Аннотация
Здравевски Е., Кулаков А. - Система прогнозирования победителя в спортивной игреЭта работа представляет систему, которая облегчает предсказание победителя в спортивной игре. Система состоит из методов для: сбора данных из Интернета для игр в различные виды спорта, предварительной обработки полученных данных, выбора функций и построения моделей. Многие из алгоритмов прогнозирования и классификации, реализованные в Weka (среда Waikato для анализа знаний), были протестированы на применимость для такого рода задач, и было проведено сравнение результатов.
1 Введение
Общеизвестно, что для многих видов спорта собирается огромное количество данных - для каждого игрока, команды, игры и сезона. Очевидно, что это слишком много данных для анализа вручную. Это дало нам возможность протестировать некоторые алгоритмы интеллектуального анализа данных на наборах данных, содержащих записи спортивных игр. Интеллектуальный анализ данных может быть выполнен из различных аспектов - прогнозирование конечных результатов, прогнозирование травм игрока [8], прогнозирование будущих физических результатов [7], обнаружение определенных закономерностей (например, игрок B сделал 60% своих полевых целей, когда игрок A был в положении разыгрывающего и сделал 40% его полевых целей, когда другой разыгрывающий был на поле [6]), а также некоторые другие аспекты. Цель нашего исследования - протестировать различные алгоритмы интеллектуального анализа данных для прогнозирования окончательного результата (победителя) игры. Мы не стремимся выяснить точные причины, по которым был получен конкретный результат, а использовать большой набор результатов, чтобы предсказать неизвестный. Классификаторы, которые используются в процессе прогнозирования реализован в Weka (среда Waikato для анализа знаний) [9].
Много исследований было сделано в этой области экспертами, которые имеют необходимые знания предметной области для определенного вида спорта, но также имеют солидный опыт в математике. Во многих случаях они придумали сложные формулы для определенного типа производительности в игре (атакующие, оборонительные и т. д.), формулы для общего рейтинга игроков и команд [1] [2] [3] [4] [5] , формула рейтинга команды может быть очень сложной (она может содержать более 15 параметров), но также очень важна для процесса классификации. Иногда рейтинги команд используются некоторыми букмекерами для корректировки шансов на игру.
Раздел 2 описывает архитектуру предлагаемой системы. В разделе 3 каждый модуль системы описан более подробно. Результаты этого исследования представлены в разделе 4, и проводится сравнение результатов, полученных различными классификаторами.
2 Архитектурное решение
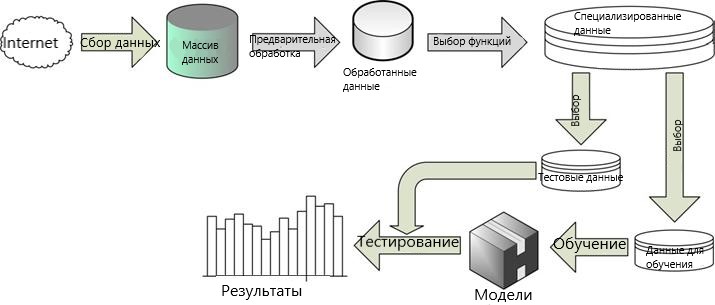
В каждом процессе сбора данных и обнаружения знаний исходные данные должны пройти несколько этапов обработки, чтобы извлечь полезную информацию. Для этого конкретного случая извлечения данных в спортивных данных этапы обработки данных показаны на рис. 1.
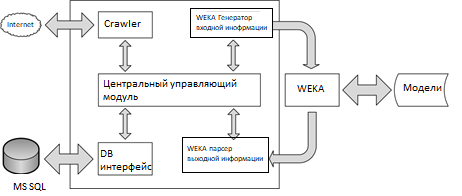
Поэтапная обработка данных была бы проще, если бы система была спроектирована модульно. Таким образом, каждый из модулей может быть реализован и протестирован независимо от других, но также облегчает внесение изменений в один модуль без необходимости перепроектировать другие. Каждый из модулей посвящен обработке информации на определенном этапе. Существует центральный модуль, который объединяет все специализированные модули в единую систему. Еще один плюс в этом дизайне заключается в том, что другие модули могут быть легко добавлены в систему. Это может быть достигнуто следующим образом: сначала будет разработан и внедрен новый модуль, а затем центральный модуль должен быть изменен, чтобы он мог использовать новый. Такие модули могут содержать реализации алгоритмов прогнозирования или кластеризации, которые не содержатся в WEKA. Модульная конструкция представленной системы показана на рис. 2.
2.1 Сбор данных
Очевидно, что для начала тестирования алгоритмов для этой задачи необходим набор данных записей игр. Хотя довольно просто найти результат и статистику определенной игры в Интернете, насколько нам известно, нет общедоступного набора данных, который можно было бы загрузить и импортировать в какую-либо базу данных. Это заставляет нашу систему иметь модуль для получения информации (crowler
) для интересующих игр из Интернета и хранения ее в базе данных.
2.2 Предварительная обработка данных
После того, как все необходимые данные сохранены в реляционной базе данных, их необходимо предварительно обработать. Предварительная обработка может относиться к: нормализации и / или дискретизации некоторых параметров в заданном диапазоне; или генерирование новых параметров, которых не было в исходной базе данных.
Новые параметры генерируются путем просмотра данных предыдущих игр текущего сезона. Предыдущие игры относятся к играм, в которые играли до даты игры, чьи данные предварительно обрабатываются, и могут содержать данные игр, в которые играли команды, играющие в эту конкретную игру, а также игр, в которые играли другие команды. Это означает, что ни один из сгенерированных параметров не использует будущие
данные, то есть данные, которые не были известны до начала конкретной игры. Другими словами, каждый сгенерированный параметр зависит от времени и команды. Некоторые из параметров, которые генерируются в этом модуле системы:
- Количество травмированных игроков в команде А перед конкретной игрой. Этот параметр можно сгенерировать, просмотрев данные из предыдущей игры, в которую играла команда A, поскольку он содержит информацию о том, почему конкретный игрок не играл - либо это было решение тренера, либо игрок получил травму. Кроме того, есть сайты, которые ежедневно публикуют информацию о травмированных игроках. Поиск информации с такого рода веб-сайтов также может быть автоматизирован.
- Победная серия (w) команды A перед конкретной игрой. Это делается путем подсчета количества игр подряд, выигравших (w положительно) или проигравших (w отрицательно) до этой игры.
- Усталость команды А перед конкретной игрой. Мы вводим этот параметр, чтобы указать, сколько раз Команде А приходилось путешествовать, чтобы сыграть в предыдущие 7 игр. Поскольку расписание игр в NBA, WNBA, NHL и некоторых других американских видах спорта очень загружено (2-4 игры в неделю), иногда командам приходится много путешествовать, чтобы не отставать от графика. Много путешествий способствует усталости команды. В примере, показанном на рис. 3, усталость команды A перед игрой 27 (конкретной игрой) оценивается в 5/6, потому что она должна была путешествовать 5 раз. Максимальная утомляемость равна 1 (если команда путешествовала 6 раз), а минимальная - 0 (если команда играла во все соответствующие игры дома).
- Дома, в гостях и общий процент побед. Количество игр, выигранных дома, деленное на количество игр, сыгранных дома, дает процент выигрыша дома. Расчет остальных параметров аналогичен.
- Наступательные, оборонительные и общие рейтинги команды. Эти рейтинги рассчитываются по формулам, которые более подробно описаны для различных видов спорта в [4] и для баскетбола NBA в [1][2] [4].

2.3 Выбор функций
Независимо от области проблемы и независимо от алгоритма классификации или кластеризации, данные обучения и испытаний должны быть представлены в виде набора точек данных. Каждая точка данных представляет собой N-мерное пространство, и каждая координата точки данных представляет элемент.
Фаза предварительной обработки обогащает набор доступных параметров для каждой игры. Однако использование всех доступных параметров нецелесообразно, поскольку это может привести к снижению производительности и точности. Важно определить, какой из доступных параметров будет выбран в качестве функций для обучающих и тестовых наборов данных. Некоторый набор функций может дать лучшую точность, чем другие наборы. Представленные результаты в этом исследовании получены с использованием 10 функций. Некоторые из этих функций описаны в предыдущем разделе. Еще одна настройка, которая выполняется, заключается в объединении двух совместимых параметров в одну функцию (например, вместо использования в качестве двух разных характеристик рейтинга оскорблений домашней команды и рейтинга оскорблений гостевой команды, их различие используется в качестве единой функции). Имена или идентификаторы команд, которые играют в игру, не используются в качестве функций игры.
2.4 Наборы обучающих и тестовых данных
Для целей этого исследования мы собрали данные за 2 последовательных сезона NBA с официального сайта NBA. Эти данные содержат подробную статистику каждой игры, сыгранной в течение сезона. Данные первого сезона используются в качестве тренировочного набора, а данные второго сезона - в качестве тестового набора. В лиге NBA 30 команд, и каждая из них играет по 82 игры в течение регулярного сезона, таким образом, в общей сложности сыграно 1230 игр. Однако первые 20 игр в сезоне каждой команды не рассматриваются ни для обучения, ни для тестирования, потому что они не могут быть представлены выбранными нами функциями. А именно, чтобы представить игру как точку данных для любого алгоритма прогнозирования, она должна быть представлена в виде набора функций. Для некоторых функций, которые мы решили наиболее подходить для этой проблемы, нужны данные из предыдущих игр (в том же сезоне), и если мы будем использовать игры с начала сезона, то эти данные будут отсутствовать или будут неполными. В следующем примере показано, почему эти игры избегают при обучении и тестировании: предположим, у нас есть обученная модель, и мы хотим предсказать исход 6-й игры команды A. Однако для функции, которая соответствует среднему запасу очков в последних 10 играх. нам нужны данные из предыдущих 10 игр (в том же сезоне) команды А, и таких данных не существует.
3 Реализация
В разделе 2 был дан обзор структуры системы и назначения каждого модуля, и в этом разделе будет обсуждаться их реализация, проводимая на языке программирования C # с использованием платформы .Net и базы данных SQL Server.
3.1 Crawler
Задача, которую выполняет сканер, - сбор данных для игр в определенной лиге и в определенный период времени и вставка их в базу данных SQL. Данные могут быть собраны с официального сайта вида спорта, где публикуются подробные статистические данные по многим параметрам.
К счастью, процесс сбора данных из NHL, NFL, NBA, WNBA и т. Д. Может быть автоматизирован. Изучив вручную URL-адреса, по которым в определенную дату играли финальные оценки игр, мы пришли к выводу, что они имеют согласованный формат. Зная этот формат, можно автоматически создать URL для любой желаемой даты. Если в указанную дату не было игр, то веб-страницы на эту дату не существовало бы, или, если бы она существовала, на ней было бы показано предупреждение. В любом случае, мы бы знали, что он не содержит информации, которая представляет для нас интерес. Кроме того, формат, в котором данные публикуются на веб-странице, также является непротиворечивым - существуют таблицы, в которых содержится сводная информация об игре и достижениях каждого игрока, и они имеют постоянное количество столбцов в определенном формате. Это позволяет анализировать HTML веб-страницы и сохранять необходимые данные в базе данных.
Все упомянутое здесь говорит о том, что можно разработать приложение, которое может автоматически заполнять базу данных для заданного диапазона дат игр в конкретной лиге. Собранные данные содержат статистику эффективности каждого игрока и команды в каждой игре. Сканер должен быть привязан к конкретному виду спорта и конкретной лиге, поскольку он использует свой веб-сайт для сбора необходимых данных. Другое ограничение заключается в том, что серьезная реконструкция веб-страницы подразумевает, что сканер также должен быть модифицирован. Однако, поскольку наша цель состоит в том, чтобы построить модель из набора данных предыдущих игр, чтобы предсказать исход будущих игр, нам нужны только данные за несколько сезонов. Данные за первый или два сезона могут быть использованы для обучения, а данные за следующий год - для тестирования и проверки. Алгоритмы будут оцениваться в соответствии с их точностью в наборе тестовых данных.
3.2 Предварительная обработка
Некоторая часть предварительной обработки выполняется в режиме онлайн во время сбора данных, поскольку этот способ более эффективен. Большинство методов предварительной обработки реализованы в виде хранимых процедур и функций в базе данных. Некоторые из них представляют потенциальные особенности, в то время как другие просто облегчают вычисление первых. Методы вычисления признаков вызываются перед началом каждой фазы обучения или фазы тестирования, что означает, что они не вызываются только один раз, а их результаты сохраняются в базе данных. Каждый раз, когда они вызываются, их результат используется в качестве входных данных для модуля генерации ARFF [9], который подготавливает входные данные для системы WEKA. Результаты методов расчета характеристик не сохраняются в базе данных по причинам гибкости и масштабируемости. А именно, если результаты хранятся в базе данных, добавление новой функции повлечет за собой редизайн и обновление таблиц, в которых хранятся результаты. Нет такой проблемы в дизайне, который мы используем. Если новая функция должна быть добавлена, функция, которая ее вычисляет, должна быть реализована и вызвана на этапе выбора функции, который намного менее сложен, чем другое возможное решение.
3.3 Выбор функций
Выбор функции осуществляется вручную, т. е. мы должны решить, какие функции следует принимать во внимание. Он реализован в виде хранимой в базе данных функции, которая в результате возвращает таблицу. Каждый столбец в результирующей таблице представляет значение одного объекта, а каждая строка представляет точку данных. Эта хранимая процедура принимает в качестве входных данных только две действительные даты1, и для каждой игры, сыгранной между этими датами, создается точка данных с выбранными функциями.
3.4 Интерфейс для WEKA
Чтобы вызвать алгоритмы классификации, кластеризации или фильтрации из WEKA, должен быть реализован интерфейс. Алгоритмы WEKA могут быть вызваны из командной строки с помощью одной команды, которая имеет некоторые конкретные параметры [9] - входной файл ARFF [9], файл ввода / вывода модели, имя алгоритма и т. д. Файлы ARFF содержат входные данные, установленные для алгоритм, который вызывается. Они генерируются с использованием результатов из модуля выбора объектов. Формат вывода из WEKA можно настроить с помощью той же команды. Выходные данные должны быть захвачены и затем проанализированы, чтобы параметры нашего интереса (например, прогнозируемое значение) могли быть сохранены.
4 Результаты
В этом разделе представлены результаты нашего исследования. Набор обучающих и тестовых данных содержит точки данных, соответствующие 930 играм NBA каждая. Данные, которые находятся в наборе обучающих данных, не существуют в наборе тестовых данных. Классификатор референта, с которым будут сравниваться другие (реализованные в WEKA), является классификатором, который использует следующую логику:
Пусть команда A (домашняя команда) имеет рейтинг A, а команда B (посещающая команда) имеет рейтинг B до начала игры, в которую они собираются сыграть. Рейтинг рассчитывается по формуле рейтинга команды Холлингера [2]. Если A-B + 3> 0, решите, что эта игра будет выиграна Командой A. Добавление 3 в пользу Команды A представляет преимущество домашней площадки.
Таблица 1 показывает точность проверенных классификаторов.
Таблица 1. Точность классификаторов |
||||
|
Классификатор |
Всего игр |
Корректно |
Некорректно |
Точность |
functions_Logistic |
930 |
677 |
253 |
0,728 |
meta_MultiClassClassifier |
930 |
677 |
253 |
0,728 |
meta_ThresholdSelector |
930 |
664 |
266 |
0,714 |
trees_NBTree |
930 |
662 |
268 |
0,712 |
meta_RandomSubSpace |
930 |
660 |
270 |
0,710 |
rules_JRip |
930 |
658 |
272 |
0,708 |
functions_RBFNetwork |
930 |
657 |
273 |
0,706 |
functions_VotedPerceptron |
930 |
657 |
273 |
0,706 |
functions_SMO |
930 |
651 |
279 |
0,700 |
trees_LMT |
930 |
651 |
279 |
0,700 |
trees_ADTree |
930 |
646 |
284 |
0,695 |
bayes_NaiveBayesUpdateable |
930 |
646 |
284 |
0,695 |
meta_LogitBoost |
930 |
646 |
284 |
0,695 |
meta_FilteredClassifier |
930 |
644 |
286 |
0,692 |
bayes_NaiveBayes |
930 |
644 |
286 |
0,692 |
meta_MultiBoostAB |
930 |
641 |
289 |
0,689 |
meta_RandomCommittee |
930 |
639 |
291 |
0,687 |
trees_RandomForest |
930 |
639 |
291 |
0,687 |
Результаты показывают, что лучшие классификаторы имеют на 5% лучшую точность, чем референтный классификатор, что дает команду с лучшим рейтингом. Они на 9% лучше, чем классификатор zeroR, который предсказывает наиболее распространенный класс (в этом случае предсказанный победитель всегда является домашней командой, потому что он является наиболее распространенным победителем). Обратите внимание, что почти все классификаторы из WEKA были использованы с настройками по умолчанию. Все классификаторы в таблице 1 более подробно описаны в [9], а некоторые из них - в [10].
5 Выводы и будущая работа
Это исследование показало, что система прогнозирования победителя спортивной игры может быть разработана и внедрена. Точность, которую он может обеспечить, зависит от многих параметров: конкретного вида спорта, доступных данных, выбранных функций, алгоритма классификации и т. Д. К сожалению, у нас нет базы для сравнения наших результатов. Классификатор ссылок, который мы определили в разделе 4, использует жадную логику, и мы не можем полагаться только на нее. Мы не смогли найти какой-либо набор прогнозов, сделанных экспертом-человеком или какой-либо современной искусственной системой для полного сезона какого-либо вида спорта. Если бы мы могли протестировать нашу систему на таком наборе игр и сравнить наши прогнозы с их прогнозами на том же наборе, то можно было бы сделать лучшую оценку нашей системы.
Однако есть ещё несколько способов повысить точность прогнозов. Одна вещь, которую мы можем сделать, - это сначала кластеризовать обучающие и тестовые наборы данных, а затем использовать разные модели для каждого кластера. Логика этой идеи заключается в том, что некоторые команды редко проигрывают много игр подряд, в то время как другие редко выигрывают много игр подряд. Нет никаких гарантий, что эта модификация будет способствовать более точным прогнозам, но это стоит попробовать. Еще одна вещь, которую можно попробовать - использовать агрегирование разных классификаторов, чтобы повысить степень достоверности некоторых прогнозов или повысить общую точность всех прогнозов. Как упоминалось ранее, выбор функции осуществляется вручную. Эта фаза может быть изменена путем ее автоматизации, поэтому можно проверить различные комбинации функций. Такая модификация может способствовать улучшению результатов, поскольку человеческий фактор при выборе функции будет удален.
Ссылки
- Oliver, D.: Basketball on Paper: Rules and Tools for Performance Analysis. Potomac Books. (2005)
- Hollinger, J.: Pro Basketball Prospectus: Potomac Books. (2002)
- Basketball terms and formulas, http://www.basketballreference.com
- APBRmetrics, http://en.wikipedia.org/wiki/APBRmetrics
- Albert, J., Koning, R., H.: Statistical thinking in sports. Chapman & Hall/CRC. (2008)
- Bhandari, I. et al: Advanced Scout: Data Mining and Knowledge Discovery in NBA Data, Data Mining and Knowledge Discovery v. 1, p. 121-125. Kluwer Academic Publishers. (1997)
- Fieltz, L., Scott, D.: Prediction of Physical Performance Using Data Mining. Research Quarterly for Exercise and Sport, v74 i1 pA-25. (2003)
- Flinders, K.: Football Injuries are Rocket Science, http://www.vnunet.com/vnunet/news/2120386/football-injuries-rocketscience, 2002.10.14.
- Witten, I.H., Frank, E.: Data Mining: Practical machine learning tools and techniques (2nd Edition). Morgan Kaufmann. (2005)
- Duda, R., O., Hart, P. E., Stork, D., G.: Pattern Classification (2nd Edition), John Wiley & Sons, Inc., 2001