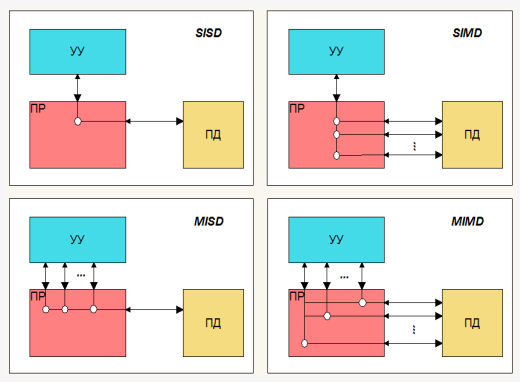
Рисунок 1 – Классификация компьютерных архитектур М.Флинна
Автор: Денисенко А. А.
Источник: https://moluch.ru/conf/tech/archive/332/15178/
Параллельное программирование по праву считается наиболее перспективным и востребованным направ- лением в области разработки программного обеспечения. Это связано с известным противоречием: возрастающая сложность промышленных, технических и научных задач, решаемых с помощью компьютерных систем, предъявляет к последним требования производительности, которые не могут быть выполнены, ввиду ограничений, накладыва- емых законами физики (предельная скорость света, те- плоотдача, принцип неопределенности). Однако, такие задачи решать нужно. Поэтому единственным выходом из этой ситуации является использование идеи парал- лелизма вычислений (хотя и на эту идею накладывается ограничение в виде математического закона Амдала). Те- оретически параллелизм можно вводить на любом уровне абстракции компьютерной системы. На каком бы уровне он не был введен, там будет существовать коммутация, а, следовательно, управление и программирование. Именно многоуровневость является основным фактором разно- образия средств и технологий параллельного програм- мирования. Чтобы не запутаться в этом разнообразии укажем на два полезных общих понятия: классификация и связность компьютерных систем. В свете этих понятий рассмотренные ниже технологии параллельного програм- мирования выстроятся в четкую логическую структуру.
Разнообразие способов организации параллельных вычислительных си- стем побудило научный мир к решению задачи класси- фикации. Самая ранняя и наиболее известная класси- фикация М. Флинна (M. Flynn) предложена в 1966 году. Ключевое понятие здесь – поток. На основе числа по- токов команд и потоков данных Флинн делит все системы на четыре класса архитектур:
На рисунке 1 показано схематическое представление рассмотренной классификации, взятое из работы [1]. Здесь приняты следующие условные обозначения: УУ — устройство управления, ПД — память данных, ПР — процессорные элементы. Данная классификация является самой распространенной. С её помощью можно определить базовые принципы работы компьютерной системы. Однако, она не является единственной. В работе [1] рассмотрено множество других классификаций.
Итак, любая архитектура компьютерной системы может быть отнесена к одному из четырех вышеперечисленных классов. Любые вычислительные элементы этих систем, как и сами системы в целом, могут быть интегрированы. Исследование вопроса степени интеграции приводит к рассмотрению понятия связности.
Рисунок 1 – Классификация компьютерных архитектур М.Флинна
По характеру интеграции компьютерные системы делятся на два больших класса: сильно связанные (tightly coupled) и слабо связанные (loosely coupled). Э ти два класса плавно переходят в друг друга. Предельный случай сильно связанных систем — это внутрипроцессорный параллелизм. Предельный случай слабо связанных — распределенные вычислительные системы (grid computing). Рисунок 2 иллюстрирует связность систем на шкале связности [4]. Здесь под цифрами соответственно обозначены:
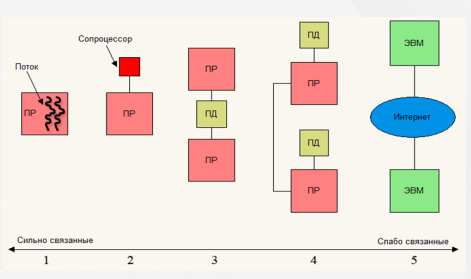
Рисунок 2 – Шкала связности параллельных компьютерных систем
Программирование сопроцессора — SSE. SSE — это SIMD расширение процессоров Intel. Большим плюсом при использовании инструкций SSE является то, что не нужно при этом решать главную задачу параллельного программирования — задачу синхронизации. Программирование, при этом, ничем не отличается от последовательного. Просто вместо скалярных операндов здесь используются векторные.
Поддержка SSE реализована во многих современных компиляторах. На рисунке 3 показаны примеры использования SSE инструкций во встроенных ассемблерах Microsoft Visual Studio 2010 и Embarcadero Rad Studio XE8..

Рисунок 3 – SSE в ассемблерах в самых популярных IDE
В этих примерах происходит перемножение векторов. Параллельность работы заключается в том, что это действие происходит за один такт работы процессора. Таким образом, это классический пример SIMD архитектуры. За время своего существования технология SSE эволюционировала до SSE4. Основные усовершенствования технологии: большая разрядность регистров, более широкий набор инструкций, инструкции для обработки специализированных данных [2].
Во всех современных операционных системах реализована возможность распределения вычислительных мощностей процессора. Это достигается за счет многозадачности — свойства операционной системы обеспечивать параллельную (или псевдопараллельную) работу процессов (process). При запуске любой программы, операционная системы создает для неё процесс, который состоит из исполняемой программы (код и данные), виртуального адресного пространства (address space), ресурсов, выделяемых процессу и, как минимум, одного потока управления (thread of execution). В виртуальном адресном пространстве одного процесса может действовать несколько потоков. Если эти потоки являются взаимодействующими, то для организации их работы нужно решать задачу синхронизации [3]. Основные функции для работы с потоками показаны на рисунке 4.
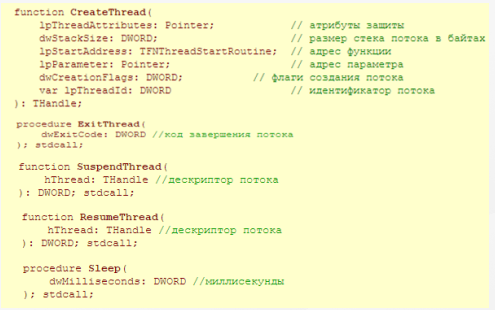
Рисунок 4 – Основные функции для работы с потоками
Итак, в чем состоит задача синхронизации работы взаимодействующих потоков? Она состоит в задаче корректного доступа потоков к общему, критическому ресурсу . Если она надлежащим образом не решена, то потоки могут зависнуть. Возникнет их взаимоблокировка (тупиковая ситуация), либо состояние гонок. Для решения этой задачи в операционных системах реализованы следующие примитивы синхронизации:
Примитивы синхронизации, описанные разными стандартами и реализованные в разных операционных системах, имеют схожий интерфейс.
Стандарт OpenMP реализован в языках программирования C/С++ и Fortran и работает как в Unix, так и в Windows системах. Технология представляет собой набор особых директив компилятора, процедур и переменных окружения. Процесс программирования сводится (в упрощенной форме) к вставке директив в места где код может быть распараллелен [1]. Сказанное иллюстрируется рисунком 5.
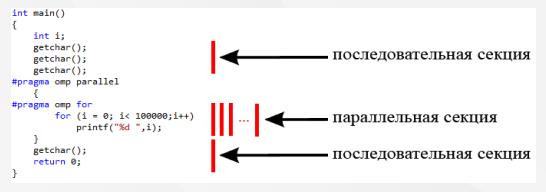
Рисунок 5 – Применение технологии OpenMP
На этом рисунке код в параллельной секции создаст потоки ОС (количеством равным количеству ядер процессора), которые совместно выполнят все итерации этого цикла.
Мы рассмотрели основные популярные технологии параллельного программирования, указали на ключевые понятия, которые позволяют комбинировать эти технологии и находить общие архитектурные решения. Однако, тема статьи настолько обширна, что достойное раскрытие её возможно в рамках толстых томов монографий. Так мы, не коснулись важного вопроса в этой области — вопроса разработки параллельных алгоритмов. Так же мы опустили вопрос разработки и дискретизации математической модели. Тем не менее, рассмотренные технологии и понятия достаточны для введения в этот раздел программирования.
1. Воеводин В. В., Воеводин Вл.В. Параллельные вычисления. — СПб.: БХВ-Петербург., 2002. — 600 с.
2. Качко Е. Г. Параллельное программирование: Учебное пособие. — Харьков: Форт, 2011. — 528 с.
3. Лупин С. А., Посыпкин М. А. Технологии параллельного программирования. — М.:ФОРУМ, 2011. — 208 с.
4. Таненбаум Э. Архитектура компьютера. — СПб.:Питер, 2009. -844 с.