Аннотация
Бердюкова С.С., Коломойцева И.А. Анализ методов классификации текста. В данной статье приведены основные определения, касающиеся анализа тональности текстов. Описан процесс первичной обработки текста, его индексации и анализа. Рассмотрены группы методов классификации текстов. Описаны некоторые методы обучения классификатора. Сделан вывод о возможности применения методов классификации для определения тональности текста.
Введение
Благодаря современным технологиям пользователи получили возможность делиться информацией друг с другом, в том числе выражать свое мнение насчет всего, что его окружает, будь то книга, фильм, высказывание известного деятеля или жалоба на службу доставки. Объемы текста в Сети с каждой секундой становятся все больше и больше, поэтому обработка их человеком вручную физически невозможна. Так сформировалась потребность в таком направлении, как интеллектуальный анализ текста.
Интеллектуальный анализ текста (с англ. Text Mining) – автоматизация извлечения сведений из текстовых данных. Его особенность (в отличие от анализа других данных) заключается в неформализованности исходной информации: ее не описать простой математической функцией [1].
Различным компаниям и корпорациям для проведения успешных действий важно быстро определять реакцию пользователей, и эта потребность является одной из ключевых для анализа тональности.
Анализ тональности (с англ. Sentiment Analysis) – класс методов анализа содержимого, предназначенный для автоматизированного выявления в текстах эмоционально окрашенной лексики и эмоциональной оценки авторов по отношению к объектам, речь о которых идёт в тексте [2]. Основной целью анализа тональности является нахождение мнений в тексте и выявление их свойств. Какие именно свойства будут исследоваться, зависит уже от поставленной задачи: целью анализа может быть автор, то есть лицо, которому принадлежит мнение.
Задача определения тональности текста является задачей классификации текстов в широком смысле. Классификация документов – одна из задач информационного поиска (раздел машинного обучения), заключающаяся в отнесении документа к одной из нескольких категорий на основании содержания документа [3]. В данном случае классами будут разбитые на подмножества мнения, высказанные пользователями.
Предварительная обработка и индексация документов
Этапы анализа текста показаны на рисунке 1.

Рисунок 1 – Этапы анализа текста
Прежде чем начать работу над определением тональности того или иного документа, его необходимо обработать. Предварительная обработка текста включает в себя приведение всех слов к нижнему регистру, удаление союзов, предлогов и артиклей, разметку по частям речи, токенизацию (выделение минимальных неделимых при анализе единиц текста) и стемматизацию (процесс нахождения основы слова). В результате в качестве признаков будут выступать все значимые слова, встречающиеся в документе [4].
Большинство математических моделей работают в векторных пространствах больших размерностей, поэтому необходимо отобразить текст в векторном пространстве. Основным походом является мешок слов (с англ. bag-of-words): для документа формируется вектор размерности словаря, для каждого слова выделяется своя размерность, для документа записывается признак (насколько часто слово встречается в нем), получаем вектор. Наиболее распространенным методом для вычисления признака является TF-IDF [5] и его вариации (TF – частота слова (с англ. term frequency), IDF – обратная частота документа (с англ. inverse document frequency)). Плюсом мешка слов является простая реализация, но стоит помнить, что данный метод теряет часть информации, (например, порядок слов). Для уменьшения потери информации можно использовать мешок N-грамм (добавлять не только слова, но и словосочетания), или использовать более сложные в плане вычислений методы векторных представлений слов (Word2vec) – это позволит снизить ошибку на словах с одинаковыми написаниями, но разными значениями и наоборот [6].
Методы классификации текста
Существует несколько групп методов классификации текста.
Анализ при помощи методов, основанных на правилах и словарях, заключается в работе с заранее составленными тональными словарями. Процесс составления этих словарей весьма трудоемкий и проблемный, так как одно слово в разных контекстах может обладать различной тональностью (например, слово «сложный» по отношению к системе защиты является положительной характеристикой, но отрицательной – к процедуре регистрации или авторизации пользователя). Для корректного использования в таком случае нужно составить большое количество правил. Существует ряд подходов, позволяющих автоматизировать составление словарей для конкретной предметной области.
В методах, основанных на теоретико-графовых моделях, текст изображается в виде графа на основании предположения, что некоторые слова имеют больший вес, а значит, сильнее влияют на тональность текста. Здесь анализ текста начинается с построения графа и ранжирования его вершин. После ранжирования слова классифицируются в соответствии со словарем, где у каждого проанализированного слова появляется характеристика («отрицательный», «нейтральный», «положительный»). Результат определяется как соотношение количества слов с положительной оценкой к количеству слов с отрицательной оценкой: если полученная оценка близка к 1, то текст нейтральный, больше – положительный, меньше – отрицательный.
Ключевым моментом в методах на основе машинного обучения с учителем является машинный классификатор, алгоритм работы с которым выглядит следующим образом:
- сбор информации (документов), на основе которой будет происходить обучение;
- разложение каждого документа в виде вектора признаков, по которым будет происходить анализ;
- указание правильного типа тональности для каждого документа;
- выбор алгоритма классификации и метода для обучения классификатора;
- использование полученной модели для определения тональности нового набора информации.
В основе машинного обучения без учителя лежит идея, что термины, которые чаще встречаются в этом тексте и в то же время присутствуют в небольшом количестве текстов всего набора текстов (коллекции), имеют наибольший вес. Вывод о тональности текста основывается на выделении таких терминов и определении их тональности.
Рассмотрим подробнее некоторые методы классификации текста.
Наивный Байесовский классификатор
Один из методов машинного обучения с учителем – наивный Байесовский классификатор (с англ. Naive Bayes Classifier) [7], который является частным вариантом байесовского классификатора и основан на применении теоремы Байеса с существенным допущением, что изменение одной величины не влияет на изменение другой величины.
Для данной модели теорема Байеса выглядит так:
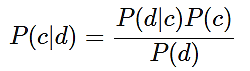 (1)
(1)
где P(c|d) – вероятность, что документ d принадлежит классу c;
P(d|c) – вероятность встретить документ d среди всех документов класса c;
P(c) – безусловная вероятность встретить документ класса c в корпусе документов;
P(d) – безусловная вероятность документа d в корпусе документов.
Знаменатель P(d) в формуле (1) может быть опущен, так как вероятность для одного и того же документа d будет одинаковой.
Для определения наиболее вероятного класса используется оценка апостериорного максимума:
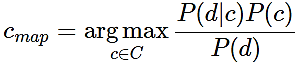 (2)
(2)
Поскольку документ d в модели – это вектор d = {w1, w2, …, wn}, где wi – вес i-ого термина, а n – размер словаря выборки, то условную вероятность P(d|c) можно выразить как P (w1…wn | c) или же P (w1 | c) * (w2 | c) *...* ( wn | c) = Пi P(wi | cj).
Таким образом, для нахождения наиболее вероятного класса c нужно посчитать условные вероятности для каждого возможного класса и выбрать тот, у которого наибольшая вероятность:
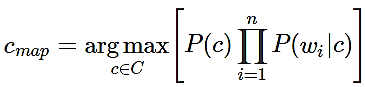 (3)
(3)
Преимущества данного метода:
- высокая скорость работы;
- относительно простая программная реализация алгоритма;
- легкая интерпретируемость результатов работы алгоритма.
Недостатки метода:
- относительно низкое качество классификации;
- неспособность учитывать зависимость результата классификации от сочетания признаков [8].
Метод деревьев решений
Деревом решений называют ациклический граф, по которому производится классификация объектов (в нашем случае документов), описанных набором признаков. Каждый узел дерева содержит условие ветвления по одному из признаков. У каждого узла столько ветвлений, сколько значений имеет выбранный признак. В процессе классификации осуществляются последовательные переходы от одного узла к другому в соответствии со значениями признаков объекта. Классификация считается завершенной, когда достигнут один из листьев (конечных узлов) дерева. Значение этого листа определит класс, которому принадлежит рассматриваемый объект. На практике обычно используют бинарные деревья решений, в которых принятие решения перехода по ребрам осуществляется простой проверкой наличия признака в документе. Если значение признака меньше определенного значения, выбирается одна ветвь, если больше или равно, другая. Пример дерева решений представлен на рисунке 2 [9].
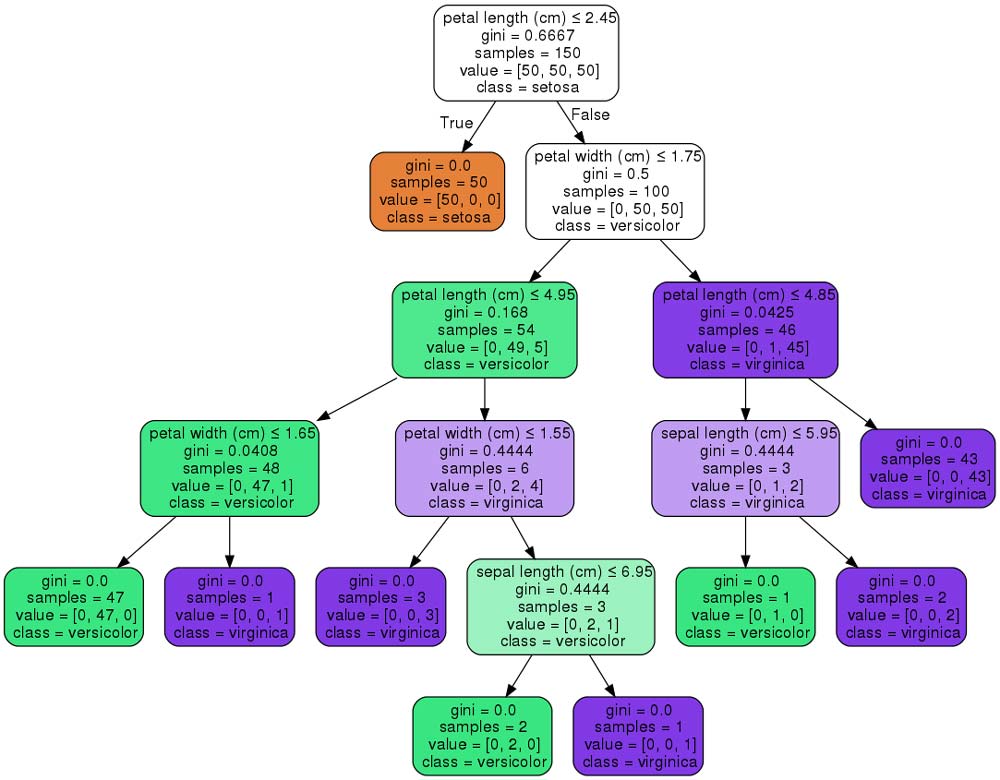
Рисунок 2 – Пример дерева решений
Алгоритм построения дерева решений состоит из следующих шагов:
- создается первый узел дерева, в который входят все документы, представленные всеми имеющимися признаками; размер вектора признаков для каждого документа равен n, так как d = (t1, …, tn);
- для текущего узла дерева выбираются наиболее подходящий признак tk и его наилучшее пограничное значение vk;
- на основе пограничного значения выбранного признака производится разделение обучающей выборки на две части, выбранный признак не включается в описание фрагментов в этих частях;
- образовавшиеся подмножества обрабатываются аналогично до тех пор, пока в каждом из них не останутся документы только одного класса или признаки для различения документов.
Преимущества деревьев решений:
- относительно простая программная реализация алгоритма;
- легкая интерпретируемость результатов работы алгоритма.
Недостатки:
- неустойчивость алгоритма по отношению к выбросам в исходных данных;
- большой объем данных для получения точных результатов.
Метод опорных векторов
Метод принадлежит к семейству линейных классификаторов. В данном походе каждый объект представляется как вектор (точка) в p-мерном пространстве. Каждая из точек принадлежит одному из двух классов. Задача метода – преобразовать пространство при помощи оператора ядра так, чтобы нашлись такие гиперплоскости, которые разделяют примеры из разных классов обучающей выборки. Если такая гиперплоскость существует, она называется оптимальной разделяющей гиперплоскостью, а соответствующий ей линейный классификатор называется оптимально разделяющим классификатором [10]. На практике структура данных бывает неизвестна и очень редко удается построить разделяющую гиперплоскость, а значит, невозможно гарантировать линейную разделимость выборки. Могут существовать такие документы, которые алгоритм отнесет к одному классу, а в действительности они должны относиться к противоположному. Такие данные называются выбросами. Они создают погрешность метода, поэтому было бы лучше их игнорировать [6]. На рисунке 3 показана графическая интерпретация метода.
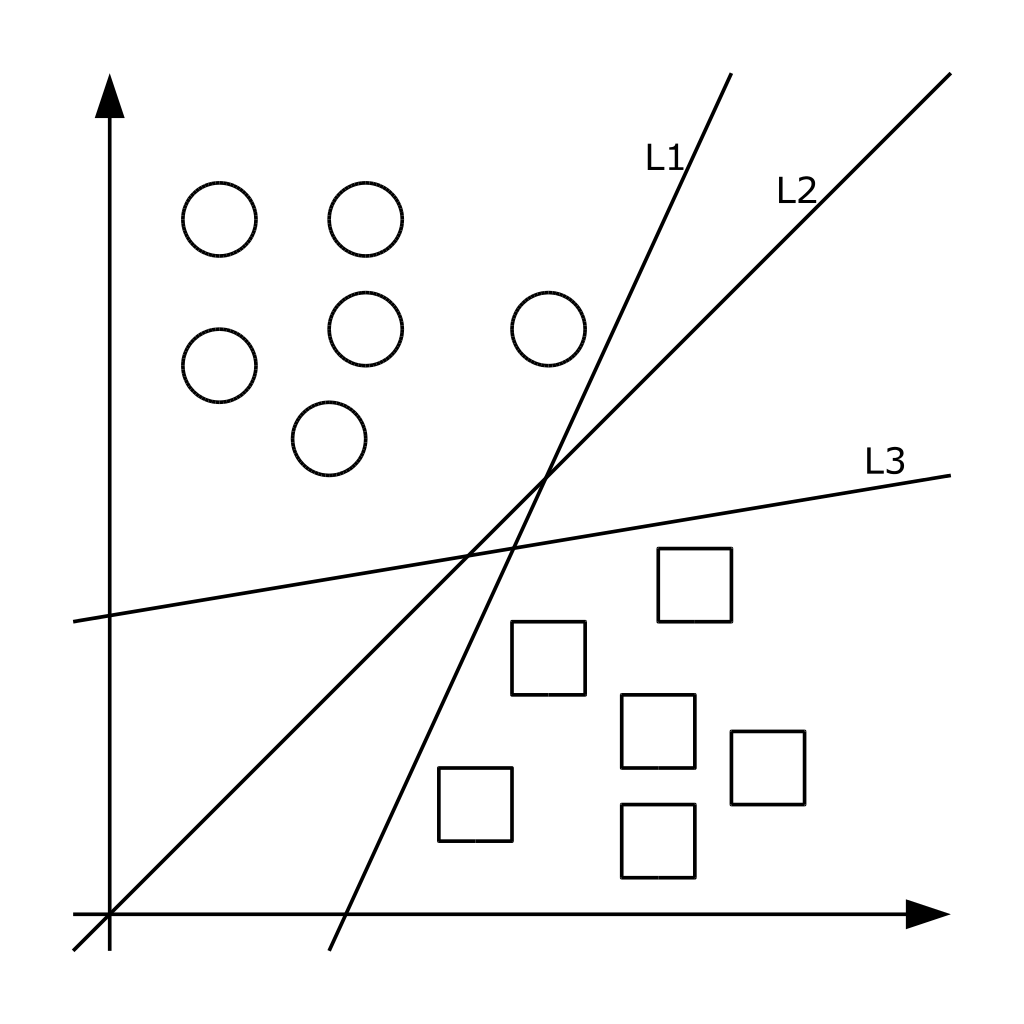
Рисунок 3 – Графическая интерпретация метода опорных векторов
Преимущества метода:
- один из наиболее качественных методов;
- возможность работы с небольшим набором данных для обучения;
- сводимость к задаче выпуклой оптимизации, имеющей единственное решение.
Недостатки метода:
- сложная интерпретируемость параметров алгоритма;
- неустойчивость по отношению к выбросам в исходных данных [6].
Выводы
В статье был рассмотрен алгоритм анализа текста, а также основные методы и алгоритмы классификации текстов. Также были выделены преимущества и недостатки рассмотренных методов.
Предпочтительным для работы можно назвать метод опорных векторов за качественные результаты анализа и возможность обучения небольшого массива данных. Тем не менее, из-за таких преимуществ, как высокая скорость работы и простая интерпретируемость результатов байесовский классификатор не стоит сбрасывать со счетов: им стоит воспользоваться на первых этапах проведения исследования для получения приблизительных оценок и для сравнения результатов опытов на различных массивах документов.
Оба метода классификации планируется в дальнейшем использовать в системе определения тональности в отзывах на новости из сферы культуры для определения отношения общества к произошедшим событиям.
Литература
1. Интеллектуальный анализ текста, или Text Mining [электронный ресурс], – Режим доступа: интеллектуальный-анализ-текста-что-это-и-зачем-он-нужен.aspx. – Заглавие с экрана.
2. Анализ тональности текста [электронный ресурс] – Режим доступа: https://ru.wikipedia.org/wiki/Анализ_тональности_текста – Заглавие с экрана.
3. Классификация документов методом опорных векторов [электронный ресурс], – Режим доступа: https://habr.com/ru/post/130278/. – Заглавие с экрана.
4. Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. – 3-е изд., перераб. и доп. – СПб.: БХВ-Петербург, 2009. – 512 с.
5. TF-IDF [электронный ресурс], – Режим доступа: https://seonomad.net/slovar/tf-idf. – Заглавие с экрана.
6. Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99; DOI: 10.15827/0236-235X.030.1.085-099.
7. Наивный байесовский классификатор [электронный ресурс], – Режим доступа: http://bazhenov.me/blog/2012/06/11/naive-bayes.html. – Заглавие с экрана.
8. Классификация текстов и анализ тональности [электронный ресурс], – Режим доступа: http://neerc.ifmo.ru/wiki/index.php?title=Классификация_текстов_и_анализ_тональности – Заглавие с экрана.
9. Decision Trees – scikit-learn [электронный ресурс], – Режим доступа: https://scikit-learn.org/stable/modules/tree.html. – Заглавие с экрана.
10. Метод опорных векторов [электронный ресурс], – Режим доступа: https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4. – Заглавие с экрана.