Abstract.
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems. Existing RIQA methods focus on the RGB color-space and are developed based on small datasets with binary quality labels (i.e., ‘Accept’ and ‘Reject’). In this paper, we first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images from the EyePACS dataset, based on a three-level quality grading system (i.e., ‘Good’, ‘Usable’ and ‘Reject’) for evaluating RIQA methods. Our RIQA dataset is characterized by its large-scale size, multi-level grading, and multi-modality. Then, we analyze the influences on RIQA of different color-spaces, and propose a simple yet efficient deep network, named Multiple Color-space Fusion Network (MCF-Net), which integrates the different color-space representations at both a feature-level and prediction-level to predict image quality grades. Experiments on our EyeQ dataset show that our MCF-Net obtains a state-of-the-art perfor- mance, outperforming the other deep learning methods. Furthermore, we also evaluate diabetic retinopathy (DR) detection methods on images of different quality, and demonstrate that the performances of automated diagnostic systems are highly dependent on image quality.
Keywords:
Retinal image · Quality assessment · Deep learning.
1 Introduction
Retinal images are widely used for early screening and diagnosis of several eye diseases, including diabetic retinopathy (DR), glaucoma, and age-related macular degeneration (AMD). However, retinal images captured using different cameras, by people with various levels of experience, have a large variation in quality. A study based on UK BioBank showed that more than 25% of the retinal images are not of high enough quality to allow accurate diagnosis [8]. The quality degra- dation of retinal images, e.g., from inadequate illumination, noticeable blur and low contrast, may prevent a reliable medical diagnosis by ophthalmologists or automated analysis systems [1]. Thus, retinal image quality assessment (RIQA) is required for controlling the quality of retinal image. However, RIQA is a subjective task that depends on the experience of the ophthalmologists and the type of eye disease. Moreover, the traditional general quality assessment methods for natural images are not suitable for the RIQA task.
Recently, several methods for RIQA specifically have been proposed, which can be divided into two main categories: structure-based methods and feature-based methods. Structure-based methods employ segmented structures to determine the quality of retinal images. For example, an image structure clustering method was proposed to extract compact representations of retinal structures to determine image quality levels [10]. Blood vessel structures are also widely used for identifying the quality of retinal images [7, 8, 15]. However, structure-based methods rely heavily on the performance of structure segmentation, and cannot obtain latent visual features from images. Feature-based methods, on the other hand, directly extract feature representations from images, without structure segmentation. For example, features quantifying image color, focus, contrast and illumination can be calculated to represent the quality grade [12]. Wang et.al. employed features based on the human visual system, with a support vector machine (SVM) or a decision tree to identify high-quality images [16]. A fundus image quality classifier that analyzes illumination, naturalness, and structure was also provided to assess quality [14]. Recently, deep learning techniques that integrate multi-level representations have been shown to obtain significant performances in a wide variety of medical imaging tasks. A combination of unsu- pervised features from saliency maps and supervised deep features from convolutional neural networks (CNNs) have been utilized to predict the quality level of retinal images [17]. For instance, Zago et.al. adapted a deep neural network by using the pre-trained model from ImageNet to deal with the quality assess- ment task [18]. Although these deep methods have successfully overcome the limitations of hand-crafted features, they nevertheless have several of their own drawbacks. First, they focus on the RGB color-space, without considering other color-spaces that from part of the human visual system. Second, the existing RIQA datasets only contain binary labels (i.e., ‘Accept’ and ‘Reject’), which is a coarse grading standard for complex clinical diagnosis. Third, the RIQA community lacks a large-scale dataset, which limits the development of RIQA related methods, especially for deep learning techniques, since these require large amounts of training data.
To address the above issues, in this paper, we discuss the influences on RIQA of different color-spaces in deep networks. We first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images selected from the EyePACS dataset, using a three-level quality grading system (i.e., ‘Good’, ‘Usable’ and ‘Reject’). Our EyeQ dataset considers the differences between ophthalmologists and automated systems, and can be used to evaluate other related works, including quality assessment methods, the influence of image quality on disease diagnosis, and retinal image enhancement. Second, we analyze the influences on RIQA of different color-spaces, and propose a general Multiple Color-space Fusion Network (MCF-Net) for retinal image quality classification. Our MCF-Net utilizes multiple base networks to jointly learn image representations from different color-spaces and fuses the outputs of all the base networks, at both a feature-level and prediction-level, to produce the final quality grade. Experiments demonstrate that our MCF-Net outperforms the other deep learning methods. In addition, we also apply the EyeQ dataset to evaluate the performances of DR detection methods for images of various qualities.
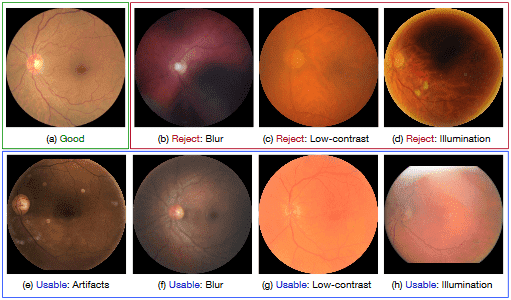
Fig. 1: Examples of different retinal image quality grades. The images of ‘Good’ quality (a) provide clear diagnostic information, while the images of ‘Reject’ quality (b-d) are insufficient for reliable diagnosis. However, some images are between ‘Good’ and ‘Reject’ (e-h), having some poor-quality indicators, but the main structures (e.g., disc and macular regions) and lesion are clear enough to be identified by ophthalmologists.
2 Eye-Quality Dataset
There are several publicly available RIQA datasets with manual quality annota- tions, such as HRF [7], DRIMDB [13], and DR2 [11]. However, they have various drawbacks. First, the image quality assessment of these datasets is based on binary labels, i.e., ‘Accept’ and ‘Reject’. However, several images fall somewhere between these two categories. For example, some retinal images of poor-quality, e.g., containing a few artifacts (Fig. 1 (e)), or slightly blurred (Fig. 1 (f)), are still gradable by clinicians, so should not be labeled as ‘Reject’, but they may mislead automated medical analysis methods, so can also not be labeled as ‘Accept’. Second, retinal images of the existing RIQA datasets are often captured by the same camera, which can not be used to evaluate the robustness of RIQA methods against various imaging modalities. Third, the existing datasets are limited in size, and there lacks a large-scale quality grade dataset for developing deep learning methods.
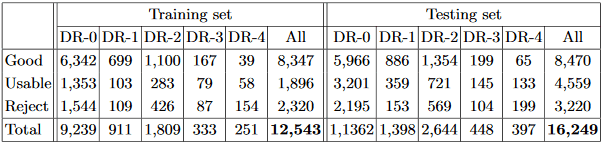
Table 1: Summary of our EyeQ dataset, where DR-i denotes the DR presence on grade i based on the labels in EyePACS dataset.
To address the above issues, in this paper, we re-annotate an Eye-Quality (EyeQ) dataset from the EyePACS dataset, which is a large retinal image dataset captured by different models and types of cameras, under a variety of imaging conditions. Our EyeQ dataset utilizes a three-level quality grading system by considering four common quality indicators, including blurring, uneven illumination, low-contrast, and artifacts. Our three quality grades are defined as:
- –‘Good’ grade: the retinal image has no low-quality factors, and all retinopa- thy characteristics are clearly visible, as shown in Fig. 1 (a).
- –‘Usable’ grade: the retinal image has some slight low-quality indicators, which can not observe the whole image clearly (e.g., low-contract and blur) or affect the automated medical analysis methods (e.g., artifacts), but the main structures (e.g., disc, macula regions) and lesion are clear enough to be identified by ophthalmologists, as shown in Fig. 1 (e-h). For the uneven illumination case, the readable region of fundus image is larger than 80%.
- –‘Reject’ grade: the retinal image has a serious quality issue and cannot be used to provide a full and reliable diagnosis, even by ophthalmologists, as shown in Fig. 1 (b-d). Moreover, the fundus image with invisible disc or macula region is also be treated as ‘Reject’ grade.
To re-annotate the EyeQ dataset, we asked two experts to grade the quality of images in EyePACS. Then, the images with ambiguous labels were discarded, yielding a collection of 28,792 retinal images. A summary of this EyeQ dataset is given in Table 1. Note that some images with ‘Reject’ grades still have DR grade labels from the EyePACS dataset. The reason is that our quality standard is based on the diagnosability for general eye diseases, such as glaucoma, AMD, etc., rather than only DR. Although some low-quality images have visible lesions for DR diagnosis, they are not of high enough quality for diagnosing other diseases, lacking, for example, clear views of optic disc and cup regions for glaucoma screening, or visible macula regions for AMD analysis.
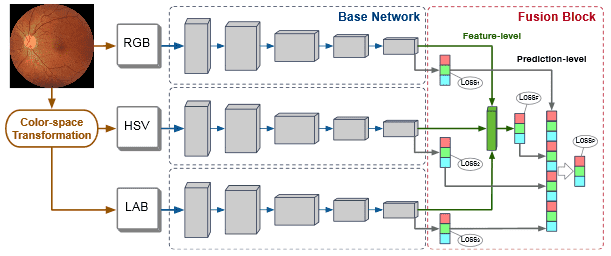
Fig. 2: The architecture of our MCF-Net, which contains multiple base networks for different color-spaces. A fusion block is employed to integrate the multiple outputs of these base networks on both feature-level and prediction-level.
3 Multiple Color-space Fusion Network
Recently, deep learning techniques have been shown to obtain satisfactory performances in retinal image quality assessment [17, 18]. However, these methods only focus on the RGB color-space, and ignore other color-spaces that included in the human visual system. A color-space identifies a particular combination of the color model and the mapping function. Different color-spaces represent different characteristics, and can be used to extract diverse visual features, which have been demonstrated to affect the performances of deep learning networks [9]. In this paper, we analyze the influences of different color-spaces on the RIQA task, and propose a general Multiple Color-space Fusion Network (MCF-Net) to integrate the representations of various color-spaces. Besides the original RGB color-space, we also consider HSV and LAB color-spaces, which are widely used in computer vision tasks and are obtained through nonlinear conversions from the RGB color-space.
Fig. 2 illustrates the architecture of our MCF-Net. The original RGB image is first transferred to HSV and LAB color-spaces, and fed into the base networks. The base networks generate image features by employing multi-scale CNN layers. Then, a fusion block is used to combine the output of each base network at both a feature-level and prediction-level. First, the feature maps from the base networks are concatenated and input to a fully connected layer to generate a feature-level fusion prediction. Then, the predictions of all the base networks and feature-level fusion are concatenated and fed into a fully connected layer to produce the final prediction-level fusion result. Our two-level fusion block guarantees the full integration of the different color-spaces. On the other hand, our fusion block also maintains the independence and integrity of the base networks, which enables any deep network to be implemented as the base network. Different from existing deep fusion networks, which only use the loss function of the last layer to train the whole model, our MCF-Net retains all loss functions of the base networks, to improve their transparency for each color-space, and combines them with the fusion loss of the last layer, as:
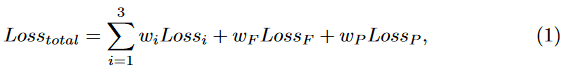
where Lossi, LossF and LossP denote the multi-class cross-entropy loss func- tions of the base networks and the two-level fusion layers, respectively. wi, wF and wm are trade-off weights, which are set to wi = 0.1, wF = 0.1 and wm = 0.6 to highlight the final prediction-level fusion layer.
4 Experiments
Implementation Details: For each input image, we first detect the retinal mask using the Hough Circle Transform, and then crop the mask region to reduce the influence of black background. Finally, the image is resized to 224 224 and normalized to [ 1, 1], before being fed to our MCF-Net. For data augmentation, we apply vertical and horizontal flipping, random drifting and rotation. The initial weights of the base networks are loaded from pre-trained models based on ImageNet, and the parameters of the final fully connected layer are randomly initialized. Our model is optimized using the SGD algorithm with a learning rate of 0.01. The framework is implemented on PyTorch.
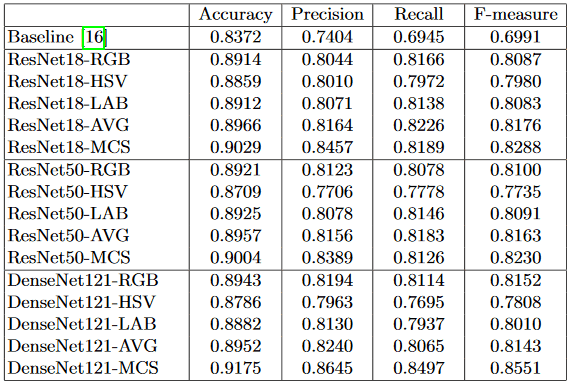
Experimental Settings: Our EyeQ dataset is divided into a training set (12,543 images) and a testing set (16,249 images), following the EyePACS settings, as shown in Table 1. We evaluate our MCF-Net utilizing three state-of-the-art networks: ResNet18 [5], ResNet50 [5], and DenseNet121 [6]. For each base network, we compare our MCF-Net in terms of the network with individual color-space (i.e., RGB, HSV and LAB). We also report the average result (AVG) when combining the predictions of the three color-spaces directly, without the fusion block. For the non-deep learning baseline, we implement the RIQA method from [16], which is based on three visual characteristics (i.e., multi-channel sensation, just noticeable blur, and the contrast sensitivity function) and an SVM classifier with a radial based function. For evaluation metrics, we employ average accuracy, precision, recall, and F-measure  .
.
Results and Discussion: The performances of different methods are reported in Table 2. We can make the following observations: (1) The performance of the non-deep learning baseline [16] is obviously lower than those of deep learning based methods. This is reasonable because deep learning can extract highly discriminative representations from the retinal images directly, using multiple CNN layers, which are superior to the hand-crafted features in [16] and lead to better performance. (2) For the different color-spaces, the networks in RGB and LAB color-spaces perform better than that in HSV color-space. One possible reason is that the RGB color-space is closer to the raw data captured from the camera, and thus a more natural way to represent image data. Another possible reason is that the model pre-trained on ImageNet are based on RGB color-space, which is more suitable for fine-tuning in the same color-space. The LAB color- space represents the lightness and color components of greenred and blueyellow. The lightness channel directly reflects the illustration status of images, which is the main quality indicator for retinal images. (3) Combinations of different color-spaces, even the simple average fusion (AVG), perform better than those of individual color-space. (4) Our MCF-Net outperforms the models with an in- dividual color-spaces and average fusion. This demonstrates that the multi-level fusion block can produce a stable improvement to benefit the quality assessment task. Moreover, for deep learning models, DenseNet121-MCF obtains the best performance, outperforming ResNet18-MCF and ResNet50-MCF.
Table 2: Performances of different methods on test set.
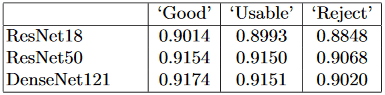
DR Detection in Different-quality Images: In this paper, we also apply our EyeQ dataset to evaluate the performances of DR detection methods for different-quality images. We train three deep learning networks, e.g., ResNet-18 [5], ResNet-50 [5] and DenseNet-121 [6], on the whole EyePACS training set, and evaluate their performances on images of different quality. Table 3 shows the accuracy scores of the DR detection models. As expected, the performances of the methods decrease along with the quality degradation of the images. The accuracy scores of ResNet-18 [5], ResNet-50 [5] and DenseNet-121 [6] decrease by 0.21%, 0.04%, and 0.23%, respectively, from ‘Good’ to ‘Usable’, and by 1.45%, 0.82%, and 1.31% from ‘Usable’ to ‘Reject’. Note that since we train the DR detection methods on the whole EyePACS training set, which includes different quality images, the networks are somewhat robust to poor-quality images. However, poor-quality images still pose challenges for automated diagnosis systems, even for the images labeled as ‘Usable’, which could provide diagnosable information to ophthalmologists.
Table 3: Accuracy score of DR detection methods on different-quality images.
5 Conclusion
In this paper, we have constructed an Eye-Quality (EyeQ) dataset from the EyePACS dataset, with a three-level quality grading system (i.e., ‘Good’, ‘Us- able’ and ‘Reject’). Our EyeQ dataset has the advantages of a large-scale size, multi-level grading, and multi-modality. Moreover, we have also proposed a general Multiple Color-space Fusion Network (MCF-Net) for retinal image quality classification, which integrates different color-spaces. Experiments have demonstrated that MCF-Net outperforms other methods. In addition, we have also shown that image quality affects the performances of automated DR detection methods. We hope our work can draw more interest from the community to work on the RIQA task, which plays a critical role in applications such as retinal image segmentation [3, 4], and automated disease diagnosis [2].
References
1. Cheng, J., et al.: Structure-Preserving Guided Retinal Image Filtering and Its Ap- plication for Optic Disk Analysis. IEEE Transactions on Medical Imaging 37(11), 2536–2546 (nov 2018)
2. Fu, H., et al.: Disc-Aware Ensemble Network for Glaucoma Screening From Fundus Image. IEEE Transactions on Medical Imaging 37(11), 2493–2501 (2018)
3. Fu, H., et al.: Joint Optic Disc and Cup Segmentation Based on Multi-Label Deep Network and Polar Transformation. IEEE Transactions on Medical Imaging 37(7), 1597–1605 (2018)
4. Gu, Z., et al.: CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Transactions on Medical Imaging (2019)
5. He, K., et al.: Deep Residual Learning for Image Recognition. In: CVPR. pp. 770– 778 (2016)
6. Huang, G., et al.: Densely connected convolutional networks. In: CVPR. pp. 2261– 2269 (2017)
7. Khler, T., et al.: Automatic no-reference quality assessment for retinal fundus im- ages using vessel segmentation. In: IEEE International Symposium on Computer-Based Medical Systems. pp. 95–100 (2013)
8. MacGillivray, T.J., et al.: Suitability of UK Biobank retinal images for automatic analysis of morphometric properties of the vasculature. PLoS ONE 10(5), 1–10 (2015)
9. Mishkin, D., et al.: Systematic evaluation of convolution neural network advances on the imagenet. Computer Vision and Image Understanding 161, 11–19 (2017)
10.Niemeijer, M., et al.: Image structure clustering for image quality verification of color retina images in diabetic retinopathy screening. Medical Image Analysis 10(6), 888–898 (2006)
11. Pires, R., others.: Retinal image quality analysis for automatic diabetic retinopathy detection. In: SIBGRAPI Conference on Graphics, Patterns and Images. pp. 229– 236 (2012)
12. Pires Dias, J.M., et al.: Retinal image quality assessment using generic image quality indicators. Information Fusion 19, 73–90 (2014)
13. Sevik, U., et al.: Identification of suitable fundus images using automated quality assessment methods. Journal of Biomedical Optics 19(4), 1–11 (2014)
14. Shao, F., et al.: Automated Quality Assessment of Fundus Images via Analysis of Illumination, Naturalness and Structure. IEEE Access 6, 806–817 (2017)
15. Tobin, K.W., et al.: Elliptical local vessel density: A fast and robust quality metric for retinal images. In: EMBC. pp. 3534–3537 (2008)
16. Wang, S., et al.: Human Visual System-Based Fundus Image Quality Assessment of Portable Fundus Camera Photographs. IEEE Transactions on Medical Imaging 35(4), 1046–1055 (2016)
17. Yu, F., et al.: Image quality classification for DR screening using deep learning. EMBC pp. 664–667 (2017)
18. Zago, G.T., et al.: Retinal image quality assessment using deep learning. Computers in Biology and Medicine 103, 64–70 (2018)