Abstract. This article presents the basic definitions concerning the sentiment analysis. The process of primary processing of the text, its indexing and analysis is described. The groups of text classification methods are discussed. Some methods of classifier training are described. It is concluded that it is possible to use classification methods to determine the sentiment.
Keywords: text mining, sentiment, attribute, text evaluation, text processing, classifier.
Thanks to modern technology, users are able to share information with each other, including expressing their opinions on everything around them, whether it's a book, a film, the words of a celebrity or a complaint about a delivery service. The volume of text on the web is increasing every second, so it is physically impossible for human to process it manually. This is how the need for text mining has evolved.
Text mining is the automated extraction of information from alphanumeric data. Its peculiarity is the informalization of source information: it cannot be described by a simple mathematical function [1].
It is important for various companies and corporations to identify user reactions quickly in order to take successful actions, and this need is one of the key ones for sentiment analysis. Sentiment analysis is a class of content analysis techniques designed for automated detection of emotionally coloured vocabulary in texts and emotional evaluation of authors in relation to the objects referred to in the text [1]. The main purpose of sentiment analysis is to find the opinions in a text and identify their properties. Features for investigation depends on the task: the target of the analysis can be the author, i.e. the person to whom the opinion belongs.
The task of determining the tonality of a text is a text classification task in the broad sense. Document classification is one of the tasks of information retrieval (a section of machine learning), which consists of assigning a document to one of several categories based on the content of the document [5]. In this case, the classes will be subsets of opinions expressed by users.
Pre-processing and indexing of documents
The stages of text analysis are shown in Figure 1.

Figure 1 – Stages of text analysis
Before you can start working on determining the sentiment, it needs to be pre-processed. Text preprocessing involves lower-casing all words, removing conjunctions, prepositions and articles, part-of-speech marking, tokenisation and stemmatisation. As a result, all meaningful words occurring in a document will act as features [2].
Most mathematical models work in vector spaces of large dimensions, so it is necessary to map text in vector space. The basic approach is bag-of-words: a vector of dictionary dimensionality is formed for a document, a different dimensionality is allocated for each word, a feature (how often a word occurs in it) is written for the document, we get a vector. The most common method for calculating the attribute is TF-IDF [9] and its variations (TF is term frequency, IDF is inverse document frequency). The advantage of a bag-of-words is simple implementation, but it is worth remembering that the method loses some information (e.g., word order). To reduce information loss, we can add not only words, but also phrases (N-gram bag), or use more complex in terms of calculation methods vector representations of words (Word2vec) - it will reduce the error on words with the same spelling, but different values, and vice versa [3].
Text classification methods
There are several groups of text classification methods.
Analysis with rule-based and dictionary-based methods consists of working with pre-compositioned sentiment dictionaries. The process of compiling these dictionaries is very time-consuming and problematic; because one word in different contexts can have different tonalities (e.g. the word 'complex' is a positive characteristic in relation to the security system, but a negative one in relation to the user registration or authorisation procedure). A large number of rules need to be written in order to be used correctly in such a case. There are a number of approaches to automate the compilation of dictionaries for a specific subject area.
In methods based on graph-theoretic models, a text is represented in a graph, based on the assumption that some words have a higher weight and therefore have a stronger influence on the sentiment. Here, text analysis begins by constructing a graph and ranking its vertices. After ranking, the words are classified according to the vocabulary, where a characteristic ("negative", "neutral", "positive") appears for each word analysed. The result is defined as the ratio of the number of words with a positive score to the number of words with a negative score: if the result is close to 1, the text is neutral, more it is positive, less it is negative.
The key to teacher-based machine learning methods is the machine classifier, whose algorithm is as follows:
- collection of information (documents) on the basis of which the training will take place;
- decomposition of each document into a vector of attributes that will be analysed;
- indicating the correct tone type for each document;
- selection of a classification algorithm and method for training the classifier;
- using the resulting model to determine the sentiment of the new set of information.
Teacherless machine learning is based on the idea that terms that occur more frequently in this text and at the same time can be found in a small number of texts of the whole text set (the collection) have the highest weight. Inference about the sentiment of a text is based on identifying such terms and determining their sentiment.
Let's take a closer look at some of the methods of text classification.
Decision tree method
A decision tree is an acyclic graph used to classify objects (in our case, documents) described by a set of attributes. Each node of the tree contains a branching condition for one of the attributes. Each node has as many branches as the selected attribute has values. In the classification process, successive transitions are made from one node to another according to the feature values of the object. Classification is complete when one of the leaves (end nodes) of the tree is reached. The value of this leaf will determine the class to which the object in question belongs. In practice, binary decision trees are usually used, where the decision to move along the edges is made simply by checking if the feature is found in the document. If the value of the attribute is less than a certain value, one branch is selected, if it is greater or equal, another branch is selected. An example of a decision tree is shown in Figure 2 [8].
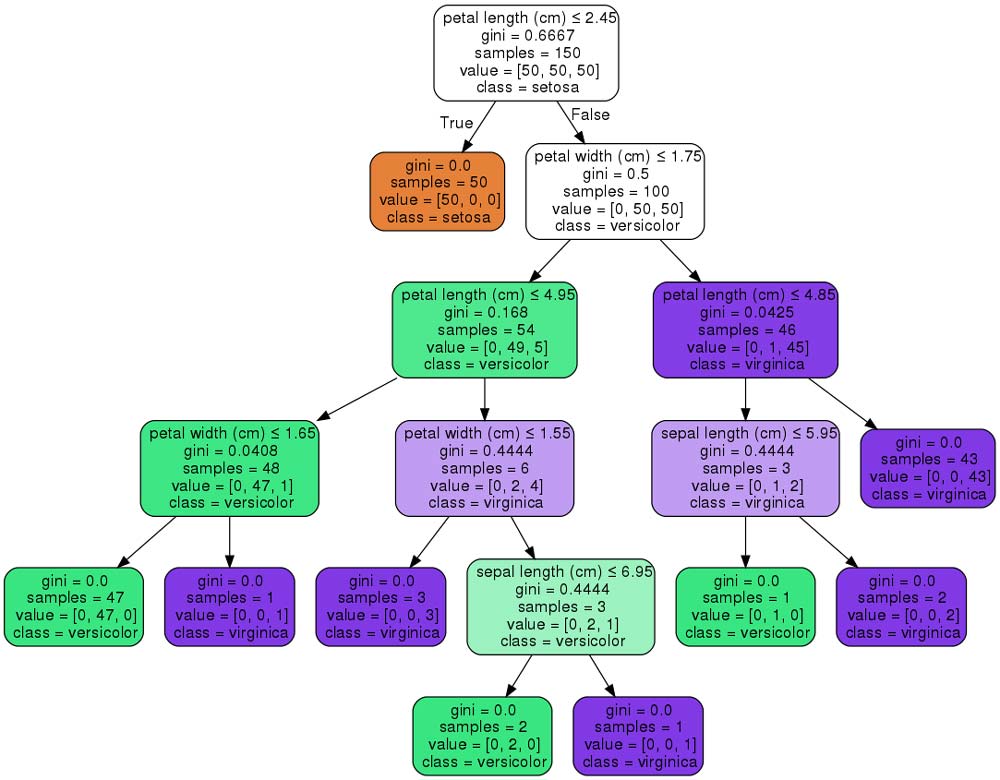
Figure 2 – Example of a decision tree
The decision tree algorithm consists of the following steps:
- the first tree node is created, which includes all documents represented by all available attributes; the size of the attribute vector for each document is n, since d = (t1, ..., tn).
- the most appropriate trait tk and its best boundary value vk are selected for the current tree node;
- Based on the boundary value of the selected attribute, the training sample is divided into two parts; the selected attribute is not included in the description of the fragments in these parts
- The resulting subsets are processed in a similar way until each subset contains only documents of the same class or attributes to distinguish the documents.
Advantages of the method:
- относительно простая программная реализация алгоритма;
- легкая интерпретируемость результатов работы алгоритма.
Disadvantages of the method: :
- instability of the algorithm with respect to outliers in the raw data
- a large amount of data to produce accurate results.
Reference vector method
The support vector machine (SVM) method is a set of algorithms belonging to the family of linear classifiers. In this approach, each object is represented as a vector (point) in p-dimensional space. Each of the points belongs to one of two classes. The task of the method is to transform the space using the kernel operator so that such hyperplanes are found that share examples from different classes of the training sample. If such a hyperplane exists, it is called an optimal separating hyperplane, and the linear classifier corresponding to it is called an optimally separating classifier [7]. In fact, the structure of the data is not known and it is very rare that a dividing hyperplane can be constructed, which means that it is impossible to guarantee the linear separability of the sample. There may be documents that the algorithm assigns to one class, when in fact they should be in the opposite class. Such data are called outliers. They create errors, so it would be better to ignore them [3]. Figure 3 shows a graphical interpretation of the method.
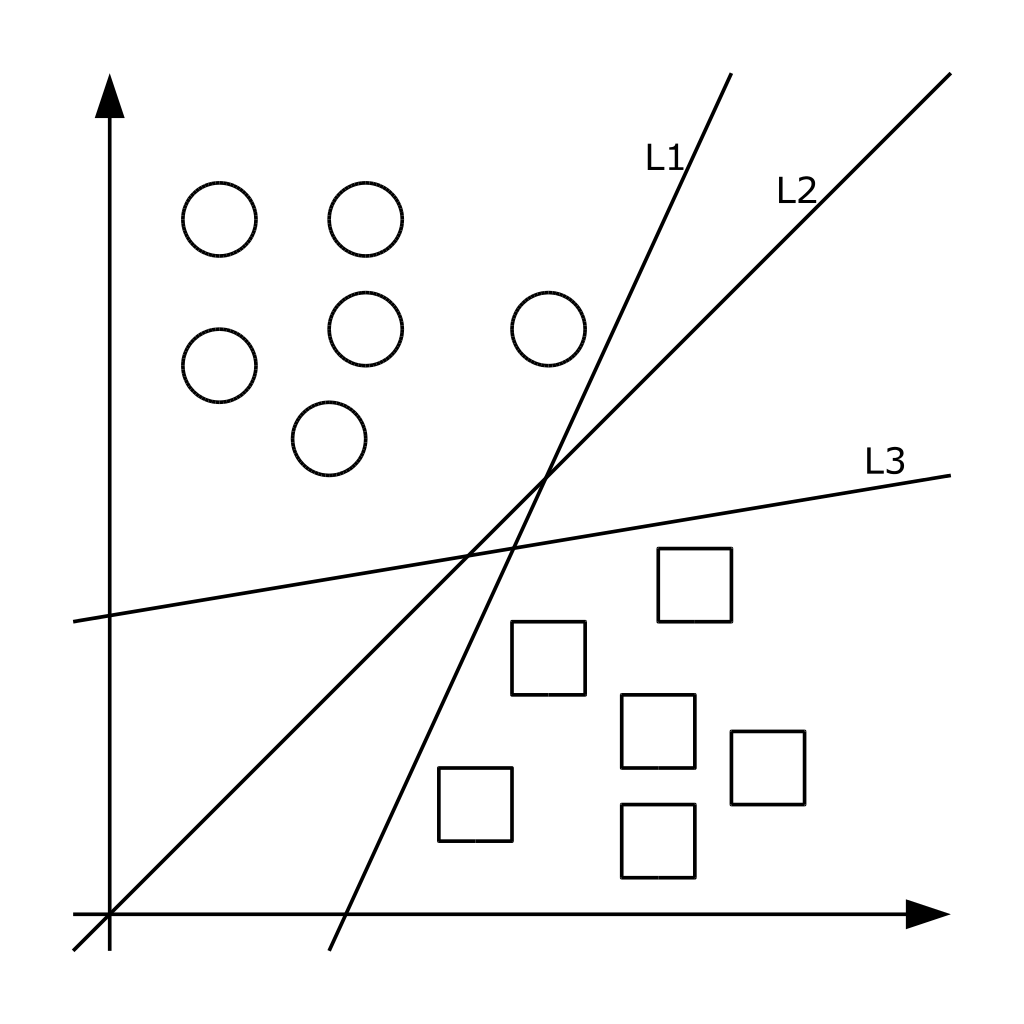
Figure 3 – Graphical interpretation of the reference vector method
Advantages of the method:
- one of the most qualitative methods;
- the ability to work with a small set of data for training purposes;
- reducibility to a convex optimization problem with a single solution.
Disadvantages of the method:
- complex interpretability of algorithm parameters;
- volatility with respect to emissions in the baseline data [3].
Conclusions
The article reviewed the text analysis algorithm, as well as the main methods and algorithms for text classification. The advantages and disadvantages of the considered methods have also been highlighted.
The reference vector method is preferred for its qualitative analysis results and the ability to train a small data set.
Classification methods from this article are planned to be used in the future in a system for determining the sentiment in responses to news from the cultural sphere to determine public attitudes towards the events that have taken place.
References
1. Анализ тональности текста [электронный ресурс] – Режим доступа: https://ru.wikipedia.org/wiki/Анализ_тональности_текста – Заглавие с экрана.
2. Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. — 3-е изд., перераб. и доп. — СПб.: БХВ-Петербург, 2009. — 512 с.
3. Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99; DOI: 10.15827/0236-235X.030.1.085-099.
4. Интеллектуальный анализ текста, или Text Mining [электронный ресурс], - Режим доступа: интеллектуальный-анализ-текста-что-это-и-зачем-он-нужен.aspx. – Заглавие с экрана.
5. Классификация документов методом опорных векторов [электронный ресурс], - Режим доступа: https://habr.com/ru/post/130278/. – Заглавие с экрана.
6. Классификация текстов и анализ тональности [электронный ресурс], - Режим доступа: http://neerc.ifmo.ru/wiki/index.php?title=Классификация_текстов_и_анализ_тональности#.D0.9C.D0.B5.D1.82.D0.BE.D0.B4_.D0.BE.D0.BF.D0.BE.D1.80.D0.BD.D1.8B.D1.85_.D0.B2.D0.B5.D0.BA.D1.82.D0.BE.D1.80.D0.BE.D0.B2 – Заглавие с экрана.
7. Метод опорных векторов [электронный ресурс], - Режим доступа: https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0%BE%D1%80%D0%BD%D1%8B%D1%85_%D0%B2%D0%B5%D0%BA%D1%82%D0%BE%D1%80%D0%BE%D0%B2. - Заглавие с экрана.
8. Decision Trees – scikit-learn [электронный ресурс], - Режим доступа: https://scikit-learn.org/stable/modules/tree.html. – Заглавие с экрана.
9. TF-IDF [электронный ресурс], - Режим доступа: https://seonomad.net/slovar/tf-idf. – Заглавие с экрана.