Анализ алгоритмов фильтрации спама
Авторы:Е.И. Лютова,И.А. Коломойцева Источник: Международная научно-техническая конференция "Информатика, управляющие системы, математическое и компьютерное моделирование 2020" с.116-120 [Ссылка на сборник]
Аннотация: В данной статье приведен анализ алгоритмов обнаружения спама. Приведены математические модели алгоритмов, а также дана их классификация. Выделены перспективные направления исследования точной идентификации спама.
Введение
Спам – это информация, широко рассылаемая, людям, не выразившим желания её получать. Для борьбы со спамом предпринимаются меры по его устранению, но график, приведенный на рисунке 1, показывает их неэффективность.
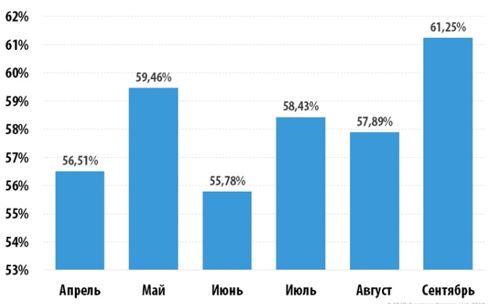
Рисунок 1 – Доля спама в почтовом трафике за 2018 г.
Статистика (см. рис. 1) демонстрирует то, что есть потребность в исследовании новейших, а также модификации раннее имеющихся алгоритмов фильтрации спама [9].
Целью данной работы является исследование распространённых и результативных алгоритмов с поддержкой машинного обучения.
Формальная постановка задачи классификации информации
Пусть D = {d(1),….,d(N) } — множество документов, C = {c1 ,…,cM} — множество категорий, Φ — целевая функция, которая по паре (d(i) ,cj), определяет, относится ли документ d(i) к категории cj(1 или True) или нет (0 или False). Задача классификации состоит в построении функции Ф̃, максимально близкой к Ф [1]. В такой постановке задачи следует отметить, что о категориях и документах нет никакой дополнительной информации, кроме той, которую можно извлечь из самого документа. Если классификатор выдает точный ответ:
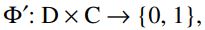
Формула 1
то классификация называется точной. Если классификатор определяет степень подобия (Categorization Status Value) документа: CSV:
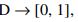
Формула 2
то классификация называется пороговой [2].
C учетом данных понятий рассмотрим алгоритмы фильтрации спама, которые основываются на машинном обучении.
Наивная байесовская модель
В основе наивной байесовской модели лежит теорема Байеса:
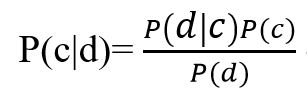
Рисунок 2 – Формула теоремы Байеса
где, P(c|d) — вероятность что документ d принадлежит классу c, именно её нам надо рассчитать; P(d|c) — вероятность встретить документ d среди всех документов класса c; P(c) — безусловная вероятность встретить документ класса c в корпусе документов; P(d) — безусловная вероятность документа d в корпусе документов.
Теорема Байеса позволяет переставить местами причину и следствие. Зная с какой вероятностью, причина приводит к некоему событию, эта теорема позволяет рассчитать вероятность того что именно эта причина привела к наблюдаемому событию.
Цель классификации состоит в том чтобы понять к какому классу принадлежит документ, поэтому необходимо не сама вероятность, а наиболее вероятный класс. Байесовский классификатор использует оценку апостериорного максимума (Maximum a posteriori estimation) для определения наиболее вероятного класса. Грубо говоря, это класс с максимальной вероятностью[3].
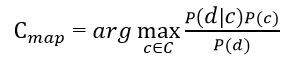
Рисунок 2 – Оценка апостериорного максимума
Необходимо рассчитать вероятность для всех классов и выбрать тот класс, который обладает максимальной вероятностью. Стоит обратить внимание на то, что знаменатель (вероятность документа) в формуле на рисунке 2 является константой и никак не может повлиять на ранжирование классов, поэтому его можно опустить.
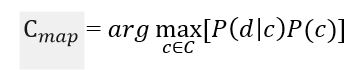
Рисунок 3 – Оценка апостериорного максимума без знаменателя
«Наивность» данной модели классификатора заключается в том, что она использует наивное допущение, что слова, входящие в текст документа независимы друг от друга. Исходя из этого условная вероятность документа аппроксимируется произведением условных вероятностей всех слов, входящих в документ.
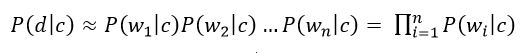
Рисунок 4 – Произведение условных вероятностей всех слов, входящих в документ
где wi – количество раз сколько i–ое слово встречается в документах класса c
Подставив полученное выражение в формулу на рисунке 3 получим:
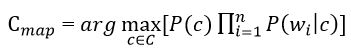
Рисунок 5 – Оценка апостериорного максимума с логарифмами вероятностей
В формуле на рисунке 5 чаще всего используют вместо самих вероятностей используют логарифм этих вероятностей. Поскольку логарифм – монотонно возрастающая функция, то класс с с наибольшим значением логарифма вероятности останется наиболее вероятным. Тогда:
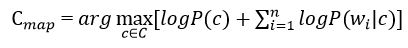
Рисунок 6 – Оценка апостериорного максимума с условной вероятностью документа
Далее необходимо провести оценку вероятности класса и слова в классе. Они рассчитывается по формулам:
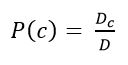
Рисунок 7 – Оценка вероятности класса
где Dc – количество документов принадлежащих классу с; D – общее количество документов в обучающей выборке.
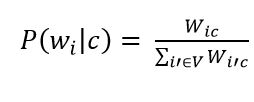
Рисунок 8 – Оценка вероятности слова в классе
где V - словарь корпуса документов (список всех уникальных слов)
Следующим шагом необходимо применить аддитивное сглаживание (сглаживание Лапласа). Это нужно для того чтобы слова, которые не встречались на этапе обучения классификатора не имели нулевую вероятность. Следовательно, необходимо прибавить единицу к частоте каждого слова.
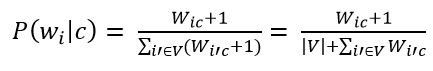
Рисунок 9 – Оценка вероятности слова в классе с прибавлением единицы
Подставив все полученные оценки вероятностей (формулы на рисунках 7 и 9) получим окончательную формулу модели наивного байесовского классификатора.
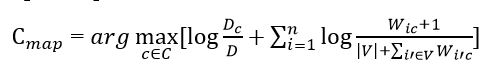
Рисунок 10 – Формула наивного байесовского классификатора
Метод Байеса используется для определения несанкционированных рекламных рассылок по электронной почте (спама). При этом рассматривается учебная база — два массива электронных писем, один из которых составлен из спама, а другой — из обычных писем. Для каждого из корпусов подсчитывается частота использования каждого слова, после чего вычисляется весовая оценка (от 0 до 1), которая характеризует условную вероятность того, что сообщение с этим словом является спамом. Значение веса, близкое к 0.5, не учитываются при интегрированном подсчете, поэтому слова с такими весами игнорируются и изымаются из словарей. [4]
Плюсами данного подхода к фильтрации спама являются:
- Метод наивного байесовского классификатора прост в использовании
- Обладает высокой эффективностью в отсеивании спама
- Высокая скорость работы
- Hа данном методе простроены большое количество современных спам-фильтров ( Mozilla Thunderbird 0.8, BayesIt! 0.6.0, SpamAssassin 3.0.0 rc3). [5]
Впрочем, у метода есть и принципиальный недостаток: он базируется на предположении, что одни слова чаще встречаются в спаме, а другие — в обычных письмах, и неэффективен, если данное предположение неверно. Впрочем, как показывает практика, такой спам даже человек не в состоянии определить «на глаз» — только прочтя письмо и поняв его смысл. Существует также алгоритмы, позволяющие добавить много лишнего текста, иногда тщательно подобранного, чтобы «обмануть» фильтр.
Еще один, не принципиальный, недостаток, связанный с реализацией — метод работает только с текстом. Зная об этом ограничении, можно вкладывать рекламную информацию в картинку, текст же в письме либо отсутствует, либо не несет смысла. Против этого приходится пользоваться либо средствами распознавания текста, либо старыми методами фильтрации — «черные списки» и регулярные выражения (так как такие письма часто имеют стереотипную форму).
4.3 Метод опорных векторов
Метод опорных векторов (Support Vector Mashine, SVM) относится к группе граничных методов классификации. Он определяет принадлежность объектов к классам с помощью границ областей. Будем рассматривать только бинарную классификацию, т. е. классификацию только по двум категориям c и c1, принимая во внимание то, что этот подход может быть расширен на любое конечное количество категорий. Предположим, что каждый объект классификации является вектором в N-мерном пространстве. Каждая координата вектора — это некоторый признак, количественно тем больший, чем больше этот признак выражен в данном объекте. Преимущества метода:
- Один из наиболее качественных методов;
- Возможность работы с небольшим набором данных для обучения;
- Сводимость к задаче выпуклой оптимизации, имеющей единственное решение.
Недостатки метода: сложная интерпретируемость параметров алгоритма и неустойчивость по отношению к выбросам в исходных данных.[6]
Алгоритм k-ближайших соседей
Метод близлежащих соседей — простой метрический классификатор, базирующийся в оценивании сходства объектов. Классифицируемый объект принадлежит к тому классу, которому относятся близкие к нему объекты обучающей подборки. один из простых алгоритмов систематизации, по этой причине в настоящих задачах он нередко оказывается малоэффективным. Кроме точности систематизации, вопросом данного классификатора считается темп систематизации: в случае если в учащей выборке N объектов, в тестовом выборе M объектов, но размерность пространства — K, в таком случае число действий с целью систематизации испытательной подборки может быть оценено равно как O(K*M*N). Данный метод при идентификации спама не достигает высокой точности, что делает его достаточно неэффективным при фильтрации не нужной информации. [7]
Преимущества метода:
- Возможность обновления обучающей выборки без переобучения классификатора;
- Устойчивость алгоритма к аномальным выбросам в исходных данных относительно простая программная реализация алгоритма;
- Легкая интерпретируемость результатов работы алгоритма;
- Хорошее обучение в случае с линейно неразделимыми выборками.
Недостатки метода:
- Репрезентативность набора данных, используемого для алгоритма
- Высокая зависимость результатов классификации от выбранной метрики
- Большая длительность работы из-за необходимости полного перебора обучающей выборки
- Невозможность решения задач большой размерности по количеству классов и документов[8].
Выводы
В ходе выполнения данной работы проанализированы алгоритмы классификации для идентификации спама. После детального изучения выявлены недостатки и плюсы рассмотренных подходов.
Как результат проделанного обзора можно отметить следующие направления исследований:
- исследование плохо изученных алгоритмов (измененный байесовский классификатор);
- разработка комбинированных способов.
В частности, интерес представляет метод байесовского классификатора, так как он обладает более высокой достоверностью и достаточно прост в реализации. Перспективами исследования являются разработка собственного алгоритма классификации спама на основе наивного байесовского классификатора.
Cписок литературы
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. – М.: Либроком, 2009. – 77 с.
- Методы автоматической классификации текстов [электронный ресурс], - Режим доступа:[Ссылка] – Заглавие с экрана.
- Наивный байесовский классификатор [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. – М.: Либроком, 2009. – 88- 89 с.
- Применимость байесовского классификатора для задачи определения спама [электронный ресурс], - Режим доступа: [Ссылка] - Заглавие с экрана.
- Алгоритм Роккио [электронный ресурс], Режим доступа: [Ссылка] - Заглавие с экрана.
- Метод ближайших соседей [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Методы автоматической классификации текстов [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Доля спама в российском почтовом трафике превышает 60 процентов [электронный ресурс], - Режим доступа: [Ссылка] - Заглавие с экрана.