Overview of spam filtering algorithms
Авторы:Lyutova E.I., Kolomoytseva I.A., Gilmanova R.R Источник: ИССЛЕДОВАНИЯ И ДОСТИЖЕНИЯ МОЛОДЫХ УЧЕНЫХ В ОБЛАСТИ НАУКИ,Сборник докладов научно-технической конференции для молодых учёных, 2020 год, с.81-86 [Ссылка на сборник в РИНЦ ]
Abstract: This article presents an overview and analysis of spam detection algorithms. The mathematical model of the algorithms and their classification are presented. Promising areas of research on the exact identification of spam are highlighted.
Keywords:spam, classification, machine learning, spam identification algorithms, probabilistic classifiers, linear classifiers
Spam is information that is widely distributed to people who do not want to receive it. In order to combat spam some measures are being taken to eliminate it, but the schedule given in Figure 1 shows their inefficiency.
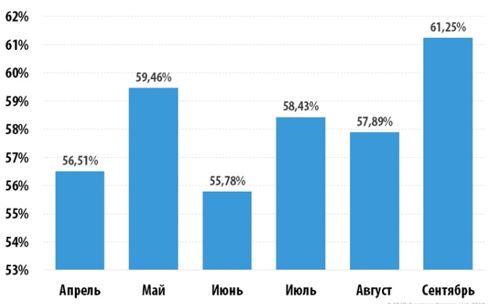
Figure 1 – Schedule of spam in 2018 year
Formal problem statement of information classification
Let D = {d(1),….,d(N) } — be a set of documents C = {c1 ,…,cM} be a set of categories, Φ be an objective function that, by a pair(d(i) ,cj),determines whether a document d(i) belongs to a category cj(1 or True) or not (0 or False). The classification problem is to construct a function Ф̃,as close as possible to the Ф [1]. In this formulation of the problem, it should be noted that there is no additional information about the categories and documents except ones that can be extracted from the document itself. If the classifier gives an exact answer:
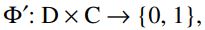
Formula 1
then the classification is called exact. If the classifier determines the degree of similarity ( Categorization Status Value ) of the document:
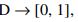
Formula 2
then the classification is called threshold [2].
With these concepts in mind, let us consider spam filtering algorithms that are based on machine learning.
Naive Bayesian model
The naive Bayes model is based on the Bayes theorem:
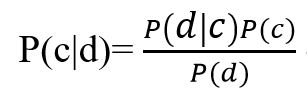
Formula 3
where, P(c|d) — ) is the probability that document d belongs to class c, that is we need to calculate it; P(d|c) — is probability to meet document d among all documents of class c; P(c) — is unconditional probability of meeting a document of class c in the document corpus; P(d) — is unconditional probability of document d in the body of documents.
Bayes' theorem allows us to rearrange the cause and effect. Knowing the probability with which the cause leads to a certain event, the theorem allows us to calculate the probability that it is this reason that led to the event observed.
The purpose of text classification according to Bayes' theorem is to understand what class a document belongs to, so you do not need the probability of the document but the most probable class. Bayesian classifier uses maximum a posteriori estimation to determine the most probable class. Roughly speaking, this is a class with maximum probability [7].
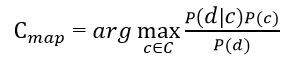
Formula 4
It is necessary to calculate the probability for all category classes and choose the class with maximum probability. It is worth paying attention to the fact, that the denominator (the document likelihood) in the formula (4) is the constant and can not effect the class ranking, so it can be omitted
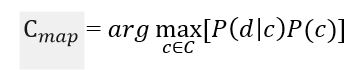
Fomula 5
The «naivety» of the classifier model is that it uses the naive assumption that the words in the text of the document are independent of each other. The «naivety» of the classifier model is that it uses the naive assumption that the words in the text of the document are independent of each other. Based on this, the conditional probability of a document is approximated by the multiplication of the conditional probabilities of all the words included in the document.
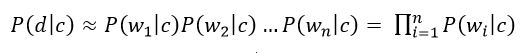
Formula 6
where wi – is the number of times word i - th occurs in the documents of class c. Substituting the resulting expression into formula (5) we obtain:
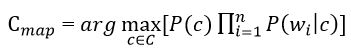
Formula 7
In the formula (7), the logarithm of these probabilities is most often used instead of the probabilities themselves. Since the logarithm is a monotonically increasing function,class с with the highest probability logarithm will remain the most probable. Then:
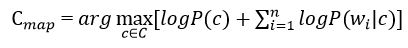
Formula 8
Then, you need to assess the probability of the category class and the words in the class. They are calculated by the formulas (9) and (10):
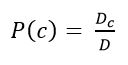
Formula 9
where Dc – is the number of the documents belonging to class с; D –is the total number of documents in the training set.
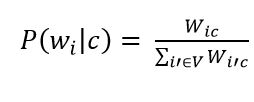
Formula 10
where V is the dictionary of the documents corpus (a list of all unique words).
The next step is to apply additive smoothing (Laplace smoothing). It is necessary for words that did not occur in the training set of the classifier to have no zero probability. Therefore, it is necessary to add 1 to the frequency of each word.
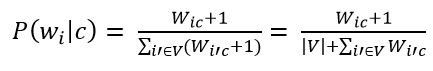
Formula 11
Substituting all the obtained probability estimates (i.e. formulas 9, 11) we obtain the final formula for the model of naive Bayes classifier.
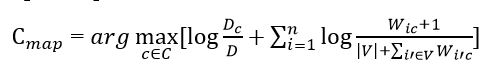
Formula 12
The Bayesian method is used to detect unauthorized advertising mailings by email (spam). At the same time, the training base is considered, i.e. two arrays of emails, one of which is composed of spam, and the other of ordinary emails. For each of the cases, the frequency of use of each word is calculated, after which a weight estimate (from 0 to 1) is calculated, which characterizes the conditional probability that a message with this word is spam. Weight values close to 0.5 are not taken into account under integrated counting, therefore words with such weights are ignored and removed from dictionaries [3].
The advantages of this approach to spam filtering are:
- the method of naive Bayes classifier is easy to use;
- It is highly effective in filtering spam;
- high speed of calculation;
- This method has a large number of modern filters spam (Mozilla Thunderbird 0.8, BayesIt ! 0.6.0 , SpamAssassin 3.0.0 rc3 ) [8].
However, the method has a fundamental flaw. Is is based on the assumption that some words are more likely to be found in spam, and others in ordinary letters. It is ineffective if this assumption is incorrect. However, as practice shows, even a person is not able to determine such spam «by eye», i.e. only by reading the letter and understanding its meaning. There is a Bayesian poisoning method that allows you to add a lot of extra text, sometimes carefully chosen to «trick» the filter.
Another, non-fundamental drawback associated with the implementation is that the method works only with texts. Knowing this limitation, you can put advertising information into pictures, the text in the letter is either missing or does not make any sense. To combat this Bayesian poisoning method we have to use means to detect pictures in texts, or the old filtration techniques, i.e. a «black list» and regular expression (as such letters are often stereotyped in forms).
Method of support vectors
The method of Support Vector Machine (SVM) belongs to the group of boundary classification methods. It determines the belonging of objects to category classes using the boundaries of regions. We will consider only the binary classification of the method. The classification is based on only two categories c and c, taking into account the fact that this approach can be extended to any finite number of categories. Suppose that each classification object is a vector in N-dimensional space. Each coordinate of the vector is a certain feature. The larger the feature is quantitatively, the more this feature is expressed in the object. The advantages of SVM method are:
- it is one of the best quality methods;
- it enables to work with a small set of data for training;
- it gives reducibility to the convex optimization problem having a unique solution.
The disadvantages of the method is its difficult interpretability of the algorithm parameters and the instability with respect to outliers in the source data [1].
Algorithm of k - nearest neighbors
The method of nearest neighbors is a simple metric classifier based on assessing the similarity of objects. The object classified belongs to the class that includes the objects of the training set that are close to it. One of the simple systematization algorithms in real problems often turns out to be ineffective for this reason. In addition to the accuracy of systematization, the question of the classifier is considered to be the rate of systematization: if there are N objects in the training set, M objects in the test set, but the dimension of space is K, then the number of actions to systematize the test set can be estimated as O (K * M * N). When identifying spam, this method does not achieve high accuracy, which makes it quite inefficient when filtering unnecessary information [4].
Advantages of the method are:
- ability to update the training sample without retraining the classifier;
- algorithm stability to abnormal outliers in the source data;
- relatively simple software implementation of the algorithm;
- easy interpretability of the results of the algorithm;
- good training in the case of linearly inseparable samples.
The disadvantages of the method are:
- representativeness of the data set used for the algorithm;
- high dependence of classification results on the chosen metric;
- long duration of work due to the need for a complete enumeration of the training sample;
- impossibility of solving problems of large dimension by the number of classes and documents [6].
Conclusions
In this article, classification algorithms for identifying spam have been analyzed. The shortcomings and advantages of the approaches considered have been identified and studied in detail.
The results of the review can be presented in the following way of research:
- researching poorly studied algorithms;
- developing combined methods.
Bayesian classifier method is of particular interest, since it has a higher reliability and is quite simple to implement. The research prospects are the development of our own algorithm of spam classification based on the naive Bayesian classifier.
References
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. – М.: Либроком, 2009. – 77 с.
- Методы автоматической классификации текстов [электронный ресурс], - Режим доступа:[Ссылка] – Заглавие с экрана.
- Наивный байесовский классификатор [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. – М.: Либроком, 2009. – 88- 89 с.
- Применимость байесовского классификатора для задачи определения спама [электронный ресурс], - Режим доступа: [Ссылка] - Заглавие с экрана.
- Метод ближайших соседей [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Методы автоматической классификации текстов [электронный ресурс], - Режим доступа: [Ссылка] – Заглавие с экрана.
- Доля спама в российском почтовом трафике превышает 60 процентов [электронный ресурс], - Режим доступа: [Ссылка] - Заглавие с экрана.