
Abstract
Introduction
The amount of visual information, generated by the users of the internet, is growing constantly. The reason for this is widespread of mobile devices equipped with high-quality digital cameras and the rise of popularity of image sharing services. Between 2013 and 2017 the number of photos taken yearly has increased by about twice and reached 1.2 trillion [1]. The total number of digital photos stored by 2017 is estimated to be 4.7 trillion. There is no doubt this number is going to continue to rise.
The search in such a large database is a complex and challenging task, requiring performant indexing and retrieval algorithms along with the programs implementing these algorithms. As of today, the metainformation (description, geotags, usage context, etc.) plays a key role in many commercial visual information search engines. This metainformation can be absent or be pf poor quality. For this reason, there exists a problem of developing the search engine capable of information retrieval based on the information contained in the image itself.
Goals and tasks of the research, the expected results
The goal if this research is to develop a context-based image retrieval algorithm and it's implementation.
The program model that is being developed in this thesis is an information retrieval system that uses query-by-example approach meaning the query provided by the uses is an image and the result of the retrieval process is a set of images similar to the request.
The primary tasks of the research are:
- the analysis of existing general-purpose information retrieval methods and retrieval systems working with visual information;
- the analysis of existing indexing methods and images retrieval methods, their pros and cons;
- the development of the retrieval system architecture;
- the implementation of the information retrieval system software model according to the architecture specification;
- the development of the test case database for quality assurance;
- the retrieval algorithm development, its implementation, and comparison with existing algorithms;
- optimization of the algorithm, architecture, software model and its parameters.
As a subject area, the retrieval of urban photographs was chosen.
Participation in scientific and technical conferences is planed to test the results of the study.
The article Color space quantization in the context in content-based image retrieval
[2] was presented on the 2nd scientific and practical conference Software Engeneering: methods and techologies for development of Information Computer Systems
(SEICS-2018). It contains the description of existing image retrieval methods.
Literature review
Content-based image retrieval methods (CBIR) are an area of active research from a theoretical standpoint (development and evaluation of the feature extraction methods, indexing methods, retrieval methods) and a practical one (algorithm implementation, the choice of data structures, etc.)
International sources review
The first commercial system that used content-based retrieval methods was QBIC described in [3]. In this publication, the authors described the general structure of a CBIR-system. They also suggested three kinds of features for indexing: color features, texture features, and shape features.
These three approaches to computing the feature vector have since been improved significantly. For example, the article [4] describes the usage of the multidimensional feature histogram (computed from color, edge density, texture, gradient value, and others), which improved the performance. Histogram based methods are based on the computing the feature histogram from all pixels of the image or their subset. The image similarity is defined as a distance in the histogram space. To compute the distance one may use traditional metrics such as euclidean or xi-squared or more specialized ones [5].
While color features use the information about the color of a pixel, the neighboring pixels are considered when constructing a texture feature [6].
Another approach to computing the feature vector has emerged with the development of the local descriptors. The first such descriptor is SIFT, described in [7]. The idea behind this class of methods is to compute a vector for each key point. This vector can consist of real or boolean values. The key points are extracted based on their neighborhood. It is assumed that the same set of key points will be generated even from a distorted image.
SIFT and other local descriptors have many applications such as image matching, image classification, and image retrieval. Article [8] describes the CBIR-system that uses SIFT local features. The authors suggest the Earth Mover's Distance function as a similarity measure.
Shortly after the appearance of SIFT, many other local descriptors have been developed. They use different algorithms for key points extraction and feature vector generation. These descriptors are SURF, KAZE, AKAZE, ORB, BRISK, and others. The article [9] contains their brief description along with a quantitative evaluation of their performance for image matching. According to the presented results, ORB [10] descriptor is the most performant. This is a binary local descriptor that uses FAST keypoint detector and modified rotation invariant BRIEF algorithm for result vector generation (figure 1).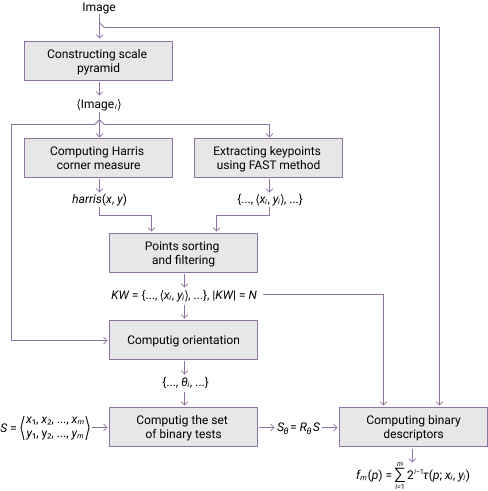
ORB can be used in the retrieval system as shown in [11]. The authors used the bag of words approach to generate the compact representation of the image. It is not possible to use the set of descriptors as a feature vector due to the high number of dimensions of the ORB descriptor (256 bits) and a large number of key points. Instead, the bag of word
approach is used (sometimes called bag of visual words
or bag of features
).
Recently an approach based on the usage of artificial neural networks has risen in popularity. The results of the image retrieval competition held by Google in the spring of 2019 [13] can serve as a result. Both teams who took the first and the second place [14; 15] used the combination of different models of convolutional neural networks for feature vector generation. Despite the uses of neural networks, they require a large number of computational resources and a large training dataset.
The preprocessing step, specifically segmentation step, is often employed in the retrieval systems. The article [16] demonstrates the effectiveness of a segmentation step using fixed regions with fizzy borders. The authors of the article [17] suggest the using of statistical moments for each region as a feature vector. The k-means algorithm is used for the segmentation stage.
Along with k-means there exist other general-purpose segmentation algorithms such as Watershed [18], Felzenszwalb [19], SLIC [20]. There are also specialized algorithms for example, the algorithm described in [21] can be used to separate facades of buildings.
National sources review
Content-based image retrieval methods have also been a focus of some researchers in Ukraine and Russia, although there have been much fewer publications from these countries compared to works written in English.
One such publication is the article [22]. It describes the process of image retrieval from related graphical files. The authors suggest using a hypergraph with images as nodes instead of a traditional approach with using image clusterization into non-intersecting subsets. A hypergraph is a special kind of graph with edges connecting some arbitrary non-empty subset of images.
The article [23] is also worth noting. The authors propose using segmentation into rectangular regions as a preprocessing stage. Segmentation uses volume under a surface in a color intensity space. The extracted regions are merged into clusters that are inserted into the index.
Local sources review
The topic of image retrieval is also present in the works of masters and workers of Donetsk Technical National University.
Among the works of the DonNTU masters published on their websites, there are several that should be noted. M. Pohil (graduated in 2008) described the traditional approaches in the field of content-based image retrieval. D. Telezhkin (graduated in 2007) describes the goal of image retrieval, the process of feature extraction. S. Lukyanov (graduated in 2005) considers the problem of CBIR-system quality evaluation.
There are also DonNTU masters D. Savchenko (2010), M. Kormarychev (2012), and V. Mikhalets (2007) who worked on image segmentation—the key component of some retrieval systems.
Some DonNTU professors published works concerning image retrieval processes. Specifically, in publication [24] authors propose using color-based feature histograms with clusterization. Publication [25] describes a method of reducing redundant results of the retrieval process using multisets.
There are multiple publications published by E. Bashkov, O. Vovk, and N. Kostukova dedicated to image retrieval from graphical databases. The monograph "Content-based image retrieval in graphical databases" [26] is among these works.
Conent-based image retrieval system architecture
The operation of many modern CBIR-systems consists of two computational stages. During the first offline stage, the system processes the images and builds the index, and therefore cannot respond to user queries. During the second online stage, the system is interactive. It handles users' requests and generates search results sorted by relevancy.
Figure 2 shows the stages of a typical image retrieval system [27].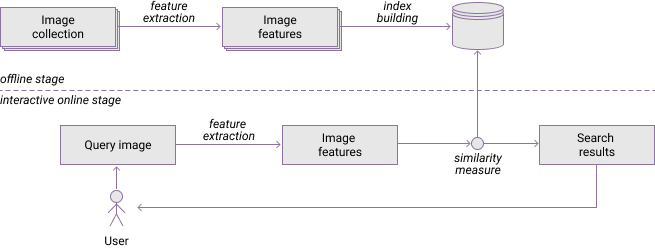
During the offline stage, the system processes the images from the collection extracts the feature vectors. These features are much smaller than the source images and therefore are simpler to use during the retrieval process. Feature vectors are used for building the index. K-d trees [28], hash functions [29], special kinds of an inverted index [30], or other methods can be employed for this task.
The process of handling the user request during an online stage is similar. The features are extracted from the query image and they are used for retrieving similar images from the index. The special kind of function—a similarity measure is used to determine the similarity between images.
The program model that will be built during the work on this thesis is going to use a microservice architecture [32]. According to this approach, an application is split into a set of components with limited functionality and responsibility that have a clearly defined interface. Each of these components can be used on one system or different networked computers.
Components in a microservice architecture can interact directly via IPC capabilities of TCP/IP, for instance, using HTTP protocol, or using a message broker.
The advantages of microservice architecture are simple horizontal scaling (the number of running service instances can be automatically adjusted) and fault tolerance (in case of the fatal fault of the service it will be automatically restarted, messages in the queue are going to be processed again). Microservice architecture has been successfully employed in high-load video and image processing systems [32].
Figure 3 shows the components of the proposed architecure and their communication. The animation shows the process of handling the user query and information passed between components. It is assumed that request has not been processed early and the retrieval results are not in cache.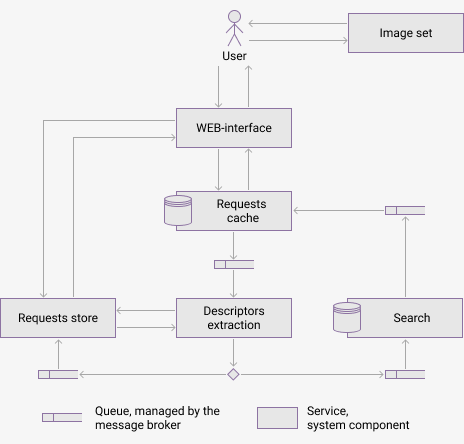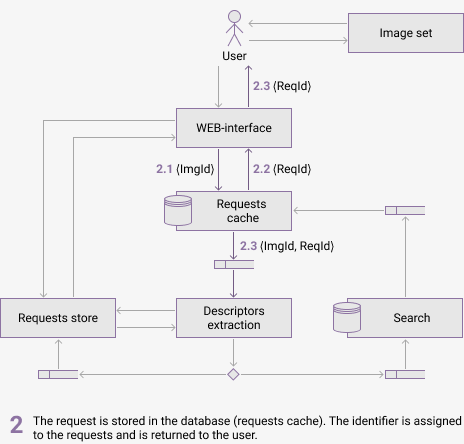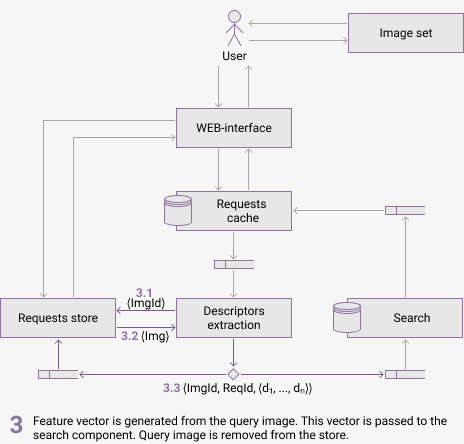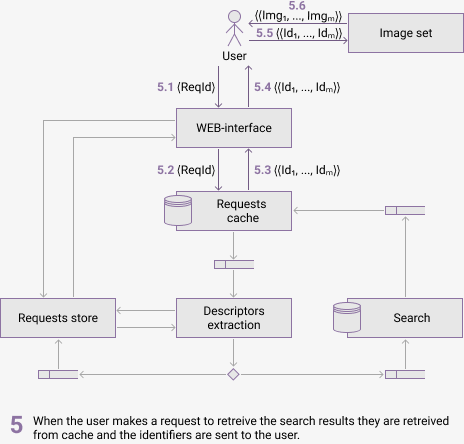
(animation, delay 3 sec, 6 frames, 5 repeats, 81.6 kB)
The following software has been chosen for the system implementation: Docker for component containerization and orchestration, RabbitMQ as a message broker, MongoDB as a non-relational database for images, cache and feature vectors.
Conclusions
Content-based image retrieval is a complex and relevant task. It is complex because it is hard to formalize the requirements for the system that tries to minimize the semantic gap
—the difference in similarity as perceived by the human user and as computed by the computer.
During the work on this master's thesis, the image retrieval system will be created. This system is going to use the search-by-example approach to image retrieval. The topics of compact image representation, image construction, and performant retrieval procedures are going to be addressed in the thesis.
Bibliography
- Erric Perret. Here’s How Many Digital Photos Will Be Taken in 2017 [Электронный ресурс]. — URL: https://focus.mylio.com/tech-today/heres-how-many-digital-photos-will-be-taken-in-2017-repost-oct (дата обращения: 04.11.2019).
- Полетаев В. А. Квантование цветового пространства в контексте решения задачи поиска изображений по содержанию / В. А. Полетаев, И. А. Коломойцева // Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС-2018): сборник научных трудов II научно-практической конференции (студенческая секция), Том 2 / Донец. национал. техн. ун-т; — Донецк, 2017. — С. 96–101.
- The QBIC Project: Querying Images by Content Using Color, Texture, and Shape. The QBIC Project / T.J.W.I.R. Center [et al.]. — IBM Thomas J. Watson Research Division, 1993. — 20 p.
- Pass G. Comparing images using joint histograms / G. Pass, R. Zabih // Multimedia Systems. — 1999. — Vol. 7. — № 3. — P.—234–240.
- A Comparison on Histogram Based Image Matching Methods / W. Jia [и др.] // 2006 IEEE International Conference on Video and Signal Based Surveillance. — Sydney, Australia, 2006.
- A comparative study of texture measures with classification based on feature distributions / M. Pietikainen [и др.] // Pattern Recognition. — 1996. — Т. 29. — С. 51–59.
- Lowe D. G. Distinctive Image Features from Scale-Invariant Keypoints / D. G. Lowe // International Journal of Computer Vision. — 2004. — Vol. 60. — № 2. — P.—91–110.
- Jurandy Almeida. SIFT applied to CBIR / Jurandy Almeida, Ricardo da S Torres, Siome Goldenstein // Revista de Sistemas de Informacao. — 2009. — P.—41–48.
- Tareen S.A.K. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK / S.A.K. Tareen, Z. Saleem. — 2018.
- ORB: An efficient alternative to SIFT or SURF / E. Rublee [et al.] // 2011 International Conference on Computer Vision 2011 IEEE International Conference on Computer Vision (ICCV). — Barcelona, Spain: IEEE, 2011. — ORB.
- Ma L. Fast Retrieval on Remote Sensing Imagery Based On ORB Feature / L. Ma, B. Jiang, Z. Xu // International Journal of Management and Applied Science. — 2018. — Vol. 4. — № 1. — P.—4.
- O’Hara S. Introduction to the Bag of Features Paradigm for Image Classification and Retrieval / S. O’Hara, B. Draper. — 2011.
- Google Landmark Recognition 2019 // Kaggle [Электронный ресурс]. — URL: https://kaggle.com/c/landmark-recognition-2019 (дата обращения: 04.11.2019).
- Ozaki K. Large-scale Landmark Retrieval/Recognition under a Noisy and Diverse Dataset / K. Ozaki, S. Yokoo // arXiv:1906.04087 [cs]. — 2019.
- 2nd Place and 2nd Place Solution to Kaggle Landmark Recognition andRetrieval Competition 2019 / K. Chen [и др.] // arXiv:1906.03990 [cs]. — 2019.
- Stricker M. Spectral covariance and fuzzy regions for image indexing / M. Stricker, A. Dimai // Machine Vision and Applications. — 1997. — Vol. 10. — № 2. — P.—66–73.
- Using Image Segmentation in Content Based Image Retrieval Method / M. Ouhda [и др.] // Lecture Notes in Networks and Systems. — 2018. — С. 179–195.
- Kaur A. Image Segmentation Using Watershed Transform / A. Kaur // International Journal of Soft Computing and Engineerin. — 2014. — Vol. 4. — № 1. — P.—4.
- Felzenszwalb P. F. Efficient Graph-Based Image Segmentation / P. F. Felzenszwalb, D. P. Huttenlocher // International Journal of Computer Vision. — 2004. — Vol. 59. — № 2. — P.—167–181.
- SLIC Superpixels Compared to State-of-the-Art Superpixel Methods / R. Achanta [et al.] // IEEE Transactions on Pattern Analysis and Machine Intelligence. — 2012. — Vol. 34. — № 11. — P.—2274–2282.
- Hernandez J. Morphological segmentation of building façade images / J. Hernandez, B. Marcotegui // 2009 16th IEEE International Conference on Image Processing (ICIP) 2009 16th IEEE International Conference on Image Processing (ICIP 2009). — Cairo: IEEE, 2009. — P.—4029–4032.
- Воробжанский Н. Н. Алгоритмы поиска изображений по содержанию с использованием нечеткого гиперграфа: Системный анализ и информационные технологии / Н. Н. Воробжанский // Вестник ВГУ. — 2016. — № 2. — С. 85–91.
- Р. Мельник. Пошук образів за індексами кластерів фрагментів зображень / Р. Мельник, Ю. Каличак // Вісник Національного університету
Львівська політехніка
. — 2011. — № 719: Комп’ютерні науки та інформаційні технології. — С. 262–269. - Пошук кольорових зображень з використанням методів гістограмних ознак і кластеризації / О. Л. Вовк [и др.]. — 2008.
- Башков Е. А. Исследование возможностей использования математического аппарата мультимножеств при контекстном поиске изображений в базах данных / Е. А. Башков, О. Л. Вовк, Н. С. Костюкова // Донбас—2020: перспективи розвитку очима молодих вчених: Матеріали V науково-практичної конференції. м. Донецьк, 25–27 травня 2010 р. — Донецьк, ДонНТУ Міністерства освіти і науки, 2010. — С. 973.
- Башков Е. А. Поиск изображений по содержимому в графических базах данных [Текст] : монография / Е. А. Башков, О. Л. Вовк, Н. С. Костюкова. — Донецк : ГВУЗ
ДонНТУ
, 2014. — 120 с. - Aber Esa A M Alomairi. An overview of content-based image retrieval techniques / Aber Esa A M Alomairi, G. Sulong // Journal of Theoretical and Applied Information Technology. — 2016. — Т. 84. — № 2. — С. 215–223.
- Beis J. S. Shape indexing using approximate nearest-neighbour search in high-dimensional spaces / J. S. Beis, D. G. Lowe // Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition IEEE Computer Society Conference on Computer Vision and Pattern Recognition. — San Juan, Puerto Rico: IEEE Comput. Soc, 1997. — P.—1000–1006.
- Lamdan Y. Geometric Hashing: A General and Effective Model-Based Recognition Scheme / Y. Lamdan, H. Wolfson // Proceedings ICCV ’88. — Tampa, Florida, USA, 1988. — С. 238–249.
- Поиск изображений по визуальному подобию с применением инвертированных индексов цветовых гистограмм / И. В. Соченков [и др.] // Информационные технологии и вычислительные системы. — 2015. — С. 86–94.
- Microservices: How To Make Your Application Scale. Microservices / N. Dragoni [и др.]. — 2017.
- M. Sc. Michel Krämer. A Microservice Architecture for the Processing of Large Geospatial Data in the Cloud / M. Sc. Michel Krämer. — 2017.