
Abstract
When writing this essay, the master's work is not yet complete. Final completion: May 2021. The full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.
Содержание
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study
- 3. Overview of research and development
- 4. Overview of the traffic management system and V2V, V2I, I2V technologies in the Smart City development concept
- 5. Identification of the vehicle
- 6. Overview of software interfaces for parallel execution of algorithms on the GPU
- 6.1 Programming interface for parallel execution of algorithms on GPU CUDA
- 6.2 Programming interface for parallel execution of algorithms on GPU OpenCL
- 6.3 Programming interface for parallel execution of algorithms on the GPU Directcompute
- 6.4 Selecting the software interface for parallel execution of the algorithm on the GPU
- Conclusions
- Source list
Introduction
In the modern world, there are a large number of problems related to ensuring the safety of vehicles.one of the ways to solve this problem is to increase the number of traffic flows. This problem is especially applicable to large cities, where several hundred thousand, and in some cases millions of cars and other vehicles are moving on the streets, thereby increasing the chance of an emergency on the roads. In this regard, systems that perform calculation and construction of the trajectory that will be the most bladeless and will not create problems for others are widely used. So many companies have taken up the issue of creating an Autonomous vehicle (PBX), the essence of which will be to manage it without mediocre human participation, which should reduce the level of road accidents and other emergencies. In the master's work, the study of the subsystem for identifying the parameters of the PBX movement is carried out, the essence of which is to determine the trajectory of the PBX movement knowing its parameters that were obtained during its movement. Since the subsystem requires large resources due to the fact that all actions will occur while driving in real time, high-performance computing measurements that are performed in parallel on the GPU will be used for the most accurate and efficient operation. The master's thesis analyzes the efficiency of the PBX parameter identification subsystem and its implementation on a parallel architecture.
1. Relevance of the topic
The relevance is to improve the level of safety and organization of road traffic. One of the directions is to reduce the influence of the human factor through the use of modern computer systems and the introduction of various Autonomous vehicles. And also to increase the efficiency of this subsystem, since at its low speed, the work becomes less useful, which can lead to some consequences. In the master's work, the issues of ensuring the speed of the subsystem for identifying the movement parameters of an Autonomous vehicle are considered.
2. The purpose and objectives of the study
The purpose of this work is to analyze the efficiency of the subsystem for identifying the movement parameters of an Autonomous vehicle, implemented on parallel architectures.
The following tasks will be solved in the master's thesis:
- To develop a subsystem of identification of parameters of movement of Autonomous vehicles using a parallel system;
- To analyze the different existing parallel architectures and choose the most effective for the implementation of the subsystem.
3. Overview of research and development
For several years now, many companies have been actively developing, modeling, and testing automated systems based on which unmanned vehicles, both passenger and cargo, land, air, and others, will perform their movement. The most actively engaged in this issue are such large companies as Tesla, Google, BMW, along with the Chinese search engine Baidu, General Motors, Audi and others. Having studied this topic more deeply, it turned out that almost all major car brands independently or in conjunction with others, develop and test their systems. But not only car companies develop such systems, many Universities in the world are engaged in modeling and developing subsystems. this list also includes our DonNTU, where employees of the Department of computer engineering are engaged in: Sergey Krivosheev, Professor Alexander Anoprienko [1, 2, 3, 4].
4. Overview of the traffic management system and vehicle-to-vehicle(V2V), Vehicle-to-infrastructure(V2I), Invisible-to-Visible(I2V) technologies in the Smart City development concept
According to who, half of the world's population lives in cities, and according to the UN forecast, by 2050, about 85% of the World's population will prefer an urban lifestyle. Citizens will account for about 80% of the world's GDP. In Russia, as of September 2019, 74% of the population is urban residents. Rapid urbanization is a challenge for municipalities, which must create conditions for the expected quality of life, especially in terms of comfort and security. This is a very difficult task, because the urban infrastructure is already working with the maximum load, and with the growth of the population of megacities, there is a threat of its collapse. To solve this problem, the smart city concept was created [5].
In order for the system of unmanned transport in megacities to function as efficiently as possible, the urban road transport infrastructure must be formed, which provides coverage of transport infrastructure objects with new generation networks and sensors. In addition, in the Smart City concept, it is planned to organize Parking zones and gas stations for unmanned vehicles [6].
An unmanned vehicle interacts with the environment and Smart City objects via a network, so there are several systems: vehicle-to-vehicle (V2V), vehicle-to - infrastructure (V2I), and (Invisible-to-Visible), which allows drivers to “see the invisible”. Figure 1 shows a plan for ensuring the development of systems that allow Autonomous vehicles to move efficiently around the city.
V2V is a wireless communication system that allows two vehicles to interact by exchanging information about road conditions, while excluding human involvement. Thus, this system allows the car to find out information about the speed, location, etc. of another car Online [7].
V2I is a wireless communication system that is similar to V2V, but in which the vehicle exchanges information with infrastructure objects, such as traffic lights, road signs, etc. And also get information in the opposite direction[8].
I2V is a new technology that was developed by Nissan, this system collects and analyzes data from internal and external sensors (including those installed on other cars), as well as information stored in the cloud service. Thanks to this, the system monitors the situation around the car and predicts what awaits it on the way.
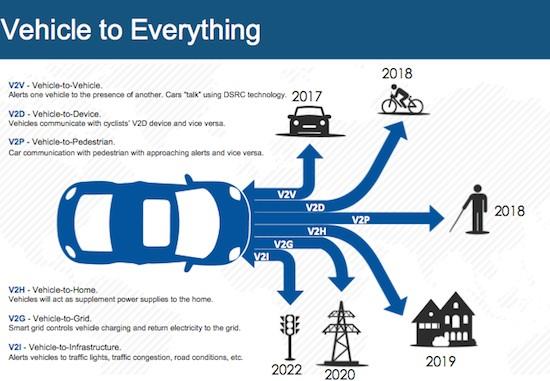
Figure 1. Support plan for the development of systems that enable Autonomous vehicles to move efficiently around the city
5. Identification of the vehicle
Identification of vehicle movement parameters is one of the methods that provides Autonomous vehicle movement. This method is performed using the mathematical method of least squares . This method has shown its effectiveness in comparison with others, so it formed the basis of the subsystem. The work of OLS in the system consists in the fact that, having received the initial data, the choice of polynomials is made for constructing the regression analysis equation, which can be of several types (hyperbolic, quadratic, etc.). The number of coefficients that will be used to identify the driving parameters of an Autonomous vehicle is of great importance, since each equation has a different number of parameters. Figure 2 shows the principle of operation of the numerical method of the method of naming squares (OLS).
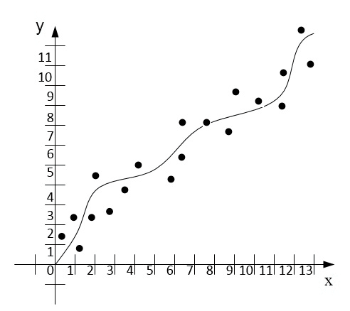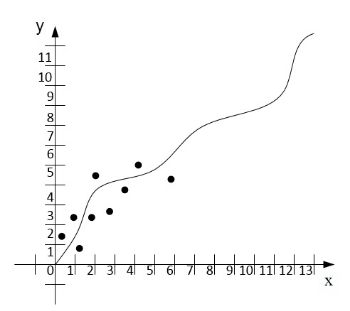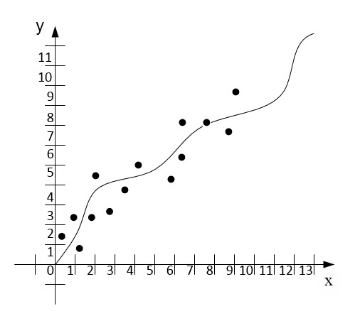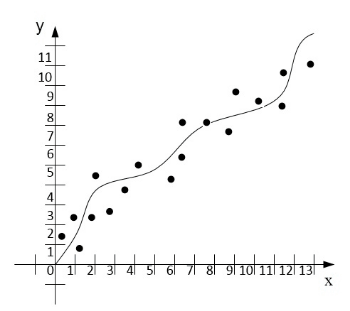
Figure 2. The principle of operation of the numerical method the method of naming squares
(animation: 13 frames, 155 kilobytes)
To model the most accurate vehicle trajectory, you need to use parallel calculations, since they will help the identification process become more efficient, which will allow the system to work faster and more accurately determine the further path of movement of an Autonomous vehicle. Since the system receives and calculates a large number of parameters from which it is necessary to obtain coefficients using least squares equations, parallel execution of the program algorithms will be used to calculate them, which in General will give an effective construction of the trajectory.
6. Overview of software interfaces for parallel execution of algorithms on the GPU
One of the promising directions in the field of parallel global optimization is the use of graphics accelerators (GPUs), which are in demand in solving a number of computationally time-consuming tasks. However, in the field of global optimization, the potential of graphics accelerators has not yet been fully revealed. GPU computing is the use of the GPU for computing technical, scientific, and everyday tasks. GPU computing involves using the CPU and GPU with a heterogeneous selection between them, namely: the CPU takes over the sequential part of the programs, while the time-consuming computational tasks remain the GPU. This results in parallelization of tasks, which speeds up information processing and reduces the execution time. the system becomes more productive and can simultaneously process more tasks than before. However, to achieve this success, hardware support alone is not enough. in this case, you also need to support software so that the application can transfer the most time-consuming calculations to the GPU [9].
There are several reasons why GPUs are more efficient: first, the CPU has only a small number of cores (up to 16 in advanced models) that run at high clock speeds independently of each other. Each CPU core is a powerful computing device. The GPU, on the other hand, runs at a low clock speed and has hundreds of simpler computing elements. Second, a significant portion of the CPU chip is occupied by high-speed cache memory, while almost the entire GPU consists of arithmetic-logic blocks. Therefore, GPUs are particularly effective in tasks where the number of arithmetic operations is large compared to operations on memory. For global optimization methods, an operation that can be efficiently implemented on the GPU is parallel calculation of many values of the objective function at once. Naturally, this requires implementing a procedure for calculating the function value on the GPU. Data transfers from the CPU to the GPU will be minimal: you only need to pass the coordinates of the test points to the GPU and get back the function values at these points. Functions that determine the processing of test results in accordance with the algorithm and require working with a large amount of accumulated search information can be effectively implemented on the CPU [10]. The scheme of information exchanges in the GPU algorithm is shown in figure 3.
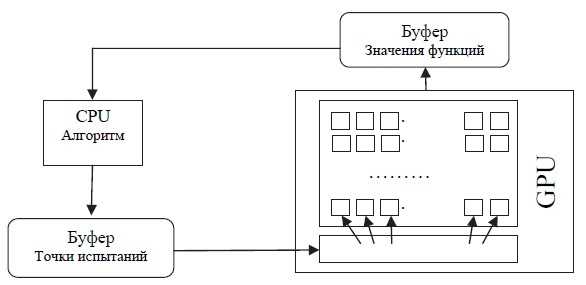
Figure 3. Scheme of information exchanges in the GPU algorithm
There are several software interfaces for parallel execution of algorithms on the GPU.below is a description of the most famous of them such as CUDA, OpenCL and Direct compute.
6.1 Programming interface for parallel execution of algorithms on GPU CUDA
CUDA technology is an Nvidia hardware and software computing architecture based on an extension of the C language, which makes it possible to organize access to the instruction set of the graphics accelerator and manage its memory when organizing parallel computing. CUDA helps implement algorithms that are executable on video accelerator GPUs [11].
Although the complexity of programming the GPU using CUDA is quite high, it is lower than with earlier GPGPU solutions. Such programs require splitting the application between multiple multiprocessors, similar to MPI programming, but without splitting the data that is stored in shared video memory. And since CUDA programming for each multiprocessor is similar to OpenMP programming, it requires a good understanding of memory organization. But, of course, the complexity of development and migration to CUDA strongly depends on the application [11].
Main CUDA restrictions:
- Lack of recursion support for running functions;
- Minimum block width of 32 threads;
- A closed CUDA architecture owned by Nvidia.
6.2 Programming interface for parallel execution of algorithms on GPU OpenCL
Unlike nVidia CUDA, AMD Stream, etc., OpenCL was originally intended to be multi-platform, i.e. the OpenCL program should run on different types of GPUs (different manufacturers) without changes in the code. Such a program should run unchanged even on a CPU without a GPU, although in this case it may run significantly slower than on the GPU [12].
The OpenCL program works with so-called platforms. A platform is a software package that is delivered by the corresponding hardware developer. Each platform includes an ICD (Installable Client Driver), an Opengl programming interface for working with devices that this platform supports [12]. Figure 4 shows the OpenCL program's operation with hardware.
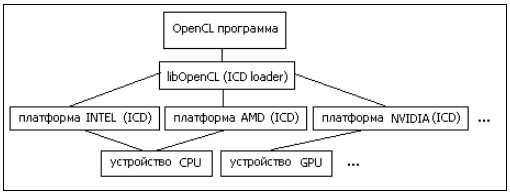
Figure 4. OpenCL program working With hardware
The platform model provides a high-level description of a heterogeneous system. The Central element of this model is the concept of a host-the primary device that manages OpenCL calculations and performs all user interactions. The host is always represented in a single instance, while OpenCL devices that run OpenCL instructions can be represented in the plural. An OpenCL device can be a CPU, GPU, DSP, or any other processor in the system that is supported by the OpenCL drivers installed in the system. OpenCL devices are logically divided by the model into computing modules, which in turn are divided into processing elements. Calculations on OpenCL devices actually occur on processing elements [13].
6.3 Programming interface for parallel execution of algorithms on the GPU Directcompute
DirectCompute technology first appeared in the 11th version of DirectX, and then it was adapted for the 10th and 9th versions. Before its introduction, developers of graphics applications had to be torn between CUDA and FileStream-similar technologies from NVIDIA and AMD. With the release of DirectX 11 everything became much easier [14].
DirectCompute is a set of APIs designed for organizing GPU computing. That is, using this technology, tasks for calculating complex graphic effects are transferred from the Central processor to those integrated into video cards. Using this DirectX feature does not just allow you to offload the CPU – in some cases, GPU-oriented computing shaders cope with calculations much faster and more efficiently than General-purpose processors [14].
6.4 Selecting the software interface for parallel execution of the algorithm on the GPU
After reviewing all available software and computing architectures, Nvidia CUDA was chosen as the software interface for parallel execution of the algorithm on the GPU. CUDA is a more Mature technology with a well-developed toolchain development. Large scientific communities usually prefer to use CUDA (not least because NVIDIA invests in this technology and there are a large number of libraries for its implementation). OpenCL is compatible with devices other than NVIDIA video cards and is slightly less convenient to use. In General, both technologies are very close to each other. Writing effective code for both CUDA and other programs is difficult.
CUDA also has advantages over the traditional approach to GPGPU computing compared to other software interfaces:
- The CUDA application programming interface is based on the standard C programming language with extensions, which simplifies the process of learning and implementing the CUDA architecture;
- CUDA provides access to thread-shared memory of 16 KB per multiprocessor, which can be used to organize a cache with a wide bandwidth, compared to texture samples;
- More efficient data transfer between system and video memory;
- No need for graphical APIs with redundancy and overhead;
- Linear memory addressing, and gather and scatter, the ability to write to arbitrary addresses;
- Hardware support for integer and bit operations [11].
Conclusions
At the time of writing this abstract, the research performed:
- Overview of software interfaces for parallel execution of algorithms on the GPU;
- Overview of the traffic management system and vehicle-to-vehicle(V2V), Vehicle-to-infrastructure(V2I), Invisible-to-Visible(I2V) technologies in the Smart City development concept.
Further research is planned to focus on the following aspects:
- To implement a subsystem of identification of motion parameters of ATS, parallel system;
- Perform an analysis of the efficiency of the subsystem for identifying the PBX movement parameters when implemented on various parallel systems.
Source list
- Аноприенко А.Я., Кривошеев С.В., Потапенко В.А. Моделирование процесса обработки информации в интегрированной навигационной системе // Тези доповідей міждержавної науково-методичної конференції
Комп'ютерне моделювання
30 червня – 2 липня 1999 р., м. Дніпродзержинськ. – Дніпродзержинськ. – 1999. С. 114-115. - Кривошеев С.В. Исследование эффективности параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства // Научные труды Донецкого национального технического университета. Выпуск № 1(10)-2(11). Серия
Проблемы моделирования и автоматизации проектирования
. – Донецк, ДонНТУ, 2012. С. 207-214. - Аноприенко А.Я., Кривошеев С.В. Моделирование динамики речного судна на базе системы Matlab/Simulink //
Прогрессивные технологии и системы машиностроения
: Международный сборник научных трудов. – Донецк: ДонГТУ, 2000. Вып. 9. С. 13-20. - Аноприенко А.Я., Кривошеев С.В. Разработка подсистемы моделирования движения судна по заданной траектории // Научные труды Донецкого национального технического университета. Выпуск 12. Серия
Вычислительная техника и автоматизация
. – Донецк, ДонГТУ, ООО «Лебедь», 1999. С. 197-202. - Умный транспорт как часть экосистемы технологий умного города [Электронный ресурс]. // Secuteck – Режим доступа: https://www.secuteck.ru/articles/umnyj-transport-kak-chast-ehkosistemy-tekhnologij-umnogo-goroda
- Цифровая мобильность [Электронный ресурс]. // 2030.mos – Режим доступа: https://2030.mos.ru/n/n3/
- Евстигнеев И. А., Шмытинский В. В. Вопросы взаимодействия беспилотных транспортных средств с дорожной инфраструктурой // Транспорт Российской Федерации. Журнал о науке, практике, экономике. 2019. №6 (85).
- Connected Car: V2V, V2I, V2X, V2P, V2G, V2D. Стандартизация, возможности и темпы развития умных автомобилей в России и в мире [Электронный ресурс]. // 1234g – Режим доступа: http://1234g.ru/novosti/v2v-v2i-v2x-v2p-v2g-v2d-connected-car
- Параллельные вычисления на GPU NVIDIA или суперкомпьютер в каждом доме [Электронный ресурс]. // NvWorld – Режим доступа: https://nvworld.ru/articles/cuda-parralel-for-home/
- Лебедев И.Г., Баркалов К.А. Реализация параллельного алгоритма глобального поиска на GPU // Вестник ПНИПУ. Аэрокосмическая техника – Пермь: ПНИПУ, 2014. Выпуск 39 С. 64–82.
- Nvidia CUDA ? неграфические вычисления на графических процессорах [Электронный ресурс]. // IXBT – Режим доступа: https://www.ixbt.com/video3/cuda-1.shtml
- Технология параллельного программирования OpenCL [Электронный ресурс]. // Mechanoid – Режим доступа:http://mechanoid.su/parallel-opencl.html
- Казённов, А.М. Основы технологии CUDA и OpenCL /А.М. Казённов. — Москва: Московский физико-технический институт, 2013. — 65с.
- Direct Compute технология [Электронный ресурс]. // NBC12 – Режим доступа:https://nbc12.ru/to-note/item/37-directcompute