Аннотация
Власюк Д.А., Коломойцева И.А. Анализ этапов обработки и хранения информации о спортивных состязаниях В работе выполнен анализ этапов обработки информации, а также модели баз данных, необходимых для хранения обработанной информации. Представлены показатели и характеристики, спортивных состязаний с которыми необходимо работать внутри системы.
Общая постановка проблемы
В наше время существует огромное количество информации, которая находится в глобальной сети Интернет. Данные представляют собой неструктурированный материал, среди которого обычно находится большое количество повторяющихся сведений, а также не актуальных для пользователя. Также происходит процесс постоянного роста информации, а значит, существует необходимость в развитии технологий, которые позволят использовать данные для выполнения определенных задач.
Предварительная обработка информации разделяется на несколько этапов, таких как, консолидация, трансформация и очистка. Наиболее сложным является консолидация, так как именно она и включает в себя получение и сбор информации.
Для того чтобы вручную собрать и проанализировать данные хотя бы из одного источника уйдет большое количество времени, поэтому автоматический сбор и обработка информации крайне необходим для современности. Полученные сведения можно использовать в различных направлениях, в том числе и для прогнозирования будущих событий, например, результатов спортивных состязаний.
Цель работы – анализ этапов обработки информации, а также а также моделей представления данных.
Автоматический сбор и обработка информации
Как было сказано ранее, обработка информации разделяется на 3 этапа, такие как консолидация, трансформация и очистка.
Консолидация – комплекс методов и процедур, направленных на извлечение данных из различных источников, обеспечение необходимого уровня их информативности и качества, преобразование в единый формат, в котором они могут быть загружены в хранилище данных или аналитическую систему [1].
Консолидация данных является начальным этапом реализации любой аналитической задачи или проекта. В основе консолидации лежит процесс сбора и организации хранения данных в виде, оптимальном с точки зрения их обработки на конкретной аналитической платформе или решения конкретной аналитической задачи. Сопутствующими задачами консолидации являются оценка качества данных и их обогащение.
Основные критерии оптимальности с точки зрения консолидации данных[1]:
- обеспечение высокой скорости доступа к данным;
- компактность хранения;
- автоматическая поддержка целостности структуры данных;
- контроль непротиворечивости данных.
Ключевым понятием консолидации является источник данных – объект, содержащий структурированные данные, которые могут оказаться полезными для решения аналитической задачи. Необходимо, чтобы используемая аналитическая платформа могла осуществлять доступ к данным из этого объекта непосредственно либо после их преобразования в другой формат [2].
Аналитические приложения, как правило, не содержат развитых средств ввода и редактирования данных, а работают с уже сформированными выборками. Таким образом, формирование массивов данных для анализа в большинстве случаев ложится на плечи заказчиков аналитических решений. В процессе консолидации данных решаются следующие задачи [1]:
- выбор источников данных;
- разработка стратегии консолидации;
- оценка качества данных;
- обогащение;
- очистка;
- перенос в хранилище данных.
Сначала осуществляется выбор источников, содержащих данные, которые могут иметь отношение к решаемой задаче, затем определяются тип источников и методика организации доступа к ним.
При разработке стратегии консолидации данных необходимо учитывать характер расположения источников данных — локальный, когда они размещены на том же ПК, что и аналитическое приложение, либо удаленный, если источники доступны только через локальную или Глобальную компьютерные сети. Характер расположения источников данных может существенно повлиять на качество собранных данных (потеря фрагментов, несогласованность во времени их обновления, противоречивость и т.д.).
Другой важной задачей, которую требуется решить в рамках консолидации, является оценка качества данных с точки зрения их пригодности для обработки с помощью различных аналитических алгоритмов и методов. В большинстве случаев исходные данные являются «грязными», то есть содержат факторы, не позволяющие их корректно анализировать, обнаруживать скрытые структуры и закономерности, устанавливать связи между элементами данных и выполнять другие действия, которые могут потребоваться для получения аналитического решения. К таким факторам относятся ошибки ввода, пропуски, аномальные значения, шумы, противоречия и т.д. Поэтому перед тем, как приступить к анализу данных, необходимо оценить их качество и соответствие требованиям, предъявляемым аналитической платформой. Если в процессе оценки качества будут выявлены факторы, которые не позволяют корректно применить к данным те или иные аналитические методы, необходимо выполнить соответствующую очистку данных [1].
Трансформация – комплекс методов и алгоритмов, направленных на оптимизацию представления и форматов данных с точки зрения решаемых задач и целей анализа. Трансформация не ставит целью изменить информационное содержание данных. Её задача – представить эту информацию в таком виде, чтобы она могла быть использована наиболее эффективно. Данный этап является важным в процессе анализа, потому что эффективность анализа, достоверность и точность результатов зависит от того, насколько грамотно будет выполнен данный этап [3].
Очистка данных – комплекс методов и процедур, направленных на устранение причин, мешающих корректной обработке: аномалий, пропусков, дубликатов, противоречий и шумов [1].
Автоматический сбор информации был бы намного легче, если бы существовала единая система построения сайтов и размещения информации в них. Однако не существует таких стандартов, а значит необходимо извлекать информацию иным способом. Такой подход имеет свои достоинства и недостатки. К достоинствам можно отнести:
- скорость обработки данных достаточно высока;
- автоматическая настройка системы позволить извлекать информацию из практически любых источников;
- полученные данные можно анализировать и использовать для дальнейшего прогнозирования.
Недостатками является то, что необходимо четко отлавливать исключения и ошибки, так как малейшая из них может привести к потере данных.
Модели баз данных и хранение информации о спортивных состязаниях
База данных – совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, причём такое собрание данных, которое поддерживает одну или более областей применения [4].
По модели данных рассмотрим такую классификацию:
- иерархическая;
- сетевая;
- объектно-ориентированная;
- реляционная.
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов различных уровней [5]. Файловая система компьютера является наглядным примером иерархической базы данных.
Такой тип базы хорошо оптимизирован для чтения информации, что дает возможность быстро выбирать и выдавать необходимую информацию пользователю. Однако недостатком такой структуры является то, что нельзя быстро перебирать информацию, так как необходимо последовательно проходить по всей ветке, что требует много времени и ресурсов. На рисунке 1 представлена структура иерархической базы данных.
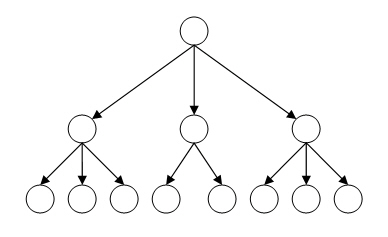
Рисунок 1 – Структура иерархической модели данных
Сетевые базы данных представляют из себя некую модификацию иерархической базы данных, если сравнить структуры иерархической и сетевой моделей данных (рис. 1-2), то можно заметить что они схожи между собой, отличием является только то, что в сетевой модели у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него.
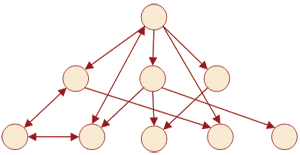
Рисунок 2 – Структура сетевой модели данных
Объектно-ориентированные базы данных – базы данных, в которых информация представлена в виде объектов, как в объектно-ориентированных языках программирования. Основными преимуществами этого подхода являются такие характеристики:
- отсутствует проблема несоответствия модели данных в приложении и БД. Все данные сохраняются в БД в том же виде, что и в модели приложения;
- не требуется отдельно поддерживать модель данных на стороне СУБД;
- все объекты на уровне источника данных строго типизированы (не нужно строковых имен колонок);
- автоматизирован рефакторинг объектно-ориентированной базы данных и работающего кода [6].
Однако есть ряд недостатков:
- минимальная оптимизация запросов;
- отсутствие стандартной алгебры запросов;
- отсутствие средств обеспечения запросов;
- отсутствие поддержки представлений;
- проблемы с безопасностью;
- ограниченная поддержка ограничений целостности и т.д. [7].
Реляционная база данных — это совокупность взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного типа. Строка таблицы содержит данные об одном объекте (например, товаре, клиенте), а столбцы таблицы описывают различные характеристики этих объектов – атрибутов (например, наименование, код товара, сведения о клиенте). Записи, то есть строки таблицы, имеют одинаковую структуру – они состоят из полей, хранящих атрибуты объекта. Каждое поле, то есть столбец, описывает только одну характеристику объекта и имеет строго определенный тип данных. Все записи имеют одни и те же поля, только в них отображаются различные информационные свойства объекта [8].
Базы данных — это достаточно абстрактное понятие, так как таблица предназначена для хранения информации, а вот набор таблиц, которые связаны между собой – база данных.
Проектирование структуры базы данных является самой трудоемкой задачей при работе с реляционной моделью. На данном этапе необходимо продумать и создать набор таблиц, связей, таким образом, чтобы увеличение информации не приводило к большому замедлению работы системы. Реляционная модель позволяет модифицировать данные, то есть добавлять, удалять записи без особых усилий. Это дает возможность качественной работы с хранением информации, полученной со страниц Интернет о спортивных состязаниях, так как эта область требует постоянного обновления и добавления информации. К таким данным, можно отнести такие характеристики и статистические показатели:
- название команд;
- количество сыгранных игр;
- количество побед/поражений/ничьих;
- количество забитых мячей;
- количество забитых/пропущенных мячей;
- место в турнирной таблице;
- рейтинг чемпионата;
- % побед (за последние 10 матчей);
- % ничьих (за последние 10 матчей);
- % поражений (за последние 10 матчей);
- средний % владения мячом;
- средний % точных передач;
- количество ключевых матчей в ближайший месяц;
- наличие/отсутствие ключевых игроков;
- погодные условия и новизна стадиона;
- принципиальность ближайших 3 соперников;
- среднее количество забитых мячей в последних 5 матчах;
- среднее количество пропущенных мячей в последних 5 матчах;
- среднее количество забитых мячей в последних 5 матчах лицом-к-лицу;
- среднее количество пропущенных мячей в последних 5 матчах лицом-к-лицу;
- результаты матчей и т.д.
База данных должна быть максимально информативна и в тоже время компактна и не избыточна. Это даст возможность проще работать с ней и обрабатывать данные, которые можно будет использовать в дальнейшем для прогнозирования результатов состязаний.
Выводы
Анализ источников показал, что тема получения информации из web-страниц и ее обработки актуальна как в международном, национальном так и в локальном научных сообществах.
В данной работе был выполнен анализ этапов обработки информации, каждый из которых так или иначе будет использоваться для получения необходимых, структурированных сведений; проанализированы модели данных и хранение информации о спортивных состязаниях. Наиболее подходящей моделью является реляционный подход, так как он склонен к модифицированию данных, прост в понимании, а также использовании. Были выделены показатели и характеристики, которые необходимо получать со страниц Интернет и хранить в базе данных.
Список использованной литературы
- Консолидация данных – ключевые понятия [Электронный ресурс]. – Режим доступа: http://www.cfin.ru/itm/olap/cons.shtml.
- Задачи консолидации [Электронный ресурс]. – Режим доступа: http://bourabai.kz/tpoi/olap01.htm.
- Трансформация данных [Электронный ресурс]. – Режим доступа: https://basegroup.ru/community/glossary/transformation.
- База данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/База_данных.
- Иерарическая модель данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Иерархическая_модель_данных.
- Введение в объектно-ориентированные базы данных [Электронный ресурс]. – Режим доступа: https://habr.com/post/56399/.
- Объектно-ориентированные базы данных: достижения и проблемы [Электронный ресурс]. – Режим доступа: https://www.osp.ru/os/2004/03/184042/.
- Реляционная база данных и ее особенности. Виды связей между реляционными таблицами [Электронный ресурс]. – Режим доступа: http://www.yaklass.ru/materiali?chtid=511&mode=cht.