'єктно-орієнтовані бази даних - бази даних, в яких інформація представлена у вигляді об'єктів, як в об'єктно-орієнтованих мовах програмування. Основними перевагами цього підходу є такі характеристики:
- відсутня проблема невідповідності моделі даних в додатку і БД. Всі дані зберігаються в БД в тому ж вигляді, що і в моделі програми;
- не потрібно окремо підтримувати модель даних на стороні СУБД;
- всі об'єкти на рівні джерела даних строго типізовані (не потрібно строкових імен колонок);
- автоматизований рефакторинг об'єктно-орієнтованої бази даних і працює коду [14].
Однак є ряд недоліків:
- мінімальна оптимізація запитів;
- відсутність стандартної алгебри запитів;
- відсутність засобів забезпечення запитів;
- відсутність підтримки уявлень;
- проблеми з безпекою;
- обмежена підтримка обмежень цілісності тощо. [15].
Реляційна база даних - це сукупність взаємопов'язаних таблиць, кожна з яких містить інформацію про об'єкти певного типу. Рядок таблиці містить дані про один об'єкт (наприклад, товар, клієнт), а стовпці таблиці описують різні характеристики цих об'єктів - атрибутів (наприклад, найменування, код товару, відомості про клієнта). Записи, тобто рядки таблиці, мають однакову структуру - вони складаються з полів, що зберігають атрибути об'єкта. Кожне поле, тобто стовпець, описує тільки одну характеристику об'єкта і має строго певний тип даних. Всі записи мають одні і ті ж поля, тільки в них відображаються різні інформаційні властивості об'єкта [16].
Бази даних - це досить абстрактне поняття, так як таблиця призначена для зберігання інформації, а ось набір таблиць, які пов'язані між собою - база даних.
Проектування структури бази даних є найбільш трудомістким завданням при роботі з реляційною моделлю. На даному етапі необхідно продумати і створити набір таблиць, зв'язків, таким чином, щоб збільшення інформації не приводило до великої уповільнення роботи системи. Реляційна модель дозволяє модифікувати дані, тобто додавати, видаляти записи без особливих зусиль. Це дає можливість якісної роботи зі зберіганням інформації, отриманої зі сторінок Інтернет про спортивні змагання, так як ця область вимагає постійного оновлення і додавання інформації. До таких даних, можна віднести такі характеристики і статистичні показники:
- назва команд;
- кількість зіграних ігор;
- кількість перемог / поразок / нічиїх;
- кількість забитих м'ячів;
- кількість забитих / пропущених м'ячів;
- місце в турнірній таблиці;
- рейтинг чемпіонату;
- % перемог (за останні 10 матчів);
- % нічиїх (за останні 10 матчів);
- % поразок (за останні 10 матчів);
- середній% володіння м'ячем;
- середній% точних передач;
- кількість ключових матчів в найближчий місяць;
- наявність / відсутність ключових гравців;
- погодні умови і новизна стадіону;
- принциповість найближчих 3 суперників;
- середня кількість забитих м'ячів в останніх 5 матчах;
- середня кількість пропущених м'ячів в останніх 5 матчах;
- середня кількість забитих м'ячів в останніх 5 матчах віч-на-віч;
- середня кількість пропущених м'ячів в останніх 5 матчах віч-на-віч;
- результати матчів і т.д.
База даних повинна бути максимально інформативна і в той же час компактна і не надмірна. Це дасть можливість простіше працювати з нею і обробляти дані, які можна буде використовувати в подальшому для прогнозування результатів змагань.
Висновки
Аналіз джерел показав, що тема отримання інформації з web-сторінок і її обробки актуальна як в міжнародному, національному так і в локальному наукових спільнотах.
У даній роботі був виконаний аналіз етапів обробки інформації, кожен з яких так чи інакше буде використовуватися для отримання необхідних, структурованих даних; проаналізовані моделі даних і зберігання інформації про спортивні змагання. Найбільш підходящою моделлю є реляційний підхід, так як він схильний до модифікації даних, простий в розумінні, а також використанні. Були виділені показники і характеристики, які необхідно отримувати зі сторінок Інтернет і зберігати в базі даних.
Перелік посилань
- Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, Wei Zhang. Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion [Текст] / Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, Wei Zhang [Электронный ресурс]. – Режим доступа: https://www.cs.ubc.ca/~murphyk/papers/kv-kdd14.pdf.
- Eftim Zdravevski, Andrea Kulakov. System for Prediction of the Winner in a Sports Game [Текст] / Eftim Zdravevski, Andrea Kulakov [Электронный ресурс]. – Режим доступа: https://www.researchgate.net/profile/Eftim_Zdravevski/publication/226597761_System_for_Prediction_of_the_Winner_in_a_Sports_Game/links/5577fee408aeb6d8c01cec9c/System-for-Prediction-of-the-Winner-in-a-Sports-Game.pdf.
- Rory P.Bunkera, Fadi Thabtah. A machine learning framework for sport result prediction [Текст]/ Rory P.Bunkera, Fadi Thabtah [Электронный ресурс]. – Режим доступа: https://www.sciencedirect.com/science/article/pii/S2210832717301485.
- Полякова М.Ю., Судаков Б.Н. Разработка подхода к созданию алгоритма синтаксического анализа естественно-языкового текста информационно-поисковых систем [Текст] / М.Ю. Полякова, Б.Н. Судаков [Электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/n/razrabotka-podhoda-k-sozdaniyu-algoritma-sintaksicheskogo-analiza-estestvenno-yazykovogo-teksta-informatsionno-poiskovyh-sistem.
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика. Навигация в сложных сетях: модели и алгоритмы [Текст] / Д.В Ландэ, А.А. Снарский, И.В. Безсуднов [Электронный ресурс]. – Режим доступа: http://dwl.kiev.ua/art/internetica/internetica.pdf.
- Анализ данных в спорте: взаимодействие учёных, клубов и федераций. Лекция в Яндексе [Электронный ресурс]. – Режим доступа: https://habr.com/company/yandex/blog/351948/.
- Арбузова О.В. Разработка и исследование алгоритмов для повышения эффективности интеллектуального анализа web-контента [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/arbuzova/index.htm.
- Анохина В.С. Автоматизация извлечения знаний из Internet в форме онтологии для построения прикладных баз знаний [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2005/fvti/anohina/index.html.
- Консолидация данных – ключевые понятия [Электронный ресурс]. – Режим доступа: http://www.cfin.ru/itm/olap/cons.shtml.
- Задачи консолидации [Электронный ресурс]. – Режим доступа: http://bourabai.kz/tpoi/olap01.htm.
- Трансформация данных [Электронный ресурс]. – Режим доступа: https://basegroup.ru/community/glossary/transformation.
- База данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/База_данных.
- Иерарическая модель данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Иерархическая_модель_данных.
- Введение в объектно-ориентированные базы данных [Электронный ресурс]. – Режим доступа: https://habr.com/post/56399/.
- Объектно-ориентированные базы данных: достижения и проблемы [Электронный ресурс]. – Режим доступа: https://www.osp.ru/os/2004/03/184042/.
- Реляционная база данных и ее особенности. Виды связей между реляционными таблицами [Электронный ресурс]. – Режим доступа: http://www.yaklass.ru/materiali?chtid=511&mode=cht.