Обнаружение и отслеживание пешеходов в режиме реального времени на CCTV с использованием глубоких сверточных нейронных сетей
Авторы: Debaditya Acharya, Kourosh Khoshelham, Stephan Winter
Автор перевода: А.А. Велиева Источник: Conference: Proc. of the 4th Annual Conference of Research@Locate, At Sydney, Australia, Volume: 1913/Infrastructure Engineering, The University of Melbourne/April 2017, 31–36 [Ссылка]
Аннотация:
В работе рассматривается использование сверточных нейронных сетей для автоматизации процесса извлечения признаков из изображений с камер видеонаблюдения. Полученные значения служат прочной основой для различных задач распознавания объектов и используются для решения проблемы отслеживания. Подход заключается в том, что извлечённые признаки отдельных обнаружений соответсвуют в последующих кадрах, таким образом происходит соответствие обнаружений мужду несколькими кадрами. Разработанная структура способная решать такие проблемы, как загромождение сцен, изменение освещения, теней и отражений, изменение внешности и частичные окклюзии. Фреймворк способен генерировать результаты обнаружения о отслеживания со скоростью четыре кадра в секунду.
1 Введение
Отслеживание пешеходов приобрело значительный интерес в последние два десятилетия. Повышенный интерес обусловлен наличием качественных недорогих камер видеонаблюдения и необходимостью автоматизированного видеоанализа. Распознавание действий человека в реальных условиях находит применение в интеллектуальном видеонаблюдении, анализе поведения покупателей (Chen et al., 2016), национальной безопасности, профилактике преступности, больниц, уход за пожилыми людьми и детьми (Wang, 2013) и могут быть использованы для управления общественными местами и обработки чрезвычайных ситуаций.
Существует большое количество литературы (Yilmaz et al., 2006; Smeulders et al., 2014), следующей традиционной парадигме распознавания образов, включающее вручную извлечение объектов интереса (предопределенные функции, такие как гистограмма ориентированные градиенты (HOG)) для обнаружения пешеходов в сцене и их последующей классификации, используя классификаторы. Недостатком использования таких функций для задачи отслеживания является ограниченная возможность функций для адаптации к вариациям внешнего вида объекта, которые являются сложными, нелинейными и изменяющийся во времени (Yilmaz et al., 2006; Chen et al., 2016). Кроме того, для достижения точного распознавания, основные проблемы, которые необходимо решить, включают в себя окклюзии, загроможденные фоны, вариации точек зрения, изменения по внешнему виду (масштабу, позе и форме), сходству появляющихся пешеходов, изменения освещенности и непредсказуемости характера движения пешехода (Ji et al., 2013; Chen et al., 2016). Тем не менее, большинство современных трекеров являются недостаточными для решения конкретных задач (Feris et al., 2013). Повторная идентификация пешеходов (при просмотре в одной или нескольких камерах) все еще остается открытой проблемой.
В данной работе пешеходы обнаруживаются в каждом кадре изображений CCTV с использованием современных средств обнаружения объектов–фреймворка Faster R-CNN (Ren et al., 2015). В дальнейшем, чтобы преодалеть ограничения при извлечени признаков вручную, при обнаружении пешехода выполняется автоматическое извлечение признаков с помощью глубоких сверточных нейронных сетей (CNNs). Donahue и другие (2014) утверждают, что активация нейронов в последних слоях CNN служит сильными функциями для различных задач распознавания объектов. Гипотеза, лежащая в основе этой работы, заключается в том, что извлеченные активации из последних слоев CNN могут использоваться для различия обнаруженных пешеходов по кадрам и могут использоваться для точного решения проблемы отслеживания по обнаружению. Итак, функции используются по-новому для решения проблемы отслеживания. Отслеживание формулируется как соответствие обнаружений между несколькими кадрами и достигается путем сопоставления извлеченных признаков отдельных обнаружений в последующих кадрах. Основные достижения:
- Разработана основа для обнаружения и отслеживания пешеходов в реальном времени с использованием CNNs
- Разработан новый алгоритм для установления соответствия между обнаружениями по кадрам
Разработка решает такие проблемы, как частичная окклюзия, вариации освещения, изменения позы, форма и масштаб пешеходов, загроможденные фоны и полные окклюзии в течение коротких периодов. Алгоритм не в состоянии справиться с тотальными окклюзиями длительных периодов и не решает проблему наличия явлений подобных лиц в одном кадре.
2 Соответствующая работа
Трекинг определяется как создание траектории движения объекта в плоскости изображения и присваивает правильные значения метки к отслеживаемым объектам в разных кадрах видео.Существует три основных аспекта отслеживания движения пешехода, аналогичное отслеживанию объектов: 1)обнаружение пешехода в видеокадре,2) отслеживание, 3) анализ треков для указанной цели (Yilmaz et al., 2006 г.). В литературе, для детекторов точек обнаружения объектов, были использованы методы вычитания фона, сегментация и методы контролируемого обучения. Важную роль для точного отслеживания играет выбор подходящих функций, связаный с представлением объекта. Впоследствии выполняется задача установления соответствия обнаружений. Это было сделано в прошлом с использованием детерминированных или вероятностных моделей движения ядра на основе внешнего вида отслеживаемой модели. Кроме того, были предложены онлайн методы адаптации, которые адаптируют детекторы для обработки изменения внешнего вида отслеживаемых объектов с течением времени. Детекторы обучаются и обновляются в режиме онлайн, однако во время отслеживания они обычно требуют большого количества экземпляров для обучения, что в свою очередь может отсутствовать.
В последнее время наблюдается значительное повышение производительности в области классификациии и распознавании категорий изображений путем обучения глубокой CNN с миллионами изображений разных классов (Крижевский и др., 2012). CNNs (Lecun и соавт., 1998) – это метод машинного обучения, который использует локальную пространственную информацию в изображении и изучает иерархию все более сложных объектов, тем самым автоматизируя процесс построения объектов. CNN относительно нечувствительны к определенным вариациям входных данных (Ji et al., 2013).
Мотивированные успехом классификации и распознавания изображений, предпринимались попытки использовать полезность глубокого CNN для задач отслеживания. Fan et al.(2010) разработали CNN с трекером shift. Функции изучаются во время автономного обучения, которое извлекает как пространственную, так и временную информацию с помощью рассматриваемой пары изображений не из одного кадра, а из двух последовательных. Трекер извлекает локальные и глобальные признаки для решения частичных окклюзий и изменения взглядов. Ji и соавторы (2013) используют 3D модель CNN для распознавание действий пешеходов. Модель извлекает объекты из пространственных и временных измерений путем выполнения трехмерных сверток и захватывает информацию о движении в нескольких кадрах. Ji и соавторы (2013) ввели глубокие CNN для задачи отслеживания, которые извлекают объекты и преобразуют изображения в векторы высокой размерности. Доверительная карта создается путем вычисления сходства двух совпадений с помощью радиальной базисной функции. Hong и др. (2015) предлагают использовать выходы из последнего слоя предварительно обученного CNN для изучения дискриминационного внешнего вида модели с использованием онлайн машины опорных векторов (SVM). Впоследствии отслеживание выполняется с помощью последовательной Байесовской фильтрация с целевой картой значимости, которая вычисляется путем обратной проекции выходов из последних слоев. Wang и др. (2015) использовали компоненты, извлеченные из предварительно подготовленных CNN для онлайн отслеживания. CNN настраивается во время онлайн-отслеживания, чтобы скорректировать внешний вид объекта, указанного в первом кадре последовательности, карта вероятности генерируется вместо создания простых меток классов. Wang and Yeung (2013) обучают сложный шумоподавляющий автокодер в автономном режиме и выполняют передачу знаний из автономного обучения в онлайн-процесс отслеживания, чтобы адаптировать изменения внешнего вида движущейся цели. Nam and Han (2015) предлагают алгоритм отслеживания, который изучает независимые от предметной области представления из предварительного обучения и собирает информацию специфичную для предметной области, посредством онлайн-обучения во время отслеживания. Сеть имеет простую архитектуру по сравнению с предыдущей, предназначеной для задач классификации изображений. Вся сеть предварительно обучена в автономном режиме, позже подключается полносвязный слой, включающий один доменный слой настраиваемый в онлайн режиме. Li et al. (2016) предложили новый алгоритм отслеживания, использующий CNN, чтобы автоматически изучить наиболее полезную функцию представления конкретного целевого объекта. Стратегия отслеживания по обнаружению используется для того, чтобы отличить целевой объект от его фона. CNN генерирует оценки всех возможных предположений местоположения объекта в кадре.Трекер обучается на полученных образцах, из текущей последовательности изображений. Chen и др.(2016) обучают CNN, передают изученные параметры для задачи отслеживания и строят модель внешнего вида объекта. Начальное и онлайн обучение используется для обновления внешнего вида модели. Согласно литературе, несмотря на успех CNN, только ограниченное количество алгоритмов отслеживания (рассматривалось выше) используют CNN. Более того, предыдущие работы не интегрировали подход обнаружения и отслеживания одновременно с CNN.
3 Методология
Разработанная структура использует CNN как для обнаружения пешеходов в кадрах, так и для отслеживания. Для обнаружения пешеходов, используется современная система обнаружения объектов, Faster R-CNN (Ren et al., 2015). Признаки, используемые для отслеживания, получены из предварительно обученной CNN (рис. 1) и служат в качестве основы для распознавания объектов. Предложенный алгоритм наиболее близок к отслеживанию ядра на основе внешнего вида, но надежное представление разрабатывается путем наложения весов внешнего вида и пространственной информация.
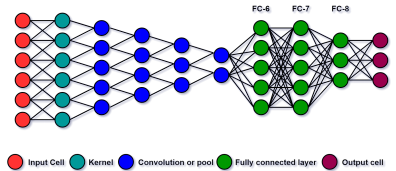
Рисунок 1 – Упрощенная архитектура CNN (автор Krizhevsky и др. (2012)).Полностью подключен-8 (FC-8) слой–это последний слой перед классификацией, из которого извлекаются объекты.

Рисунок 2 – Упрощенная схема работы.
Упрощенная схема фреймворка представлена на рис.2. Кадры видеонаблюдения поступают на вход детектора, который обнаруживает и локализует отдельных пешеходов. Признаки пещеходов извлекаются из кадров видеоизображений,с помощью предварительно обученной CNN. Разработанный алгоритм используется для составления соответствий обнаружений между кадрам, отдельные обнаружения выделяются идентификаторам. Результаты отслеживания отображаются при наложении идентификаторов обнаружений в соответствующих кадрах.
3.1 Описание
Последний слой перед классификационным слоем (FC8) CNN генерирует вектор из 1000 объектов для каждого входного сигнала
изображение. В каждом кадре обнаружения изображается в форме ограничительной рамки вокруг пешеходов. Впоследствии,
обнаружение обрезается и подается в CNN, который генерирует матрицу векторов признаков. Математически это
может быть представлен как уравнение 1, где  обозначает матрицу векторов
признаков i обнаружений для одного кадра k, набор {A(1,i(k)),...A(1000,i(k))} обозначают активации
ith обнаружений в кадре k, и i(k)обозначает число обнаружений в кадре k.
обозначает матрицу векторов
признаков i обнаружений для одного кадра k, набор {A(1,i(k)),...A(1000,i(k))} обозначают активации
ith обнаружений в кадре k, и i(k)обозначает число обнаружений в кадре k.

Центроиды обнаружений могут быть выражены уравнением. 2. Где  обозначает матрицу x и y, координаты центроидов i обнаружений в кадре k.
Соответствие устанавливается путем вычисления признака расстояние и пиксельного расстояние между каждой парой обнаружений в двух последовательных кадрах.
Пусть FVi(k) и FVj(k+1)обозначим соответственно векторы признаков для i и
j обнаружений в кадре k и кадре k+1.
Нормализованное расстояние между двумя обнаружениями Fd(i(k),j(k+1)) выражается в виде уравнения три, где |FV|
обозначает l2 норму вещественного вектора FV. Пусть PCi(k) и PCj(k+1) центроиды для
обнаружений i и j в кадре k и кадре k + 1 соответственно. Аналогичным образом нормализованное расстояние в
пикселях между двумя обнаружениями Pd(i(k),j(k+1)) выражается по формуле 4.
обозначает матрицу x и y, координаты центроидов i обнаружений в кадре k.
Соответствие устанавливается путем вычисления признака расстояние и пиксельного расстояние между каждой парой обнаружений в двух последовательных кадрах.
Пусть FVi(k) и FVj(k+1)обозначим соответственно векторы признаков для i и
j обнаружений в кадре k и кадре k+1.
Нормализованное расстояние между двумя обнаружениями Fd(i(k),j(k+1)) выражается в виде уравнения три, где |FV|
обозначает l2 норму вещественного вектора FV. Пусть PCi(k) и PCj(k+1) центроиды для
обнаружений i и j в кадре k и кадре k + 1 соответственно. Аналогичным образом нормализованное расстояние в
пикселях между двумя обнаружениями Pd(i(k),j(k+1)) выражается по формуле 4.

Матрица расстояний Fd(k+1) для векторов объектов формируется из нормализованных попарных расстояний объектов и представлена уравнением 5. Матрица расстояний для пиксельных расстояний Pd(k+1) генерируется из нормализованных попарных расстояний в пикселях и представлена уравнением 6. Матрицы Fd(k+1) и Pd(k+1) объединяются с использованием весов ω (0 ≤ ω ≤ 1). Результатом комбинации является матрица слежения Td(k+1)), которая представлена уравнением 7. Где ti(k),j(k+1) представляет собой взвешенные сложения Fd(i(k),j(k+1)) и Pd(i(k),j(k+1)).

3.2 Алгоритм
В первом кадре идентификаторы генерируются случайным образом и в дальнейшем отслеживаются в последующих кадрах. Количество сгенерированных идентификаторов в первом кадре равно количеству обнаружений. Для обнаружений в последующих кадрах идентификатор назначается либо из предыдущего кадра (который включает в себя сопоставление на основе критерия минимального расстояния) либо генерируется новый идентификатор (для случая, когда в кадр входит новый человек).
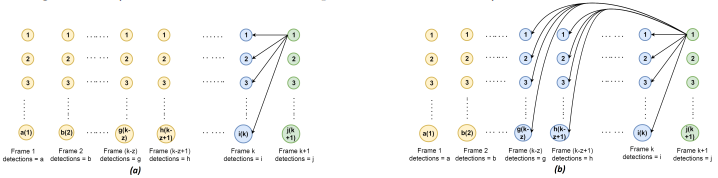
Рисунок 3 – Алгоритм, используемый для соответствия. Зеленый цвет обозначает нераспределенные обнаружения. Синий цвет представляет обнаружение предыдущего кадра / кадров для сравнения. Желтый цвет представляет остальные из обнаружений, которые присутствуют в базе данных.
Пусть множество {t(1,i(k)),...,t(i(k),j(k+1))} обозначает взвешенные расстояния от обнаружения j в кадре k + 1 до всех обнаружений в кадре k. Минимальное значение множества {t(1,i(k)),...,t(i(k),j(k+1))} используется для соответствия j(k+1)th обнаруженного кадра k+1 к 1st,...,i(k)th обнаржунию в кадре k, только в том случае если это минимальное значение ниже порога. Рисунок 3(а) иллюстирует процесс установления соответствий для случая, где обнаружение кадра k+1 сравнивается с i(k) обнаружением кадра k для соответствия. Если минимальное значение установить в {t(1,i(k)),...,t(i(k),j(k+1))} для обнаружения j(k+1) в кадре k+1 выше порогового значения, то никакого соответствия в кадре k выполнятся не будет, но обнаружение будет сравнивается с обнаружениями предыдущих z кадров для установления соответствия. Этот процесс обьясняется на рисунке 3(b) где обнаружение кадра k + 1 сравнивается со всеми обнаружениями от кадра k к кадру k - z и каждый кадр может содержать различное количество обнаружений (a, b, g, h, i и j).
Если найдено совпадение, то производится соответствие кадра j(k + 1)th обнаружения соответствующему идентификатору обнаружения в (k-z)th кадре. Если после сравнения предыдущих z-кадров совпадения не найдено, то считается что в кадре появился новый пешеход. Новому пешеходу присваивается новый идентификатор, и он отслеживается в последующих кадрах. Если пешеход покидает сцену или полностью перекрывается в кадре k + 1, соответствующее обнаружение в кадре k не будет совпадать в кадре k + 1, но этот идентификатор будет сохранен в базе данных для получения будущего соответствия. Однако, если алгоритм способен повторно идентифицировать пешехода после полной окклюзии в z в предыдущих кадрах, то выделяется соответствующий идентификатор обнаружения в (k − z) - ом кадре.
Множественные соответствия от j(k + 1) обнаружений до i(k)-го обнаружения могут произойти, если j(k + 1)> i(k). Такие ситуации могут быть разрешены путем создания соответствий j(k + 1) - го обнаружения n(k) - му обнаружению, имеющему наименьшее значение из множества {t(1,i(k)),...,t(i(k),j(k+1))}. Соответствие нераспределенных обнаружений осуществляется используя второе наименьшее значение из набора {t(1,i(k)),...,t(i(k),j(k+1))}, если оно ниже порогового значения. Если нет, то нераспределенные обнаружения сравниваются с обнаружениями предыдущих z кадров для обнаружения совпадения.
4 Результаты
Для оценки в исследовании был использован набор данных центра города. Первые 30 секунд видео были использованы с уменьшенной скоростью. Частота – 8 кадров в секунду. Обнаружение и отслеживание оцениваются отдельно с использованием матриц отслеживания. Результаты отслеживания и обнаружения представлены на рисунке 4

Рисунок 4 – (а) показывает обнаружения в видеопоследовательности, которые находятся на расстоянии 10 кадров друг от друга. (b)показывает результаты отслеживания. Число, обозначающее каждого пешехода, генерируется случайным образом в первом кадре.
Оценка отслеживания и обнаружения
Средняя точность и полнота детектора для использованных данных составляют 0,93 и 0,80 соответственно. Высокая тончность означает, что большинство обнаруженных объектов на самом деле являются пешеходами, а высокий уровень полноты означает, что в сцене обнаружено большинство пешеходов. Изменение точности и полноты между кадрами показано на рисунке. 5.

Рисунок 5 – Изменение точности и полноты между кадрами
Для оценки точности трекера используются матрицы многоцелевого отслеживания (MOTP) и (MOTA) (Bernardin and Stiefelhagen, 2008). Матрицы используются для объективного сравнения характеристик трекера по их точности в оценке местоположения объекта, их точности в распознавании конфигурации объекта и их способности последовательно маркировать объекты с течением времени. Математически MOTP и MOTA можно предствить следующим образом:

Где dit расстояние между обнаружением и i-м пешеходом, Ct количество совпадений, найденных за время t.mt, fpt и mmet количество–промахов при обнаружении (ложные обнаружения), количество ложных срабатываний и количество несовпадений в корреспонденции соответственно, а gt представляет количество пешеходов, присутствующих в момент времени t. MOTP-суммарная ошибка в оценочном положении обнаружений в целом по кадры усредненная по количеству сделанных соответствий. Более высокое значение MOTP означает низкую точность ограничивающей рамки вокруг объекта. Более высокие значения MOTA означают высокую точность в отслеживании. Экспериментально результаты MOTP и MOTA для набора данных составляют 27,92 пикселя и 71,13% соответственно.
Вывод
Отслеживание достигается путем создания соответствия обнаружений только двух последовательных кадров (при условии, что нет множественных соответствий или соответствия с предыдущим кадрам). Следовательно, с течением времени появляются новые пешеходы, и структура устойчива к изменению внешнего вида (позы, формы и масштаба). Детектор пропускает некоторые из обнаружений из-за полных окклюзий и, следовательно, объясняет низкое значение полноты. Еще одним фактором, способствующим снижению значений полноты, является то, что детектор пропускает пешеходов, которые кажутся меньше из-за их расстояние до камеры. Это может быть исправлено в настройке нескольких камер, где пешеходы, которые пропущены в одной камере, скорее всего, будут обнаружены в другой камере. При более близком наблюдении низкое значение точности объясняется ложными обнаружениями, создаваемыми отражением пешеходов в стеклянной панели, которая присутствует в наборе данных. Высокое значение MOTP обусловлено неточностью ограничивающих рамок обнаруженных пешеходов. Это незначительно, учитывая высокое разрешение набора данных. Низкое значение MOTP в основном связано с большим количество пропусков при обнаружении и частично из-за ложных обнаружений и несоответствий.
Заключение
Разработана платформа для обнаружения и отслеживания пешеходов в режиме реального времени на кадрах изображений CCTV с использованием CNNs. Разработан новый алгоритм для обеспечения соответствия обнаружений по нескольким кадрам. Детектор способен преодолевать проблемы вариаций освещения, загроможденных фонов, частичных окклюзий и изменений в масштабе. Алгоритм слежения способен отслеживать пешеходов с точностью 71,13 % и решена проблема изменения внешнего вида (позы и формы) и тотальных окклюзий на короткие промежутки времени. Однако, полная окклюзия на более длительные периоды остается проблемой, которую необходимо решить для будущей работы. Для того чтобы улучшить точность, предлагается провести оценку будущих траекторий движения пешеходов по данным прошлых наблюдений (напр. Калмана) для преодоления проблемы непредсказуемости движения пешеходов.Для решения проблемы полной окклюзий и аналогичных лиц, может быть использована среднее представление отдельных пешеходов (для всех отслеживаемых кадров).
Литература
- Bernardin K. and R. Stiefelhagen (2008). Evaluating multiple object tracking performance: The clear mot metrics. EURASIP Journal on Image and Video Processing 2008 (1), 246309.
- Chen Y., X. Yang, B. Zhong, S. Pan, D. Chen, and H. Zhang (2016). Cnntracker: Online discriminative object tracking via deep convolutional neural network. Applied Soft Computing 38, 1088–1098
- Donahue J., Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell (2014). Decaf: A deep convolutional activation feature for generic visual recognition. In International Conference on Machine Learning, pp. 647–655.
- Fan .J., W. Xu, Y. Wu, and Y. Gong (2010). Human tracking using convolutional neural networks. IEEE Transactions on Neural Networks 21(10), 1610–1623.
- Feris .R., A. Datta, S. Pankanti, and M.T. Sun (2013). Boosting object detection performance in crowded surveillance videos. In IEEE Workshop on Applications of Computer Vision, pp. 427–432
- Hong S., T. You, S. Kwak, and B. Han (2015). Online tracking by learning discriminative saliency map with convolutional neural network. arXiv preprint arXiv:1502.06796.
- Ji S., W. Xu, M. Yang, and K. Yu (2013). 3d convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (1), 221–231.
- Jin J., A. Dundar, J. Bates, C. Farabet, and E. Culurciello (2013). Tracking with deep neural networks. In Information Sciences and Systems (CISS), 2013 47th Annual Conference on, pp. 1–5
- Krizhevsky A., I. Sutskever, and G.E. Hinton (2012). Imagenet classification with deep convolutional neural networks. In F. Pereira,
- C.J.C Burges, L. Bottou, and K.Q. Weinberger (Eds.), Advances in Neural Information Processing Systems 25, pp. 1097–1105. Curran Associates, Inc.
- Lecun Y., L. Bottou, Y. Bengio, and P. Haffner (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE 86(11), 2278–2324.
- Li H., Y. Li, and F. Porikli (2016). Deeptrack: Learning discriminative feature representations online for robust visual tracking. IEEE Transactions on Image Processing 25 (4), 1834–1848.
- Nam H. and B. Han (2015). Learning multi-domain convolutional neural networks for visual tracking. Computing Research Repository abs/1510.07945.
- Ren S., K. He, R. Girshick, and J. Sun (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In C. Cortes, N.D. Lawrence, D.D. Lee, M. Sugiyama, and R. Garnett (Eds.), Advances in Neural Information Processing Systems 28, pp. 91–99. Curran Associates, Inc.
- Smeulders A. W., D.M. Chu, R. Cucchiara, S. Calderara, A. Dehghan, and M. hah (2014). Visual tracking: An experimental survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 36 (7), 1442{1468.
- Wang N., S. Li, A. Gupta, and D. Yeung (2015). Transferring rich feature hierarchies for robust visual tracking. Computing Research Repository abs/1501.04587.
- Wang N. and D.Y. Yeung (2013). Learning a deep compact image representation for visual tracking. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger (Eds.), Advances in Neural Information Processing Systems 26, pp. 809–817. Curran Associates, Inc.
- Wang X. (2013). Intelligent multi-camera video surveillance: A review. Pattern Recognition Letters 34(1), 3–19.
- Yilmaz A., O. Javed, and M. Shah (2006). Object tracking: A survey. ACM Computing Surveys 38(4).