Применение методов глубокого обучения в системе видеонаблюдения
Авторы: М.С. Егорова, Т.В. Мартыненко, И.В. Ченгарь
Источник: Материалы IX Международной научно-технической конференции Информатика, управляющие системы, математическое и компьютерное моделирование
(ИУСМКМ-2018). – Донецк: ДонНТУ, 2018. – 172–176 с, [Ссылка]
Аннотация:
Егорова М. С., Мартыненко Т. В., Ченгарь И. В. Применение методов глубокого обучения в системе видеонаблюдения. В статье поднимается вопрос об актуальности и важности исследований в области компьютерного зрения. Рассмотрены наиболее популярные модели глубокого обучения. Сделан вывод о перспективности применения подобных решений в области систем безопасности и видеонаблюдения, в частности.
Введение
Одна из наиболее значимых потребностей человека заключается в обеспечении безопасности жизни родных и близких, а также сохранности материальных ценностей и личного имущества. Одной из основных проблем ХХI является терроризм в различных его проявлениях. Видеонаблюдение успешно применяется в местах большого скопления людей – местах потенциальной опасности–в аэропортах, различных супермаркетах, метрополитене. Благодаря использованию систем видеонаблюдения, значительно снижается риск возникновения опасных для жизни человека ситуаций. С другой стороны, видеоаналитика приобрела неблагоприятную репутацию. Одна из самых значительных проблем заключается в неспособности корректно идентифицировать объекты в ситуациях, которые кажутся тривиальными для человеческого зрения. Во многих случаях это приводит к тенденции генерировать большое количество ложных тревог. Это, наряду с большим количеством сложных процедур настройки и потребностью в ручной работе, мешает видеоаналитике стать широко используемым, развернутым на большом количестве камер решением.
Глубокое обучение–это хорошо зарекомендовавшая себя область исследований. Оно основано на сборе больших объемов данных, специфичных для конкретной проблемы, подготовке модели с использованием этих данных, а затем использовании этой модели для обработки новых данных. Что касается видеоаналитики, одной из наиболее важных проблем, влияющих на точность, является классификация. Основополагающим фактором повышения производительности является способность научить алгоритм различать людей, животных, различные типы транспортных средств и источники шума с высоким уровнем точности.
Постановка задачи
Целью исследования является обзор и анализ видеоинформации для дальнейшего распознавания и классификации объектов. В данном случае под объектом понимается тревожная ситуация–появление в области видимости камеры объекта, классифицируемого как тревожный. Пример работы такого приложения продемонстрирован на рис. 1.

Рисунок 1–Пример работы приложения распознавания объектов
Математическая постановка задачи
Анализ изображения заключается в определении его принадлежности к одному из заданных классов объектов. Для такой классификации должна быть выделена некоторая система признаков, однозначно определяющих принадлежность объекта тому или иному классу. При выборе признаков учитываются алгоритмы классификации. В зависимости от специфики рассматриваемой задачи применяют разные системы признаков. Все они имеют различные характеристики и область применения. Признак в общем виде можно формализовать следующим образом: дано X множество объектов, ситуаций, прецедентов некоторой предметной области. Признак можно представить, как указано на формуле (1).
где Df – множество допустимых значений признака.
Часто встречаются задачи с разнотипными признаками, для решения которых подходят далеко не все методы.
Если заданы признаки f1,...,fn, то вектор x=(f1(x),...,fn(x)) называется признаковым описанием объекта x ∈ X.
В машинном обучении признаковые описания допустимо отождествлять с самими объектами, то есть: X = Df1×...×Df1 .При этом множество X называют признаковым пространством. Матрицей объектов-признаков является совокупность признаковых описаний объектов обучающей выборки xl=(x1,...,xl) длины l, записанная в виде матрицы размера l × n (l строк, n столбцов). Столбцы этой матрицы соответствуют признакам f1,...,fn, а каждая строка является признаковым описанием одного обучающего объекта.
В рассматриваемой задаче видеоанализа тревожных ситуаций признаками могут служить такие визуальные характеристики как цвет, текстура, форма, пространственное расположение объекта, а также некоторые локальные признаки изображения, получаемые в результате сегментации и поиска точек-областей интереса.
Обзор моделей для анализа видеоинформации
Существуют различные методы расчета признаков объектов изображения, к их числу относятся гистограммы, статистические модели, матрицы смежности и т. д., а также методы классификации объектов, такие как иерархический, фасетный и дескрипторный. При работе с видеосигналом имеет место большой массив входной информации, которую необходимо проанализировать и систематизировать. Компьютерное зрение и сети глубокого обучения в частности эффективно решают задачи распознавания, идентификации и обнаружения объектов. Приведем самые популярные из них.
Свёрточные нейронные сети (CNN) во многом основываются на моделях, представленных в [1]. CNN состоит из трех основных типов слоев, а именно: свёрточных, слоев объединения и полностью связанных слоев. CNN алгоритмы являются чрезвычайно успешными в задачах компьютерного зрения, таких как распознавание лиц и обнаружение объектов. Схема алгоритма CNN в общем виде приведена на рис. 2.
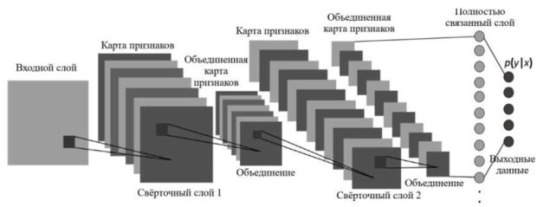
Рисунок 2 – Схема алгоритма CNN в общем виде
Одна из трудностей, которые могут возникнуть при обучении CNN, связана с большим количеством параметров, которые необходимо учесть, что может привести к проблеме переобучения. В целом, в [2] было доказано, что CNN значительно превосходит традиционные подходы к компьютерному обучению в широком спектре задач компьютерного зрения и распознавания образов. Их исключительная эффективность в сочетании с относительной легкостью в обучении являются основными причинами, которые объясняют большой всплеск их популярности в течение последних нескольких лет.
Глубокая сеть доверия (DBN) и глубокая машина Больцмана (DBM) – это модели глубокого обучения, которые используют ограниченную машину Больцмана (RBM) в качестве обучающего модуля. RBM представляет собой генеративную стохастическую нейронную сеть. DBN имеет направленные соединения в двух верхних слоях, которые образуют RBM и направленные соединения с нижними уровнями. DBM имеют неориентированные соединения между всеми слоями сети. Графическое представление DBN и DBM приведено на рис. 3.
Глубокие сети доверия (DBN) – это вероятностные генеративные модели, которые обеспечивают совместное распределение вероятностей по наблюдаемым данным и меткам. Они формируются путем укладки RBM и обучения их «жадным» способом.
В жадном
процессе обучения DBN есть два основных преимущества. Во-первых, он решает задачу выбора параметров, что в некоторых случаях может привести к плохим
локальным оптимумам, тем самым гарантируя надлежащую инициализацию сети. Во-вторых, нет требований к помеченным данным, поскольку процесс не контролируется.
Тем не менее, алгоритмы DBN также страдают от ряда недостатков, таких как вычислительная стоимость, связанная с обучением DBN.
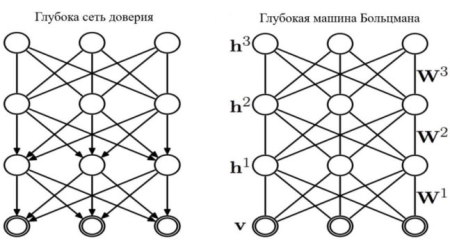
Рисунок 3 – Схематическое представление DBN и DBM
Глубокие машины Больцмана (DBM) [3] – это еще один тип глубокой модели, использующей RBM. Разница в архитектуре с DBN заключается в том, что во втором верхние два слоя образуют неориентированную графическую модель, а нижние слои направленную генеративную модель, тогда как в DBM все соединения ненаправлены. DBM использует алгоритм, основанный на стохастическом максимальном правдоподобии, для максимизирования нижней границы вероятности. Такой процесс, казалось бы, уязвим к падению в плохих локальных минимумах. Поэтому была предложена «жадная» стратегия обучения, которая, по сути, состоит в предварительном обучении уровней DBM, аналогично DBN, а именно, путем укладки RBM и обучения каждому слою независимо моделировать вывод предыдущего слоя, затем окончательной совместной тонкой настройкой.
Что касается преимуществ DBM, он может захватывать множество слоев сложных представлений входных данных, и подходит для неконтролируемого обучения, поскольку может быть обучен немаркированным данным, но также может быть точно настроен для конкретной задачи под контролем. Одним из наиболее существенных недостатков является, высокая вычислительная стоимость обработки, что является практически критичным обстоятельством, когда речь идет о совместной оптимизации в крупных наборах данных.
Применение методов в системе видеонаблюдения
Описанные методы нашли применение в задачах обнаружения объектов – это процесс обнаружения экземпляров семантических объектов определенного класса в цифровых изображениях и видео. Общий подход для фреймворков подобного применения включает в себя создание большого набора потенциальных областей-точек интереса, которые в дальнейшем классифицируются с использованием возможностей CNN. Например, метод, описанный в [3], использует выборочный поиск для получения объектных предложений, извлекает возможности CNN для каждого предложения и затем передает функции в классификатор SVM, чтобы решить, включают ли окна объект или нет. Решения с помощью алгоритмов CNN (например, [4, 5]) обычно имеют хорошую точность обнаружения. Подавляющее большинство работ по обнаружению объектов с использованием глубокого обучения применяют вариации CNN, например, [6, 7, 8]. Однако существует небольшое количество попыток обнаружения объектов с использованием других глубоких моделей.
Подытоживая вышеприведённую информацию, можно составить сравнительную характеристику моделей глубокого обучения (табл. 1).
| Характеристика | CNN | DBN/DBM |
|---|---|---|
| Обучение без учителя | − | + |
| Эффективность обучения | − | − |
| Функция обучения | + | − |
| Инвариантность преобразований | + | − |
| Обобщение | + | + |
Примечание: +
в соответствующей ячейке означает наличие характеристики или высокую эффективность, −
– отсутствие характеристики или низкую эффективность.
Заключение
В статье исследуются модели глубокого обучения нейронных сетей и их применение в области видеонаблюдения. Проведен сравнительный анализ моделей, описаны ключевые преимущества и недостатки каждой модели. Основная проблема применения моделей глубокого обучения нейронных сетей является чрезвычайно высокая вычислительная стоимость, особенно когда речь идет об обработке видеопотока. Хоть данная сфера разработок и является перспективной, на сегодняшний день ещё не нашла применения в задачах обработки потокового видеосигнала.
Литература
- D.H. Hubel, T.N. Wiesel,
Receptive fields, binocular interaction, and functional architecture in the cat's visual cortex
[Electronic Resource] / URL: https://www.ncbi.nlm.nih - Y. Bengio,
Learning deep architectures for AI
[Electronic Resource] / URL: https://www.iro.umontreal.ca/ - R. Girshick, J. Donahue, T. Darrell, J. Malik,
Rich feature hierarchies for accurate object detection and semantic segmentation
[Electronic resource] / URL: https://pdfs.semanticscholar.org/ - R. Girshick,
Fast R-CNN
[Electronic resource] / URL: https://www.cv-foundation.org_ R-CNN_ICCV_2015_paper.pdf - S. Ren, K. He, R. Girshick, J. Sun,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[Electronic resource] / URL: https://arxiv.org/ - W. Ouyang, X. Zeng, X. Wang,
DeepID-Net: Object Detection with Deformable Part Based Convolutional Neural Networks
[Electronic resource] / URL: http://www.ee.cuhk.edu.hk/ - A. Diba, V. Sharma, A. Pazandeh, H. Pirsiavash, L.V. Gool,
Weakly Supervised Cascaded Convolutional Networks
[Electronic resource] / URL: https://www.csee.umbc.edu/ - T. Chen, S. Lu, J. Fan,
S-CNN: Subcategory-aware convolutional networks for object detection
[Electronic resource] / URL: https://www.researchgate.net/publication/