
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Обзор инструментов персонализации
- 2. Описание работы рекомендательных алгоритмов
- 2.1 Классификация алгоритмов кластеризации
- 2.2 Описание работы алгоритмов кластеризации 8
- 2.3 Сравнение алгоритмов кластеризации
- Заключение
- Список источников
Введение
Всемирная сеть сейчас содержит огромное количество информации, знаний. Пользователи на различных условиях могут просматривать всевозможные документы, аудио и видеофайлы. Однако это многообразие данных скрывает в себе проблемы, которые могут возникнуть как при анализе, так и при поиске необходимой информации в сети Интернет.
Это означает, что люди должны ориентироваться среди чрезвычайно большого количества доступных альтернатив, когда хотят что–либо найти. Например, от выбора нового мобильного телефона или плеера до поиска кинофильма для вечернего просмотра. С другой стороны, выступают владельцы интернет–магазинов и сервисов: они заинтересованы в персональной рекламе и рекомендациях каждому конкретному пользователю, потому что такой подход может существенно увеличить прибыль компаний. Как результат, в последние годы интерес к разработке и улучшению существующих рекомендательных систем значительно вырос.
1. Обзор инструментов персонализации
Многие компании предлагают сегодня услуги по персонализации. Рассмотрим краткую характеристику доступных сегодня инструментов, которые ориентированы на удобную интеграцию с веб-сайтом и не требуют квалифицированного программирования.
Last.fm и Pandora — рекомендуют музыку. Они придерживаются разных стратегий рекомендации: Last.fm использует, кроме собственно рейтингов других пользователей, исключительно «внешние» данные о музыке – автор, стиль, дата, тэги и т.п., а Pandora основывается на «содержании» музыкальной композиции, используя очень интересную идею MusicGenomeProject, в котором профессиональные музыканты анализируют композицию по нескольким сотням атрибутов[1-2]. Сейчас Pandora недоступна в России.
Google, Yahoo!, Яндекс — можно сказать, что они тоже рекомендуют пользователям сайты. Поисковики пытаются предсказать, насколько данный документ релевантен данному запросу, а рекомендательные системы – пытаются предсказать, какой рейтинг данный пользователь поставит данному продукту. У ведущих поисковиков есть масса побочных проектов, основанных на рекомендательных системах - например, Yahoo! Music.
Сервис Personyze создан для сегментирования посетителей сайта в режиме реального времени, а также для предоставления им персонализированного и оптимизированного контента, основанного на их демографических, поведенческих и исторических характеристиках. Personyze предлагает самую расширенную SaaS платформу на рынке персонализации сайтов и сегментации пользователей в режиме реального времени. Сразу после добавления кода можно в реальном времени видеть отчёты о поведении пользователей на сайте. Все посетители автоматически распределяются по сегментам в соответствии с их местоположением, источником посещений (включая конкретные ключевые запросы), демографическими данными, действиями на сайте и т.д. – всего около 50 метрик. Как только установлено соответствие посетителя и сегмента, Personyze выполняет необходимые персонализирующие действия, позволяющие вам менять любой фрагмент контента сайта, будь то добавление баннера, изменение картинки, изменение текста, добавление рекомендованных продуктов и многое другое. Посетитель будет видеть оптимизированную под него версию сайта. Сервис удобен тем, что позволяет работать с отдельными сегментами и предоставлять детализированные отчёты по каждому из них.
Создатели Monoloop – сконцентрированы на контроле за покупательским циклом. Установленный на сайт, их сервис отслеживает поведение каждого посетителя сайта, узнаёт его в момент следующего посещения и в соответствии с этим меняет под него определённые элементы сайта. Monoloop автоматически создаёт профиль для каждого нового клиента и позволяет выстраивать внятную и последовательную кампанию по работе с ним. Сервис запоминает, что именно интересует покупателя, и может предложить другие подходящие товары из схожих категорий. Плюс он понимает, на каком этапе принятия решения о покупке находится покупатель, и советует, что можно сделать, чтобы подтолкнуть покупателя к покупке.
Gravity стартап поколения Web 3.0 — это версия веба, подразумевающая персонализацию интернета для каждого пользователя. Он позиционирует себя как сервис, предлагающий уникальный персонализированный опыт, который помогает пользователям находить наиболее интересный контент на основе их индивидуальных потребностей. На начальном этапе сервис был ориентирован на конечных потребителей, но в настоящее время сосредоточен только на B2B (рекламодатели и издатели). Персонализация Gravity заключается в применении различных фильтров в режиме «реального времени» к информации, доступной пользователям в поиске и социальных медиа. Запатентованная Gravity технология создает Interest Graph на базе интересов, предпочтений и привычек пользователя, и позволяет владельцам сайтов предложить своим читателям редакторский и рекламный контент, соответствующий их интересам.
2. Описание работы рекомендательных алгоритмов

Рисунок 1 – Работа алгоритма коллаборативной фильтрации
2.1 Классификация алгоритмов кластеризации
Выделим две основные классификации алгоритмов кластеризации[5].
- Иерархические и плоские. Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Таким образом, на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями – наиболее мелкие кластера. Плоские алгоритмы строят одно разбиение объектов на кластеры.
- Четкие и нечеткие. Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
В случае использования иерархических алгоритмов встает вопрос, как объединять между собой кластера, как вычислять «расстояния» между ними.
Одиночная связь (расстояния ближайшего соседа) В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки.
Полная связь (расстояние наиболее удаленных соседей) В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп.
Невзвешенное попарное среднее. В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них.
Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. Взвешенное попарное среднее Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента.
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху–вниз»: сначала все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные.
Таким образом, строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева.
2.2 Описание работы алгоритмов кластеризации
Нечеткая кластеризация. Наиболее популярным алгоритмом нечеткой кластеризации является алгоритм c–средних. Он представляет собой модификацию метода k–средних[6]. Шаги работы алгоритма:
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки по формуле
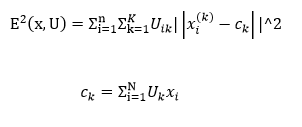
- Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными
Этот алгоритм может не подойти, если заранее неизвестно число кластеров, либо необходимо однозначно отнести каждый объект к одному кластеру.
Суть алгоритмов, основанных на графах, заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность внесения различных усовершенствований, основанные на геометрических соображениях.
Основными алгоритмами являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации. Алгоритм выделения связных компонент В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом.
Путём удаления связи, помеченной CD, с длиной равной 6 единицам (ребро с максимальным расстоянием), получаем два кластера: {A, B, C} и {D, E, F, G, H, I}. Второй кластер в дальнейшем может быть разделён ещё на два кластера путём удаления ребра EF, которое имеет длину, равную 4,5 единицам. Послойная кластеризация Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами).
Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами 0 <= p(x, x’) <= 1, то 0 <= c <= 1. Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами: Посредством изменения порогов расстояния {с0, …, сm}, где 0 = с0 < с1 <…< сm = 1, возможно контролировать глубину иерархии получаемых кластеров.
2.3 Сравнение алгоритмов кластеризации
| Алгоритм кластеризации | Вычислительная сложность |
|---|---|
| Иерархический | O(n2) |
| k–средних | O(nkl), где k – число кластеров, l – число итераций |
| c–средних | зависит от алгоритма |
| Выделение связных компонент | зависит от алгоритма |
| Минимальное покрывающее дерево | O(n2 log n) |
| Послойная кластеризация | O(max(n, m)), где m < n(n–1)/2 |
Анализ тональности обычно определяют как одну из задач компьютерной лингвистики, т.е. подразумевается, что мы можем найти и классифицировать тональность, используя инструменты обработки естественного языка (такие как теггеры, парсеры и др.). Сделав большое обобщение, можно выделить четыре подхода. Подход, основанный на правилах, на словарях, машинное обучение с учителем и машинное обучение без учителя. Подходы, основанные на словарях, используют так называемые тональные словари (affective lexicons) для анализа текста. В простом виде тональный словарь представляет из себя список слов со значением тональности для каждого слова.
Чтобы проанализировать текст, можно воспользоваться следующим алгоритмом: сначала каждому слову в тексте присвоить его значением тональности из словаря (если оно присутствует в словаре), а затем вычислить общую тональность всего текста. Вычислять общую тональность можно разными способами. Самый простой из них – среднее арифметическое всех значений.
Подход, основанный на правилах, состоит из специально созданного набора правил, применяя которые система делает заключение о тональности текста. Например, для предложения «Я люблю кофе», можно применить следующее правило: Если сказуемое (например, «люблю») входит в положительный набор глаголов («люблю», «обожаю», «одобряю» и т.д.) и в предложении не имеется отрицаний, то классифицировать тональность как «положительная».
Многие коммерческие системы используют данный подход, несмотря на то что он требует больших затрат, т.к. для хорошей работы системы необходимо составить большое количество правил. Зачастую правила привязаны к определенному домену (например, «ресторанная тематика») и при смене домена («обзор фотоаппаратов») требуется заново составлять правила. Тем не менее, этот подход является наиболее точным при наличии хорошей базы правил, но совершенно неинтересным для исследования.
Машинное обучение с учителем является наиболее распространенным методом, используемым в исследованиях. Его суть состоит том, чтобы обучить машинный классификатор на коллекции заранее размеченных текстах, а затем использовать полученную модель для анализа новых документов. Машинное обучение без учителя представляет собой, наверное, наиболее интересный и в то же время наименее точный метод анализа тональности. Одним из примеров данного метода может быть автоматическая кластеризация документов.
Процесс создания системы анализа тональности очень похож на процесс создания других систем с применением машинного обучения: необходимо собрать коллекцию документов для обучения классификатора. Каждый документ из обучающей коллекции нужно представить в виде вектора признаков для каждого документа нужно указать «правильный ответ», т.е. тип тональности (например, положительная или отрицательная), по этим ответам и будет обучаться классификатор выбор алгоритма классификации и обучение классификатора использование полученной модели Количество классов, на которые делят тональность, обычно задается из спецификации системы.
Классификация тональности на более чем два класса – это очень сложная задача. Даже с тремя классами очень сложно достичь хорошей точности независимо от применяемого подхода. Если стоит задача классификации на более чем два класса, то тут возможны следующие варианты для обучения классификатора
Регрессия – нужно обучить классификатор для получения численного значения тональности, например от 1 до 10, где большее значение означает более положительную тональность. Обычно иерархическая классификация дает лучшие результаты, чем плоская, т.к. для каждого классификатора можно найти набор признаков, который позволяет улучшить результаты. Однако он требует больших времени и усилий для обучения и тестирования. Регрессия может показать лучшие результаты, если классов действительно много.
Наиболее распространенный способ представления документа в задачах компьютерной лингвистики и поиска – это либо в виде набора слов (bag-of-words) либо в виде набора N-грамм. Так, например, предложение «Я люблю черный кофе» можно представить в виде набора униграмм (Я, люблю, черный, кофе) или биграмм (Я люблю, люблю черный, черный кофе). Обычно униграммы и биграммы дают лучшие результаты чем N-граммы более высоких порядков (триграммы и выше), т.к. выборка обучения в большинстве случаев недостаточна большая для подсчета N–грамм высших порядков. Всегда имеет смысл протестировать результаты с применением униграмм, биграмм и их комбинации. В зависимости от типа данных униграммы могут показать лучшие результаты чем биграммы, а могут и наоборот. Также иногда комбинация униграммов и биграммов позволяет улучшить результаты. Стемминг и лемматизация.
Другой способ представления текста – символьные N-граммы. Текст «Я люблю черный кофе» можно представить в виде следующих 4-символьных N-грамм: «я лю», «люб», «юблю», «блю », и т.д. Несмотря на то, что такой способ может показаться слишком примитивным, т.к. на первый взгляд набор символов не несет в себе никакой семантики, тем не менее, этот метод иногда дает результаты даже лучше чем N-граммы слов. N-граммы символов соответствуют в какой–то мере морфемам слов, а в частности корень слова («люб») несет в себе его смысл. Символьные N-граммы могут быть полезны в случаях при наличии орфографических ошибок в тексте – набор символов у текста с ошибками и набор символов у текста без ошибок будет практически одинаков в отличие от слов.
Для языков с богатой морфологией (например, для русского) – в текстах могут встречаться одинаковые слова, но в разных вариациях (разные род или число), но при этом корень слов не изменяется, а, следовательно, и общий набор символов. Символьные N-граммы применяются гораздо реже, чем N-граммы слов, но иногда они могут улучшить результаты. Также можно использовать дополнительные признаки, такие как: части речи, пунктуация (наличие в тексте смайлов, восклицательных знаков), наличие в тексте отрицаний («не», «нет», «никогда»), междометий и т.д. Следующим шагом в составлении вектора признаков является присваивание каждому признаку его вес. Для некоторых классификаторов это является необязательным, например, для байесовского классификатора, т.к. он сам высчитывает вероятность для признаков. Но если используется метод опорных векторов, то задание весов может заметно улучшить результаты.
Заключение
В ходе работы, была исследована работа алгоритмов рекомендательных систем, были проанализированы популярные алгоритмы их классификация, их базовая структура.
Были изучены алгоритмы кластеризации. Рассмотрены алгоритмы нечеткой кластеризации, а также изучены различные алгоритмы, основанные на графах. Рассмотрены подходы работы с натуральными языками, обработки текста и процесса работы с тональностью. Были рассмотрены современные алгоритмы используемые в рекомендательных системах, а также вспомогательные средства и программы, необходимые для их работы.
Рассмотрены основные данные, необходимые для работы рекомендательной системы, такие как мера расстояний на примере анализа тональности текста. Изучены базы данных предоставляющие информацию для работы алгоритмов. Изучены принципы регрессии, плоской классификации и выбора признаков. Были изучены варианты нахождения и определения мнений в тексте и определения их свойств. Рассмотрена важность выделения объекта рецензии при рассмотрении комментариев.
Список источников
- Music Genome Project – Википедия [Электронный ресурс]. – Режим доступа: https://en.wikipedia.org/wiki/Music_Genome_Project
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)
- Netflix Prize – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Netflix_Prize
- Граф интересов – Википедия [Электронный ресурс]. – Режим доступа:https://ru.wikipedia.org/wiki/Граф_интересов
- Рекомендательная система - Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Рекомендательная_система
- Коллаборативная фильтрация – Википедия [Электронный ресурс]. – https://ru.wikipedia.org/wiki/Коллаборативная_фильтрация
- Выбор языка и средства разработки – Мегаобучалка [Электронный ресурс]. – Режим доступа: http://megaobuchalka.ru/9/25993.html
- Минский М. Вычисления и автоматы / М. Минский. – М.: Мир, 1971. – 364 с.
- Рихтер, Д. CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C# / Д. Рихтер, – СПб. : Питер, 2007. – 656c.
- Ito M. Algebraic theory of automata and languages / M. Ito. – World Scientific Publishing, 2004. – 199 pp.
- Нейгел, К. C# 2005 для профессионалов / К. Нейгел – К. : Вильямс, 2006. – 763 c.
- Сравнительная характеристика, назначение и возможности современных языков – Студопедия [Электронный ресурс]. – Режим доступа: http://studopedia.ru/18_43813_sravnitelnaya-harakteristika-naznachenie-i-vozmozhnosti-sovremennih-yazikov.html
- Грофф Р.Д. SQL: полное руководство / Р.Д. Грофф, Н.П. Вайнберг, Д.Э. Оппель – СПб. : Вильямс, 2014. – 961 с.
- Труб, И. Объектно – ориентированное моделирование на С++: Учебный курс/ И. И. Труб. – СПб.: Питер, 2006. – 411 с.
- Объектно-ориентированный анализ и проектирование c примерами приложений / [Гради Буч и др]. [3-е изд.] – М.: Вильямс, 2008. – 720с.
- Грушвицкий Р.И. Проектирование систем на микросхемах программируемой логики / Р.И. Грушвицкий, А.Х. Мурсаев, Е.П. Угрюмов. – СПб.: БХВ-Петербург, 2002. – 608 с.
- Amaral J. Designing genetic algorithms for the state assignment problem / J. Amaral, K. Turner, J. Chosh // IEEE Transactions on Systems, Man, and Cybernetics. – 1995. – vol. 25. – pp. 659-694.
- Pandora (Радио) – Википедия [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Pandora_(радио)