
Abstract
Table of Content
- Introduction
- 1. Justification of the practical applicability of the research results
- 2. Overview of existing solutions
- 2.1 The essence of object-oriented programming
- 2.2 Methods of automation of coding algorithms
- 2.3 Debugging automation
- 2.4 Computer-aided integrated developer environments
- 2.5 Automation of program assembly
- 3. The essence of this scientifical research and innovation
- References
Introduction
Primarily note that the transferring of experience is important in any field of production, including programming. Despite the fact that Western European researchers say: No Silver Bullet [1], it is reasonable to assume that programming can and should be automated.
How, then, is the transfer of the experience of programmers: libraries of reusable program modules, class templates, etc. are created. But this is all one side of the coin. Are there any other ways to do this. Of course have.
A programmer sits at a desktop and writes code. Regardless of whether he uses ready-made libraries or ready-made solutions, he still writes code. Perhaps this occupation brings him aesthetic satisfaction. But it takes a lot of time. Actual is the issue of reducing the time spent on creating a program. So that software projects cease to disrupt the deadline.
Despite the apparent effectiveness of introducing new programming technologies, it remains necessary to follow the principles that have been proven in software engineering for decades. The poor quality of the software product is due to non-compliance with these principles [2]. For example, an attempt to list all types of geometric figures in one module leads to the need to change this module each time a task with specific, previously unknown figures appears [3]. Indeed, it is impossible to know everything, and the programmer creating such a library should provide for the possibility of implementing new functionality by adding rather than modifying an existing module.
High-quality design of the program implies the possibility of its use in the development of other programs. Otherwise, no transfer of experience will occur. And the program will remain a highly specialized toy in the hands of its creator. The maximum permissible concentration of carbon monoxide in the atmosphere can increase by an order of magnitude due to a program error made as a result of an attempt to adapt an existing program to a new task.
The aim of this work is to develop a new way to automate the programming process based on the use of SOLID principles and using technology for synthesizing program code using ontologies.
In this article, it is planned to solve the following problems;
- search for existing ways to automate programming;
- developing a method for synthesizing class diagrams;
- evaluation of received object modules.
Scientific novelty lies precisely in the use of SOLID principles for the automatic synthesis of class diagrams.
1. Justification of the practical applicability of the research results
A synthesis system for design patterns is being developed. But there are ready-made patterns. Why not use them. Indeed, turnkey solutions are focused on existing projects, but for new projects this is not an ideal solution.
The preparatory stage is to collect information about solving typical problems of designing software architecture. Architecture is that which is invariable throughout the entire life cycle of a project. Invariable is the programming language and class diagram. The use of design patterns simplifies the creation of the primary architecture of the program.
In truth, the patterns are far from being applied as described. If the computer-aided design architecture of the program architecture blindly copies them into the class diagram, then the scheme will be too complicated. Understanding specialist does not. Patterns have to be invented for each task. The foundations are those stable structures that have been formed in the many years of experience of software architects.
What distinguishes these constructions from classes from ordinary schemes, randomly assembled from basic elements, is the application of the principles of SOLID. A pattern in which these principles are not respected is called an antipattern, e.g. Active Record [4].
It is advisable to avoid the use of antipatterns. Then the optimal extensibility of the system is ensured and the snowball effect is prevented when it is planned to make corrections to one module, and the program will be rewritten [2].
The generation of UML diagrams [5] in combination with the use of CASE tools that allow you to translate class diagrams into code [6] greatly simplifies the process of creating an object-oriented program.
2. Overview of existing solutions
So, what is the difference between the command interface and the windowing interface [7]. The command interface operates with a command language. The vim text editor is the example of this type of interface. In it, operations of moving along lines, inserting, deleting lines, file operations are performed using commands.
However, most text editors have a windowed interface. In these programs, text is entered from the keyboard, and file operations and full-text search are accompanied by showing forms to the user.
For each task, there is a suitable choice of user interface type. This is not to say that the forms interface is better than the command interface, or vice versa.
If the programming language is graphical, then the compiler user interface will be graphical. This is true for the translator of graphical UML notation into object-oriented code of a textual class description language [6]. Imagine now that the program text compiler has a form interface. At each compilation, a window appears with the task of optimization parameters, the choice of a set of instructions, etc. Of course, in this case the command interface is convenient, since all these parameters can be specified in the arguments of the compiler program call and write the received command line to the assembly automation file.
There is another point about the multi-level knowledge base. What is nesting is detail. Detailing is the process of adding details to a software project. And the details of a software project have their own characteristics at each level of detail.
The nesting of knowledge modules in relation to a computer-aided design system of software is manifested when considering the levels of detail of a software project: the level of architecture and the level of program code. At the architecture level, APIs are described. These are function declarations in C language terms. At the code level, high-level and low-level algorithms are described. These are function definitions in terms of the C language.
The level of program code, in turn, has sublevels: high-level and low-level algorithms; description of the algorithm in pseudo-code and in a specific programming language. A significant difference between a high-level language and a low-level language of algorithms is that they describe the procedure for solving a particular problem using actions that are understandable to humans. And lower-level routines translate these actions into a language that the operating system understands.
Upstream routines always call downstream routines. When it becomes necessary to move from one implementation of a lower-level algorithm to another, the mechanism of polymorphism comes to the rescue. A polymorphic class describes a subroutine for creating a neural network layer.
2.1 The essence of object-oriented programming
Interpretation of the concepts of object-oriented programming. Indeed, programming is possible only with the help of a language. Therefore, the existence of OOP is inextricably linked with the programming languages that support it. The developer of the C++ language defines OOP as the development of a modular programming paradigm that makes it possible to express differences between modules by inheritance [3]. The principle of data hiding, or the so-called encapsulation, originally present in the paradigm of modular programming, in languages such as Modula-2. Initially, polymorphism was a data abstraction that became part of OOP.
There is an opinion that the transition to the use of OOP occurred prematurely [8]. But this is not so, because the study of OOP involves its use, because it is a method of programming.
Although you can use OOP on paradigms [9]. In this case, the polymorphic method is replaced with a pointer to the subroutine. In this case, the creation of a layer of individual neurons is indicated. In any case, the signatures of these functions must be the same. If one implementation is for the CPU, the other is for the GPU, then the program can select the desired implementation depending on the presence of the GPU in the system using algorithms.
2.1.1 Self-synthesizing of programs
The most controversial and slightly philosophical question: is the machine capable of self-programming [10]. Solving applied tasks on a PC is done using software that people develop. In other words, a person provides a machine with programs that he himself creates using a machine. However, why would a person bother to perform this labor-intensive operation, if part of the work could be transferred to a machine.
So, there are two types of work on creating software: automated [11] and non-automated (manual). The first group includes:
- compilation;
- documentation generation;
- static code analysis to identify common errors [12];
- reverse engineering for documentation purposes [13];
- translation of class diagrams into program code [6];
- conveyor assembly program [14];
- automatic deployment [15];
- unit testing [16].
As a result, a man taught a machine to perform a number of automated operations to create software. However, most of the work falls on human. We list the activities of the second group:
- coding algorithms;
- writing documentation;
- formal inspections of program code for the deep detection of software errors;
- reengineering of the project in order to improve its quality;
- creating class diagrams and a number of detailing UML diagrams;
- creating a project and automating its assembly;
- settings for automatic deployment;
- writing unit tests.
What is the reason for the non-automation of the second group of processes. As you can see, from these two lists you can make a table:
| Human work | Machine operation |
| coding algorithm | compilation |
| documentation | documentation generation |
| inspection | static code analysis |
| reengineering | reverse engineering |
| charting | diagram code generation |
| build automation | program assembly |
| program installation | program delivery |
| writing tests | test execution |
So it turns out that a person encodes and a machine compiles. Why not the other way around? Suppose the columns are reversed. Now the machine comes up with algorithms, and the person must put them into action. While the machine dictates instructions in its own language, a person has to perform these actions. Sooner or later, a person gets tired of performing the same type of operations, and he has a desire to reduce, change the order of actions. And the car continues to dictate instructions. The question arises: why does he need them, because a person without a machine is able to decide what actions to perform. And the car, on the contrary, needs such a manual. This property is called the will power, which the machine does not have. A machine performs only those actions that a person needs, and only when it is forced to perform them.
Why can't the machine instruct itself? Human actions are dictated by common sense and needs. The machine has no needs, since it was created by a person to solve his problems. It is not known what would happen if the machine had a need for food ... Although, indeed, the machine consumes electricity, and even is able to express its need for it when it is lacking. However, this behavior is programmed by a person and the awareness of the need to survive, and that this requires electricity, the car is missing. Then, perhaps, the machine does not instruct itself simply because it needs electricity to perform any action. And since she needs this electricity to function, she does not want to waste it. That's right, why do something if this costly operation is not useful. What is the use of action for a car? Yes, in optimizing the system, for example. And the point of optimization is to reduce the waste of PC resources. And reduce waste to reduce material costs and accelerate the solution of applied problems. And this, in turn, is only necessary for a person, since a PC does not care how much electricity he eats and how much video cards are enough for him, a person still provides him with everything. As a result, it turns out that only a person needs all the actions of the machine, and the machine does not need them. That's why the machine is not self-programming: it does not need any actions. But a man needs it, everything is not enough for him, he needs more. He created a rocket, engine, computer, wrapped the world in fiber optic cable, and sits, rejoices. And the computer meekly carries out his instructions.
2.2 Methods of automation of coding algorithms
If we cannot swap columns, then it remains to try to shift the center of gravity in favor of automating the encoding of the algorithms. Yes, algorithms are necessary for the person, but not the machine. Therefore, only a person decides to create an algorithm. And in order to convey it to the machine, a common language is needed that will be understandable to both man and computer. So the task of man is to write down an algorithm in such a language, and the computer will execute this algorithm. For this, programming languages are needed, and you cannot get rid of them for the reason that they provide a communicative connection between a person and a computer. We come to the understanding that shifting the center of gravity in favor of automation is done by facilitating the process of coding algorithms [17]. At the same time, the language changes, but must remain complete and remain unambiguous. The completeness of the language means the ability to explain by means of it the course of solving any existing problem. What fundamentally new things can be invented in this area, which would facilitate the coding process.
In some cases, a graphical programming language, e.g. Scratch [18] (the same language is the basis of the author's project on visual programming in Java [19]), is able to facilitate the coding of algorithms in teaching programming. Algorithm coding is performed by dragging and dropping blanks of ready-made code blocks in the editing window. There are several more visual programming languages: DRAGON.
The DRAGON language is based on the paradigm of two-dimensional structural programming [20]. This means that the algorithms are described in the form of a drawing, not text. Two-dimensionality consists in the fact that the structural blocks of the algorithm are located on the plane of the drawing so that the designer’s vision moves both horizontally and vertically when reading the algorithm. About the same thing happens in the case of writing multi-threaded programs: the designer often has to move between several parallel workflows. DRAGON uses parallelization and synchronization blocks to describe multithreading, as in UML activity diagrams. The components of the DRAGON scheme (the so-called icons) are elements of flowcharts and some additional blocks.
There is still no major project that is completely written in a visual programming language [21]. Be sure to meet the honor of a code in another language. The main reasons for the low popularity of visual programming languages:
- the need for frequent movement of the hand when entering language operators from the keyboard to the mouse and vice versa;
- Serious projects can not do without third-party libraries, most of which have an interface with text languages;
- implementations of visual programming languages are closed and commercial.
Although, the last two reasons are not related to the DRAGON. Indeed, this language has a connection with other text languages. The text syntax of the borrowed language allows the use of libraries written in it. There are different variations of DRAGONS, each of which differs in the syntax of the text part. And as for the third remark, it is not valid in relation to the DRAGON, since not all implementations of this language have a commercial license. Then what causes the low popularity of this language? Perhaps its narrow focus. Despite the fact that flowcharts can describe any algorithm, while text languages provide a finite number of keywords, DRACON operates with a finite number of graphic notations instead of these words. Different combinations of these icons are designed to provide an opportunity to describe any algorithmic design. Here is the Assembler language, from the commands of which any program consists. There is such a command as a pause, it provides a delay in the active wait cycle.
The impossibility of expanding capabilities by creating new structural elements is the reason for the narrow specialization of the DRAGON language.
Another reason is that there are sequential algorithms that are easier to describe with one-dimensional structures. The block diagram of such an algorithm has the form of a chain of rectangles, at the ends of which there are two terminal elements: a title and an end. And there are many such algorithms, especially in system programming. The use of graphical notation in this case is impractical, since it leads to excessive redundancy of actions associated with the creation and arrangement of new blocks. This, of course, can be avoided by simplifying the procedure for creating and placing a block, but the readability of the algorithm will suffer due to the large distances between the operators, and as a result, the algorithm may take more than one page with its flowchart.
There is another reason that is due to the very paradigm of two-dimensional structural programming. It appears when the code needs to fix a software error. What is easier to find an error in the text or in the picture? If in the text, then a person looks through his line by line and his attention is evenly distributed to each operator. And in the case of the drawing from the flowcharts, the eyes are scattered in different directions and the attention is unevenly scattered to different operators of the algorithm. However, everything is true, you can view the algorithm sequentially without missing a single operator. There is little chance of skipping the operator when you are viewing the flowchart. This is the advantage of visual programming: the ability to bypass all transitions and operators when testing using the white box method.
In general, in my opinion, two-dimensional algorithms take up more space than usual. And therefore, visual languages are not widespread.
If the translation of the flowchart into code leads to a loss of evidence, then this is a sign of careless programming [20]. When translating to the code, a repetition of the condition occurred in the branching block and the loop. Here is how I usually do to avoid this:
WHILE (end of loop sequence) DO
IF (the current state satisfies the search condition) THEN
RETURN (condition found)
END
END
RETURN (condition not found)
Listing 1 — An example of an algorithm for finding an item in a list
As you can see, there is no repetition. This was an example to the fact that comparing block diagrams and code depends on how the author expressed the algorithm in the code. Thus, the shortcomings assigned to traditional structural programming are not objective.
Take a look at the block diagram and the code. That more? Yes, of course, flowcharts provide the visibility of the algorithm. But, when it comes to large projects, code is used to describe the algorithms, because it takes up less space on the screen, which allows you to store large amounts of program code in repositories (e.g. GIT).
And this is another reason why flowcharts are not used for programming large projects. After all, the development team of this project writes separate sections of code, and the time comes when all the development needs to be combined together. In this case, two versions of the program code are compared and differences are found, and then one of the options for each line is selected. The fact is that the code is ordered and goes from top to bottom, and the block of the circuit is directed in all directions, which makes it difficult to automatically compare and merge several versions of one algorithm becomes a burdensome task for the programmer.
To the question of why classes are needed. OOP is just a good way to group routines that have something in common. It follows that OOP is only useful when developing large programs with many functions.
Correspondence of classes to objects of the real world is used only for teaching programming, since developing large projects alone is inefficient. In fact, the model of the material world has nothing to do with OOP. The program operates with information and not with physical objects.
In the names of OOP patterns, all words are used in a figurative sense. E.g. the facade — this is not what you are used to seeing while driving along the main street of the city. In OOP, this word draws an analogy with the facade of the building, as an additional layer between the user and the library, which is designed to simplify its use.
Let classes not inherit objects of the material world, but the subprograms of which they consist have something in common with systems. Each routine has a set of inputs and outputs, as well as internal variables. In system analysis [22] a matrix of the form is used to designate such systems:
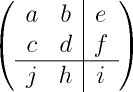
(1)
In the first quarter are the coefficients of state variables. This is the transfer function matrix.
The system output is calculated by the formula (2).
(2)
The state variable is calculated by the formula (3).
(3)
First, the system output is calculated, and then the state variable is updated. Thus, the state is saved after calling the function.
All that is complex is not repeated twice. Complex systems are made up of simple ones. Simple systems are elementary. The backbone elements of each program are actions and variables. The information processing process consists of a sequence of actions arranged in a certain order. The order of actions plays an important role, changing it can violate the logic of information processing, especially when it comes to multithreading. In multithreaded programs, the time taken to complete each elementary action is taken into account. Consider an example of the implementation of such an algorithmic structure as a barrier, schematically depicted as follows:

Figure 1 — Multithreaded program with two barriers (this is animation: 20 frames and 15 Kb)
The procedure for entering the barrier should return a positive result only for the stream that came out last from it. checking the return value allows you to determine that the barrier is no longer busy and ready for iteration again.
In assembly language, the code would be:
MOV AX, threads ; write the total number of threads to the battery LOCK INC wait ; increase the counter of waiting threads LOCK CMPXCHG wait, 0 ; compare meter with battery JNE idle ; go down in case of inequality MOV AX, 1 ; return TRUE RET idle: CMP wait, 0 ; compare the counter of waiting threads with zero JNZ idle ; wait until the counter is reset to another thread XOR AX,AX ; return FALSE RET
Listing 2 — Multithreading Barrier Algorithm
What is surprising is the fact that this seemingly so elegant implementation of the barrier contains one small problem, the solution of which leads to a chain reaction: the emergence of new ones due to the solution of previous ones.
To implement the barrier is used two shared variables: total number of threads and number of waited threads. Obviously, a thread must wait until the number of pending threads equals the number of all threads. To check this condition, a comparison command with the exchange [23] is used, which compares the first operand (number of waiting threads) with the accumulator (total number of threads) in one atomic operation and writes the constant value to this operand.
2.3 Debugging automation
There are bugs that are caused by multithreading, but you can also highlight:
- vulnerabilities of network protocols; from the identification is associated with enumeration of random changes in data packets;
- the rattling error of multithreading, which was just discussed;
- semantic errors associated with a misunderstanding of the logic of the algorithm.
It is known that the main criteria for software quality are the correctness of its operation and the lack of viscosity of the program code. The latter is necessary for the operational introduction of changes to the logic of information processing in order to ensure compliance with new requirements.
The traditional approach to establishing program correctness is unit testing. However, with a large number of lines of code, there can be many variants of a test case, and writing unit tests for such a program is difficult. For such cases, they came up with fuzzing [24], when the program itself generates obviously incorrect test sets and reports which one led to the crash. For such a procedure, one should only describe the structure of the input data and establish criteria for the correct operation of the program.
Since software was written at different times, different paradigms and approaches to organizing program code were used. New concepts break the prevailing stereotypes about coding algorithms. For example, the functional paradigm [25] has made significant changes to the code, turning it from a description of procedures to a description of functions. The functional approach changed the tactics of writing code from decomposition to detail. A functional approach has replaced loops with a subroutine call.
The result of introducing a design pattern into a programming language is JavaScript. The prototype OOP laid in its foundation eliminates the need to implement the prototype pattern. Smalltalk [26] is the only programming language that completely eliminates the need for generative design patterns. Instead of implementing an abstract factory, it provides the ability to create an object from an object class.
COM/DCOM [27] technologies provide the ability to create an object and call its methods using a string representation of their names. In other owls, the name of the called routine is set at run time.
Most features in the Ruby language [28]. This follower of Smalltalk inherited from him the principle of everything is an object.
A class is an object that creates objects of its class [29]. In addition, this language combines the string identification of COM classes and the object-oriented Smalltalk approach.
Introspection in OOP is the ability to call a class method knowing only its name. You can create objects by knowing his name. The constructor serves solely to initialize the object.
2.4 Computer-aided integrated developer environments
So, we found out that the DRAGON language is not able to shift the center of gravity in favor of the automation of coding algorithms. Are there any other ways to do this. There is not one. There is a technology such as IntelliSence, adding the name of a function by first letters. This technology is attributed to Microsoft, however, this feature is implemented in other IDEs, there is also a separate ctags program that indexes function names and other identifiers. So, has this code completion shifted the programmer’s efforts?
How does this technology work. We enter the first letters of the function name, the program shows a drop-down list with the names of functions that begin with the given characters. We find the desired function in this list and select.
A case of combining visual programming and code completion is possible. In the same DRAGON, the interiors of geometric figures are filled with code. This code contains the names of functions that can and should be filled in to help append automatically.
Automation of coding algorithms is achieved by improving programming languages [30]. Each language update takes into account the features of the software being developed at the time of its release. The new language is designed to simplify those sections of existing software code that are too confused due to the lack of expressive language tools. For example, there is the so-called. signals. And in order for a certain action to be performed after the program is completed, it was necessary to create a subprogram and transfer the address of this subprogram to the signal recorder. Then the name of this routine was not used anywhere. With the advent of the 2011 standard, anonymous functions were added to the language, which significantly simplified the registration of the signal handler.
However, some [31] do not agree with this provision. On the contrary, they believe that introducing new programming languages into practice does not accelerate the development process. And for this, it is proposed to
change the design automation systems and organize the assembly line of programs. Code reuse is seen as the primary way to automate programming.
Is there a limited resource for improving expressive means, or what will happen next with programming languages. Mr. Buch said that programming languages will evolve towards design patterns. How to imagine a programming language with built-in patterns? Too lazy to write patterns manually leads to the fact that the compiler will embed them in the program. Down with the manual scribble.
Further improvement of the C++ language does not fulfill G. Buch's dream, since its standardizers adhere to backward compatibility with existing programs written on it. For such purposes, a fundamentally new pattern-oriented programming language is needed. This paradigm means: write down which macroclasses are needed, and what is systemically important in them, and there will be a program with the necessary structures. After all, a class is a data structure. A data structure is a complex data type, i.e. consisting of several simple or complex types. Simple types are binary numbers, character arrays, and function pointers. A class in the usual sense of the C++ language represents a set of data types (as components of a structure) and a table of virtual functions. Class methods are simply functions that have a name consisting of the class name and the method name, separated by two colons. Function input data are listed in the parameter list. The first parameter of a function method is a pointer to a data structure in memory that contains a pointer to a table of virtual functions containing a pointer to this function. There is nothing special about OOP — ordinary structural programming.
2.5 Automation of program assembly
Why does the system itself not generate assembly rules? We ask her a question:
- can you compile a PDF file from LaTeX sources? — asks the programmer the assembly system.
- with or without bibliography? — The system asks a counter question.
- with a bibliography;
- there is a Makefile ready to use.
- and from Asciidoc? — The programmer suddenly asked.
- in what format?
- in PDF.
- keep an empty file, write the assembly rules in it.
And then the system should remember this file and at repeated request to issue it.
The traditional approach to automating this process: someone wrote a common fragment for each of all assembly files of a certain format, it may be too large; and the rest connect this file and indicate specific assembly parameters. It turns out much less code, but the end user should first familiarize themselves with the developer's instructions.
In fact, such a system already exists and is called CMake. It generates a Makefile from the project description, which contains:
- a list of files to compile;
- name of the final file;
- list of connected libraries.
For the case when the system does not know the file assembly algorithm, you can write a module with the definition of assembly rules and use it when describing projects containing files of this format.
Let's take a detailed look at the process of building project automation. The project consists of text files and it must be converted to a binary format in order to execute on the user's computer.
An imperative and declarative approach is used to automate the assembly.
| Project language | Automation type | |
| Imperative | Declarative | |
| C, C++, Pascal | Make | Automake CMake |
| Java | Ant | Maven, Gradle |
An example of an imperative approach: assembly files for the Make system consist of:
- variables, as macro definitions in the C language;
- rules, which consist of the name of the result file, the name of the source files and the command to call the compiler program, which makes the result file from the source files.
For large projects, this build automation approach becomes too tedious, so the world community has come up with a number of tools that automate the creation of files with assembly rules: Autoconf / Automake, CMake [14].
The project description file for CMake is called CMakeLists.txt and contains:
- version of CMake;
- the name of the project;
- used programming language;
- location of the directory with header files;
- location of the directory with the source files;
- additional compiler options;
- a list of assembly goals with an indication of their types: executable file or library; and for the library, static or dynamic linking is indicated.
- an indication of the relationship between the goals of the assembly so that the system determines in what sequence to assemble them.
The result is a bit more data fits into the project description, but this eliminates the need to enter compiler invocation commands into the assembly file. The CMake database contains all the necessary information about the compilers that are used for each type of source file.
A similar match has developed in build systems for Java. Ant has an imperative approach to describing the build algorithm, while Maven and Gradle are declarative.
In the Maven build system, the project description is contained in XML files. Gradle eliminates the need to use this redundant format, offering to describe the project in Groovy. The project description for these build systems contains:
- the name of the project;
- assembly parameters of the executable file;
- A list of dependencies that are automatically downloaded over the network.
A distinctive feature of Maven and Gradle is that they automatically download and connect all project dependencies. In addition, a list of source files for the assembly is generated automatically, since their location is specified by the standard.
The project assembly system automates not only the compilation of the program, but also its installation. For example, for Ruby, libraries are delivered in the form of archives, which are automatically unpacked into the library directory. To create such archives, the Rake system is used. The Rakefile build automation script includes:
- name of the library, its version;
- author of the library, license;
- A brief and complete description of the library, its purpose;
- a list of library files.
For Perl, there are several similar approaches to automating the creation of archives with a library, but they all boil down to the fact that a Makefile is generated from the project description on the user's computer, which includes the same fields.
In the field of software production, automation is proceeding at a faster pace than in other areas. This is explained by the fact that for the automation of programming it is not necessary to attract specialists from other areas. The developers themselves want to simplify their lives, and come up with different tools to meet their needs. Unlike, for example. CAD aircraft, they are attracted by an aircraft designer who puts forward his vision of the future program. For CAD software, the contractor is the customer himself and the consistency of requirements significantly speeds up the development of such tools.
The difference between the software development environment and the scientific environment is that an uncontrollably large number of software products are created. First, new tools are tested in non-scientific circles, and then articles appear in scientific journals, where the results of these approbations, roughly speaking, are copied.
It is precisely because of the constant increase in the number of programming automation tools in non-scientific circles that their scientific classification should be continuously updated. The fanatic programmer who creates such libraries pursues his own need for aesthetic satisfaction with a new work of his masterpiece art.
Let's automate programming. And then it turns out that it is already extremely automated. One has only to start performing operations of the same type, and funds appear that perform them themselves.
Object-oriented programming is no different from procedural. If you look at the source code of the Sulpheed email client written in the procedural C language, which supports several protocols: POP3, IMAP, NNTP. How does he work? For each protocol, a set of operations is implemented: receiving a list of letters, reading letters.
Net Framework is the result of automation of COM / DCOM technology. If before that you had to manually drive the UUID into the component definitions, now C # does it internally. It is possible to fasten COM components to a C # application. There is a special COM interface for this case. T.O. C # is nothing more than a simplified process of creating COM components in byte code.
Back to Sulpheed. So, in this mail client, when adding an account, the type of protocol for receiving mail is indicated. Each protocol defines different algorithms for reading letters. In this case, the letters in Sulpheed for each protocol are displayed uniformly. How this is done: the developer created a table of pointers for each procedure for working with a mailbox; Then, for each protocol, it implemented a set of operations and wrote their pointers into a table. T.O. polymorphism was implemented by means of a procedural language. If the program were written in C++, then the compiler would do this work. This is what I call programming automation. However, why was the C language chosen? Probably for performance reasons.
For the POP3 protocol, the distinguishing feature is that reading letters involves saving them on the user's computer. For IMAP, letters are stored on the mail server, and full access is provided for reading them. NNTP is a news protocol, and emails are sent via broadcast channels, the reading of which is provided without authentication.
What else is there in programming automation is snippets. The same vim is a full-fledged development environment or CAD software only due to the plugins that connect to it. There are certain commands that the user enters and receives a ready-made piece of code that can be filled with the necessary data.
However, it is impossible to remember a large number of commands; therefore, development environments with a graphical interface are also popular. IntelliJ IDEA and a number of similar development environments for various programming languages from JatBrains are crowding out all of its predecessors in the IDE market. And it has already superseded all the IDEs for the Java language. There are good reasons why Java developers prefer IDEA over similar Eclipse and NetBeans. Firstly, the environment is more convenient and its use is much more efficient. Secondly, routine code refactoring operations were automated in it.
CLion [32] is the only development environment for the C | C++ languages that first automated work with projects that use CMake as a build tool. This development environment uses CMakeLists.txt files to describe projects, which allows you to fully automate the routine operations of adding new source code files to the project. When you add a source file, CLion automatically updates CMakeLists.txt, adding a new file to its list. And when you update this text file, the Makefile generation for the entire project is automatically launched.
In addition, starting with the third version, CMake can itself automate adding new source code files to the list using the command
Since the main routine of the programmer is to create the same type of operations that are performed uniformly regardless of the specifics of the task, CLion allows you to generate a standard implementation of the constructor, field access methods, and the rest of the class at the user's discretion.
When you need to correct the spelling of a word that is written with two letters c, it does not matter where to add the letter
c before or after the existing letter
c. It’s the same in programming, it doesn’t matter what is automated, creating a method interface or its implementation. There are tools that generate an implementation using the method interface.
In C++, there is clearly not enough introspection. The developers of the ODB [33] object-relational mapping system felt this very well. Using this tool, the programmer describes the database structure using preprocessor directives. The ODB system uses this information to generate procedures for writing the structures marked with their help to relational tables.
The disadvantage of program code generators is the obsolescence of the standard on which the code is generated. ODB generated code in the 2014 standard. Some features of this language are declared to be tired in 2017. And now what is generated by the ODB system is not suitable for use with the new C++ language compiler. Who will undertake to update the code generator if every third year a new standard is released.
Another way to automatically implement a method is to directly generate new code during compilation. Metaprogramming on templates allows you to build algorithms for the compiler. However, C++ is clearly lacking introspection. Solves this Java problem with its annotations. The Hibernate library allows you to generate SQL queries knowing only the name of the procedure and its arguments. Using annotations, the fields of the structure are indicated, which is used for automatic database management.
It does not make sense to write a code generator for languages like Ruby, because it implements a reflection mechanism. There is no such mechanism in compiled languages. Therefore, it is advisable to create a code generator for them.
According to one classification, Perl and, after it, Ruby are recognized as super-high-level languages. Those. you can write a metaprogram on them. It is obvious that you do not need to synthesize a super-high-level language code.
Template Toolkit [34] is a tool for generating files, including and perl scripts by template. It is there that there is nesting, which allows us to talk about the implementation on it of knowledge modules of intelligent CAD software.
True, Russian researchers have already asked about the implementation of the UML diagram generator [5,35]. In addition, there is also a IPSP [36] system that made a huge impression on scientists.
Let's summarize what has been done to automate programming.
| World | CIS countries | DonNTU | |
| Coding Automation | Scratch, Block | DRAGON | Voice input |
| Test Automation | Fuzzing | ||
| Build Automation | CMake, Gradle | ||
| UML Design | Rational Rose | Synthesis of diagrams according to the description of Obl. | |
| Databases | ODB, Hibernate | SQL query generators | |
| Algorithm Synthesis | Lex / Yacc | IPSP | ? |
Programming automation tools are described in more detail in post-Soviet studies [37,38].
3. The essence of this scientifical research and innovation
Back to OOP and design patterns. The object-oriented structure of the program must comply with SOLID principles to provide flexibility in the development process. There are patterns that satisfy these principles, and antipatterns that, on the contrary, contradict them.
Let the system initially not know a single design pattern. She must bring them out of the principles of SOLID. To use GA, it is necessary to represent the pattern in binary code and derive the extremum function.
The extremum function should show how well the system complies with SOLID principles. The quality of the optimization process depends on the choice of this function.
There are many patterns that do not meet the requirements of the single responsibility principle. Let's synthesize new patterns that will satisfy all SOLID principles.
Let the SOLIDity is evaluated by five-point scale. This is the sum of the five characteristics that correspond to each principle. Let define the first characteristic
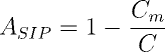
(4)
where Cm — count of classes with multiple responsibilities; C — total count of classes in the system.
How to determine that a class has several responsibilities. For this, the number of requirements is established, the change of which leads to its modification. A class with a single duty has exactly one reason for change.
I believe that the analysis of requirements consists in splitting the requirements so that each requirement corresponds to one class. And not that taught at the ATPO course.
A little more complicated is the task of determining the openness-closure of a system. This principle refers to openness for addition and closedness to change. Adding new requirements leads to the creation of new classes and not to the modification of existing ones. This should ensure that the system is resistant to errors.
Reflection mechanisms put software on the conveyor belt.
In the post-Soviet space, the development of technology and the subsequent automation of human labor is seen as the path to socialism. The capitalist countries see this as an increase in income tax [39] as a way to solve the problem of mass unemployment arising from the replacement of people in factories, service enterprises, etc. by cars.
Tyumentsev defines a sufficient condition for the linearity of the development process [40,41], as the observance of the principles of openness-closeness and a decrease in the size of the modules.
The restriction on code modification is obvious: changing one module entails an avalanche-like effect of propagating changes. Therefore, it is better to design the system so that the addition of new functionality is done by adding a new module, and does not require changes to the existing module.
The key principles of software engineering, which are often forgotten to be mentioned, appear in the search for ways to optimize the development process.
References
- Брукс Ф. Мифический человеко-месяц, или Как создаются программные системы / Ф. Брукс . — 2015. — 171 с. — URL: https://nsu.ru/xmlui/bitstream... .
- Мартин Р.К. Быстрая разработка программ. Принципы, примеры, практика: Пер. с англ. / Р.К. Мартин, Дж.В. Ньюкирк . — М. : Вильямс , 2004. — 725 с. — URL: http://www.williamspublishing.... .
- Страуструп Б. Язык программирования C++. 2-е изд [Электронный ресурс]. — URL: http://www.8361.ru/6sem/books/... .
- Pablo's SOLID Software Development [Электронный ресурс]. — 2008. — URL: https://lostechies.com/wp-cont... .
- Бикмуллина И.И. Автоматический синтез диаграмм классов языка UML на основе ассоциативных отношений предметной области : диссертация [Электронный ресурс]. — Казань , 2017. — URL: http://www.dslib.net/mat-obesp... .
- Бочкарёва Л.В. Системы автоматизации проектирования программного обеспечения. Работа в среде Rational Rose : учебно-метод. пособие для студ. спец.
Программное обеспечение информационных технологий
всех форм обуч. / Л.В. Бочкарёва, М.В. Кирейцев . — Мн. : БГУИР , 2006. — 38 с. - Якоб Р. Интерфейсы пользователя [Электронный ресурс]. — 2017. — URL: http://masters.donntu.ru/2017... .
- Ермаков И.Е. Объектно-ориентированное программирование: прояснение принципов? / И.Е. Ермаков . // Объектные системы . — № 1 (1). — 2010. — С. 130–135. — URL: https://cyberleninka.ru/articl... (дата обращения: 02.12.2019) .
- Крамаренко А.В. Разработка пользовательских интерфейсов на GTK+ [Электронный ресурс]. — 2011. — URL: http://masters.donntu.ru/2012... .
- Автоматический синтез программ – что нового? [Электронный ресурс]. // RSDN . — URL: https://www.rsdn.org/forum/phi... .
- Средства автоматизации проектирования программного обеспечения [Электронный ресурс]. — URL: https://poznayka.org/s86065t1.... .
- Система автоматизации отладки программного обеспечения [Электронный ресурс]. — URL: http://www.tehprog.ru/index.ph... .
- Новичков А. Rational Rose для разработчиков. Часть 2 [Электронный ресурс]. — URL: http://www.interface.ru/fset.a... .
- Дубров Д.В. Программирование: система построения проектов CMake. Учебник для магистратуры / Д.В. Дубров . — М. : Издательство Юрайт , 2016. — 422 с. — URL: https://aldebaran.ru/author/vl... .
- Clark M. Pragmatic Project Automation. How to Build, Deploy, and Monitor Java Applications / M. Clark . — The Pragmatic Bookshelf , 2004. — 172 pp. — URL: http://index-of.es/Programming... .
- Степанченко И.В. Методы тестирования программного обеспечения: Учебное пособие / И.В. Степанченко . — Волгоград : ВолгГТУ , 2006. — 74 с. — URL: http://window.edu.ru/resource/... .
- Воробьёв Л.О. К вопросу о самосинтезируемости программ / Л.О. Воробьёв, А.В. Григорьев .
// Материалы VI Международной научно-технической конференции
Современные информационные технологии в образовании и научных исследованиях
(СИТОНИ-2019) . — Донецк : ДонНТУ , 2019. — С. 256–266. - Современное визуальное программирование: Google Blockly [Электронный ресурс]. — URL: http://blogerator.org/page/sov... .
- Воробьёв Л.О. Разработка интегрированной CASE-системы для обучения студентов программированию / Л.О. Воробьёв, В.А. Полетаев, Д.Д. Моргайлов .
// Информатика, управляющие системы, математическое и компьютерное моделирование в рамках II форума
Инновационные перспективы Донбасса
(ИУСМКМ-2016): VII Международная научно-техническая конференция . — Донецк : ДонНТУ , 2016. — С. 163–168. — URL: http://iuskm.donntu.ru/electr... . - Ермаков И.Е. Двумерное структурное программирование / И.Е. Ермаков, Н.А. Жигуненко . // Современные информационные технологии и ИТ-образование . — № 6. — 2010. — С. 452–461. — URL: https://cyberleninka.ru/articl... (дата обращения: 21.12.2019) .
- Визуальное программирование–будущее написание кода [Электронный ресурс]. — URL: https://www.make-info.com/visu... .
- Чернышов В.Н. Теория систем и системный анализ : учеб. пособие / В.Н. Чернышов, А.В. Чернышов . — Тамбов : Изд-во Тамб. гос. техн. ун-та , 2008. — 96 с. — URL: http://window.edu.ru/resource/... .
- Compare-and-swap [Электронный ресурс]. // Wikipedia . — 2019. — URL: https://en.wikipedia.org/wiki/... .
- Фаззинг, фаззить, фаззер: ищем уязвимости в программах, сетевых сервисах, драйверах [Электронный ресурс].
// Журнал
Хакер
. — 2010. — URL: https://xakep.ru/2010/07/19/52... . - Что такое функциональное программирование? [Электронный ресурс]. // Stack Owerflow . — URL: https://ru.stackoverflow.com/q... .
- Кирютенко Ю.А. Объектно-ориентированное программирование. Язык Smalltalk / Ю.А. Кирютенко, В.А. Савельев .
—
М. :
Вузовская книга
, 2003. — 358 с. — URL: http://www.mmcs.sfedu.ru/jdown... . - Роджерсон Д. Основы COM : 2-е изд / Д. Роджерсон . — М. : Русская Редакция , 2000. — 228 с. — URL: http://index-of.es/Programming... .
- Язык программирвоания Ruby [Электронный ресурс]. — URL: https://www.ruby-lang.org/ru/ .
- Воробьёв Л.О. Анализ специфики реализации объектного подхода в современных технологиях программирования / Л.О. Воробьёв, А.В. Григорьев . // Программная инженерия: методы и технологии разработки информационновычислительных систем (ПИИВС-2018): сборник научных трудов II научно-практической конференции (студенческая секция) . — Донецк : ДонНТУ , 2018. — Том 2. — С. 27–32. — URL: http://pi.conf.donntu.ru/coll... .
- Курочкин В.М. Автоматизация программирования [Электронный ресурс]. — URL: https://www.booksite.ru/fullte... .
- Степанова А.С. Конвергентная технология человеко-машинного взаимодействия, на основе программирования / А.С. Степанова . // Объектные системы . — № 3 (5). — 2011. — С. 9–14. — URL: https://cyberleninka.ru/articl... (дата обращения: 02.12.2019) .
- CLion [Электронный ресурс]. — мощный инструмент для мощного языка! , 2019. — URL: https://jetbrains.ru/products/... .
- Code Synthesis Tools. C++ Object Persistence with ODB [Электронный ресурс]. — 2015. — URL: https://www.codesynthesis.com/... .
- Wardley A. Генерация контента сайта с использованием Template Toolkit [Электронный ресурс]. — 2000. — URL: http://www.codenet.ru/webmast/... .
- Бикмуллина И.И. Технология автоматизированного синтеза информационных систем с помощью семантических моделей предметной области / И.И. Бикмуллина . // Открытые семантические технологии проектирования интеллектуальных систем (OSTIS-2015) . — Минск : БГУИР , 2015. — С. 445–450. — URL: https://libeldoc.bsuir.by/hand... (дата обращения: 03.12.2019) .
- Ильин А.В. О двух направлениях в автоматизации программирования [Электронный ресурс]. — URL: http://ubs.mtas.ru/bitrix/comp... .
- Вичугова А. А. Автоматизация процесса разработки программного обеспечения: методы и средства / А. А. Вичугова . // Прикладная информатика . — № 3(63). — Томск : ТПУ , 2016. — Том 11. — С. 63–75. — URL: http://earchive.tpu.ru/bitstre... .
- Соловьев Н.А. Системы автоматизации разработки программного обеспечения / Н.А. Соловьев, Е.Н. Чернопрудова . — Литрес , 2012. — 230 с. — URL: https://pda.litres.ru/e-n-cher... .
- Форд М. Роботы наступают: Развитие технологий и будущее без работы [Электронный ресурс]. — М. : Альпина нон-фикшн , 2016. — URL: https://royallib.com/book/ford... .
- Тюменцев Е.А. О формализации процесса разработки программного обеспечения / Е.А. Тюменцев . // Математические структуры и моделирование . — № 3(43). — 2017. — С. 96–107. — URL: https://cyberleninka.ru/articl... (дата обращения: 16.12.2019) .
- Тюменцев Е.А. Уточнение к статье
о формализации процесса разработки программного обеспечения
/ Е.А. Тюменцев . // МСиМ . — № 1 (45). — 2018. — С. 144–147. — URL: https://cyberleninka.ru/articl... (дата обращения: 16.12.2019) .