Аннотация
Смешанный язык очень часто используется в современном многоязычном обществе. Так называется явление смешения синтаксиса и лексики многих языков в одном предложении. Анализ настроения смешанного языка направлен на определение полярности предложения. В данной работе основное внимание уделяется анализу настроений твитов, состоящих из слов на хинди и английском языке, а также других символов. Датасет содержит 20 000 твитов. Мы генерируем представление твитов на уровне слов, символов и подслов, которые используются в качестве входных данных для различных моделей, таких как CNN, LSTM и BiLSTM. Производительность модели BiLSTM выше по сравнению с другими моделями. Точность модели BiLSTM уровня WORD, BiLSTM уровня BPE и BiLSTM уровня CHAR составляет 60,27%, 58,59% и 54,24% соответственно.
1. Введение
Анализ тональности – это отрасль обработки естественного языка. Он имеет множество применений, таких как анализ отзывов о фильмах, моделирование пользователей, курирование онлайн трендов и тональности текста, речь и добыча мнений. В литературе мы встречаем множество названий, выполняющих немного разные задачи, например, анализ тональности, извлечение мнений, добыча мнений, добыча настроений, анализ субъективности, анализ аффектов, анализ эмоций, добыча отзывов и т. д. Однако все они находятся под зонтиком анализа тональности или добычи мнений. Анализ тональности формального текста является хорошо изученной темой (Liu, 2012).
Индия – многоязычная страна, и многоязычные люди, не владеющие английским языком, используют более одного языка для общения друг с другом. Переключение между языками называется переключением кодов или смешением кодов, что зависит от типа смешения. Смешение кодов на уровне слов встречается гораздо чаще, чем на уровне предложений. В северном регионе Индии более распространено сочетание английского языка с хинди (хинглиш). Например:
Waglenikhil U saw caste and religion in them… nation saw talent and trust in them!! Problem is tum paida hi ulte hue the!!
В приведенном выше примере некоторые слова относятся к английскому языку, а некоторые – к языку хинди, однако все они написаны латиницей.
Тексты социальных сетей, такие как блоги, микроблоги (например, Twitter) и чаты (например, WhatsApp и Facebook), открыли множество новых возможностей для доступа к информации и языковых технологий, но в то же время поставили множество новых проблем, что делает их одной из основных областей исследования. Хоть существующие языковые технологии в основном работают для английского языка, когда не носители английского языка используют социальные сети, они сочетают английский с другими языками.
Смешение кодов представляет собой ряд невиданных трудностей для таких задач НЛП, как идентификация языка на уровне слов, тегирование частей речи, разбор зависимостей, машинный перевод и семантическая обработка. Анализ тональности становится еще сложнее в ситуации, когда данные зашумлены и собраны из социальных сетей. Смешанный по коду текст использует синтаксис и лексику нескольких языков. Это становится проблемой для анализа настроений, так как традиционные подходы к семантическому анализу не улавливают смысл предложений. Еще одна проблема – короткие сокращенные данные, присутствующие в предложениях. Одни и те же слова в предложении могут быть написаны в разных формах, что является еще одним ограничением. Для решения этих проблем необходимо выполнить предварительную обработку. В данной работе основное внимание уделяется предварительной обработке твитов и классификации твитов по соответствующим настроениям – позитивному, негативному или нейтральному.
2. Сопутствующие работы
В области анализа тональности было проведено много исследований.
(Deshmukh, 2015) представил различные уровни анализа тональности, т.е. уровень документа, уровень предложения, уровень признаков, уровень слов и уровень фраз. Источник данных для сбора отзывов и подходы для классификации настроений. Большинство работ было выполнено на основе отзывов о товарах, загруженных с Amazon.
(G Remmiya Devi, 2016) представил задачу по извлечению сущностей из кодовых смесей для индийских языков (CMEE-IL). Для извлечения сущностей из смешанных по коду данных используются различные методы. Для извлечения признаков используются триграммы. Оценка этой модели проводится с помощью SVM-light.
(Aditya Joshi, 2016) в архитектуре LSTM (Subword-LSTM) представлено обучение представлений на уровне подслова, а не представлений на уровне символов или слов.
(Nurfadhlina Mohd Sharef, 2016) рассмотрел современное состояние подходов к АТ, включая определение полярности настроения, признаки АТ (явные и неявные), классификацию настроения с помощью машинного обучения и применение АТ. Для выполнения задачи классификации в АТ был использован ряд методов МО.
(Abdul Fatir Ansari, 2017) попытался провести анализ тональности в твитах, используя различные алгоритмы машинного обучения.
(Souvick Ghosh, 2017) представил подход, позволяющий обрабатывать смешанные по коду тексты на трех разных языках – бенгальском, хинди и тамильском – помимо английского. В их системе используется метод обучения последовательностей с использованием условного случайного поля, который полезен для выявления паттернов последовательностей, содержащих переключение кодов, для маркировки каждого слова точной информацией о части речи.
(Braja Gopal Patra, 2018) представил задачу идентификации тональности по наборам данных с кодовым смешением на хинди-английском (HI-EN) и бенгали-английском (BN-EN) языках.
(P.V. Veena, 2018) представил, что смешивание текста является обычным явлением на платформе социальных медиа. Для обработки языка обычно используется классификация текста и идентификация языка. Они использовали две особенности встраивания на основе слов и особенности контекста на основе символов.
(Nurendra Choudhary, 2018) предложил новую методологию под названием Sentiment Analysis of Code-Mixed Text (SACMT) для упорядочивания предложений по соответствующим настроениям – положительным, отрицательным или отрицательным, используя контрастивное обучение. Они используют взаимные параметры сиамских сетей, чтобы очертить предложения кодо-смешанных и стандартных языков в типичное пространство настроений.
(Pruthwik Mishra, 2018) предложил анализ настроений для индийских языков (SAIL). Инструменты Code Mixed нацелены на определение полярности настроений на уровне предложения в наборе данных пар индийских языков (Hi-En, Ben-Hi-En).
(Yash Kumar Lal, 2019) представил смешение кодов, при котором синтаксис и словарный запас нескольких языков смешиваются в одном предложении. Представлена гибридная архитектура для задачи анализа настроений англо-хинди кодо-микшированных данных.
(Иван Провилков, 2019) представил метод BPE-dropout. Метод BPE-dropout – это простой и эффективный метод регуляризации подслова, основанный на традиционном BPE и совместимый с ним. Этот метод превосходит как BPE, так и предыдущие методы регуляризации подслов на широком спектре задач перевода.
3. Детали набора данных
Набор данных содержит 20000 твитов с кодовыми смесями и их тональностями, которые были предоставлены в задании SentiMix Hindi-English Competition, организованном Codalab (веб-платформа с открытым исходным кодом). Учебная база данных состоит из 17000 твитов, а тестовая база данных – из 3000 твитов. Каждый твит из обучающей базы данных начинается со слова meta и содержит уникальный идентификатор и значение полярности/чувства, которое описывает, является ли значение положительным, отрицательным или нейтральным. Каждое слово в твите помечено соответствующим языком, например, Hin для хинди, Eng для английского и O для других символов.
Формат твита в наборе данных представлен следующим образом:
RT Eng
@ O
UAAPconfessions Eng Love Eng
looks Eng good Eng
onEng
!!! O
Ako Eng lang Eng
ba Eng yung Eng
sobrangEng
masaya Hin kasi Hin
may Hin zolo Eng
sya Eng
? O
Before Eng
with Eng
the Eng
past Eng
Z Hin medyo Eng lowkey Eng
s Eng
‰Û_ O
Мы использовали 80% данных из данного набора данных для обучения и 20% для валидации. В таблице 1 показано количество твитов в тренировочных, валидных и тестовых данных.
| Язык | Обучение | Валидация | Тест |
|---|---|---|---|
| Хинди-Английский | 13600 | 3400 | 3000 |
| Данные для обучения | Тестовые данные | |
|---|---|---|
| Всего твитов | 17000 | 3000 |
| Всего слов | 443689 | 78380 |
| Положительная тональность | 5620 | 1023 |
| Отрицательная тональность | 4990 | 974 |
| Нейтральная тональность | 6390 | 1003 |
| Количество английских слов | 147028 | 26454 |
| Количество слов на хинди | 206899 | 36123 |
| Количество слов на других языках | 89762 | 15803 |
| Средняя длина твита | 26 | 26 |
4. Проектирование и реализация
В анализе тональности предварительная обработка данных является важнейшим этапом. Предварительная обработка данных выполняется для устранения противоречивых данных и подготовки данных для выполнения последующих задач. Прежде чем передать набор данных различным моделям для обучения, необходимо выполнить некоторые операции предварительной обработки, чтобы подготовить набор данных для моделей.
5. Модели
В предлагаемой исследовательской работе были реализованы и сравнены различные модели нейронных сетей. Мы реализовали конволюционную нейронную сеть (CNN), длинную краткосрочную память (LSTM) и двунаправленную длинную краткосрочную память (BiLSTM).
Модели конволюционных нейронных сетей применяют свертки на входах для вычисления выходов. В CNN каждый слой применяет различные фильтры к данным, и во время этого процесса модель обучается значениям своих фильтров в зависимости от задачи, которую мы хотим выполнить. В конце этого процесса результаты каждого слоя объединяются. Архитектура модели CNN показана на рисунке 1(a).
Однонаправленная модель LSTM сохраняет информацию о прошлом, поскольку единственные входные данные, которые она видела, были получены из прошлого. Двунаправленная модель LSTM соединяет скрытые слои противоположных направлений с одним выходом, так что выходной слой может получить доступ к информации из прошлого и будущего состояний. Архитектура модели BiLSTM показана на рисунке 1(b).
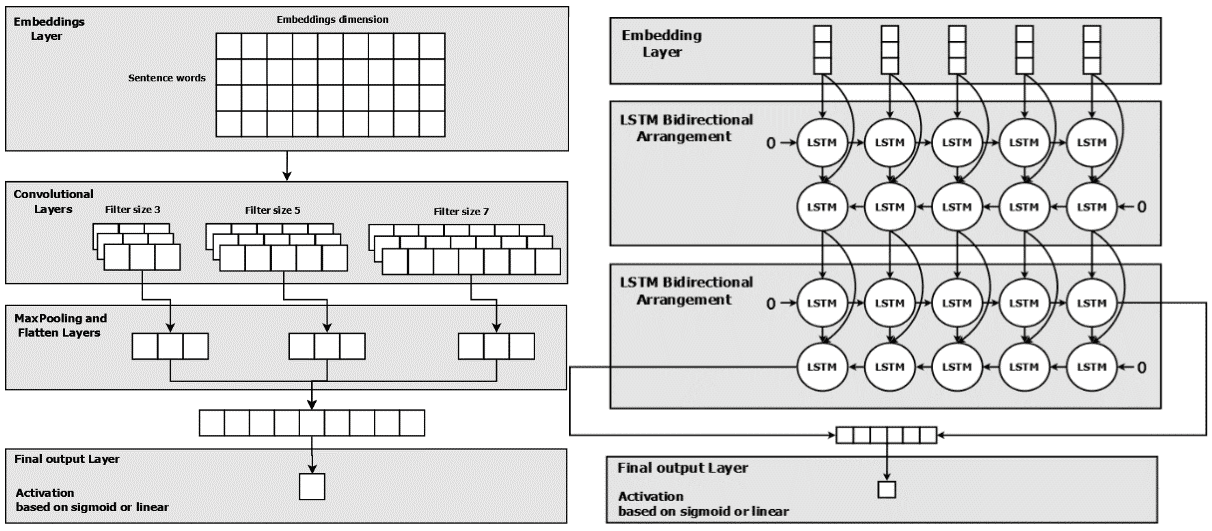
Рисунок 1: (a) Архитектура модели конволюционной нейронной сети, (b) Архитектура модели двунаправленной LSTM.
6.Результаты и обсуждения
Методология оценки имеет компоненты, специфичные для набора данных задачи анализа настроений. В экспериментах выбранная величина, которая должна была быть проанализирована, – это валидационная потеря. Потери при валидации измеряются в каждой эпохе обучения на предварительно определенном валидационном множестве. В нашем случае валидационный набор был определен как последние 20% обучающих данных, и процедура обучения будет остановлена, когда мы наблюдаем по крайней мере две последовательные эпохи без улучшений, общее количество эпох установлено на 25, размер партии в конечном итоге установлен на 512, но также были проведены эксперименты с размером партии 128 и 256 и verbose установлен на 1.
Точность моделей WORD-CHAR Level Bi-LSTM, Byte-Pair Encoding Level Bi-LSTM и WORD Level Bi-LSTM составляет 54.24%, 58.59% и 60.27% соответственно, а F1-score моделей WORD-CHAR Level Bi-LSTM, Byte-Pair Encoding Level Bi-LSTM и WORD Level Bi-LSTM составляет 0.57, 0.63 и 0.64 соответственно.
7. Заключение и сфера применения в будущем
В данной работе различные нейросетевые модели с механизмом внимания обучаются для предсказания тональности смешанных по коду твитов. Обширные эксперименты проводятся на реальном наборе данных твитов социальных сетей с кодовым смешением. Модель WORD-BiLSTM очень хорошо работает с ограниченным набором данных и достигает точности 60,27% и F1 score 0,64.
В будущем можно будет провести множество других экспериментов, основываясь на данной экспериментальной оценке. Одна из возможностей заключается в том, что модели могут быть обучены на большом наборе данных для повышения их точности. Эта задача может быть расширена на некоторые другие типы комментариев на сайтах и приложениях социальных сетей, таких как Facebook, Instagram или Whatsapp и т.д.
Список использованной литературы
[1]. Akshi Kumar, T. M. (2012). Sentiment Analysis: A Perspective on its Past, Present and Future. Intelligent Systems and Applications, 2012, 10, 1-14.
[2]. Aditya Joshi, P. A. (2016). Towards sub-word level compositions for sentiment analysis of hindi-english code mixed text. ArXiv , arXiv:1611.00472.
[3]. Abdul Fatir Ansari, A. S. (2017). Twitter Sentiment Analysis.
[4]. Abney, B. K. (2014). Labeling the Languages of Words in Mixed-Language Documents using Weakly Supervised Methods. Proceedings of the 2013 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics.
[5]. Birdsong, T. (2018, jan 13). 2018 Texting Slang Update: How to Decode What Your Teen is Saying Online. Retrieved from mcafee.com: https://www.mcafee.com/blogs/consumer/family-safety/2018-texting-slang-update-decode-teen-saying-online/
[6]. Braja Gopal Patra, D. D. (n.d.). Sentiment Analysis of Code-Mixed Indian Languages: An Overview of SAIL_Code-Mixed Shared Task @ICON-2017.
[7]. Braja Gopal Patra, D. D. (2018). Sentiment Analysis of Code-Mixed Indian Languages: An Overview of SAIL_Code-Mixed Shared Task @ICON-2017.
[8]. Bandyopadhyay, A. D. (2010). SentiWordNet for Indian Languages. Das2010SentiWordNetFI.
[9]. Fabian Pedregosa, G. V. (2012). Scikit-learn: Machine Learning in Python. CoRR, abs/1201.0490.
[10]. Hongliang Yu, Z.-H. D. (2013, 08). Identifying Sentiment Words Using an Optimization-based Model without Seed Words. ACL 2013, 2, 855-859.
[11]. Ivan Provilkov, D. E. (2019). BPE-Dropout: Simple and Effective Subword Regularization. ArXiv.
[12]. Klenner, M., Tron, S., Amsler, M., & Hollenstein, N. (2014). The Detection and Analy- sis of Bi polar Phrases and Polarity Con icts. Proceedings of 11th International Workshop on Natural Language Processing and Cognitive Science, Venice, Italy, 2014 – 2014. ZORA: Zurich Open Repository and Archive, University of Zurich ZORA.
[13]. Kim, E. (2006). Reasons and Motivations for Code-Mixing and Code-Switching. 4 (EFL).
[14]. Liu, B. (2012). Sentiment Analysis and Opinion Mining. calofornia: Morgan & Claypool Publishers, May 2012.
[15]. Monkeylearn.com. (n.d.). Retrieved from Monkeylearn.com: https://monkeylearn.com/sentiment-analysis-examples/
[16]. Nurendra Choudhary, R. S. (2018, april 3). Sentiment Analysis of Code-Mixed Languages leveraging Resource Rich Languages.
[17]. Nurfadhlina Mohd Sharef, H. M. (2016). Overview and Future Opportunities of Sentiment Analysis Approaches for Big Data. Journal of Computer Science, 12, 153-168.
[18]. P. V. Veena, M. A. (2018). Character Embedding for Language Identification in Hindi-English Code-mixed Social Media Text.
[19]. Pruthwik Mishra, P. D. (2018). Code-Mixed Sentiment Analysis Using Machine Learning and Neural Network Approaches. ArXiv , abs/1808.03299}.
[20]. Piotr Bojanowski, E. G. (2017). Enriching Word Vectors with Subword Information. ArXiv.
[21]. Preslav Nakov, A. R. (2016). Proceedings of the 10th International Workshop on Semantic Evaluation. SemEval-2016 Task 4: Sentiment Analysis in Twitter. San Diego, California}: Association for Computational Linguistics.
[22]. RudolfEremyan. (n.d.). Four Pitfalls of Sentiment Analysis Accuracy. Retrieved from https://www.toptal.com/deep-learning/4-sentiment-analysis-accuracy-traps
[23]. Rico Sennrich, B. H. (2016). Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 1, pp. 1715-1725. Berlin, Germany: Association for Computational Linguistics.
[24]. Supriya B. Moralwar1, S. N. (2015). Different Approaches of Sentiment Analysis. International Journal of Computer Sciences and Engineering, 60-165.
[25]. Svetlana Kiritchenko, X. Z. (2014). Sentiment Analysis of Short Informal Texts. Journal of Artifical Intelligence Research 50(2014) 723-762, 723-762.
[26]. Svetlana Kiritchenko, X. Z. (2014). NRC-Canada: Building the State-of-the-Art in Sentiment Analysis of Tweets. ArXiv , 723-762.
[27]. Souvick Ghosh, S. G. (2017). Complexity Metric for Code-Mixed Social Media Tex. Computación y Sistemas, 21.
[28]. Sartiano, G. A. (2016). UniPI at SemEval-2016 Task 4: Convolutional Neural Networks for Sentiment Classification. Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). San Diego, California: Association for Computational Linguistics.
[29]. Utsab Barman, A. D. (2014). Code Mixing: A Challenge for Language Identification in the Language of Social Media. Proceedings of the First Workshop on Computational Approaches to Code Switching (pp. 13-23). Association for Computational Linguistics.
[30]. Yash Kumar Lal, V. K. (2019). De-Mixing Sentiment from Code-Mixed Text. Proceedings of the ACL 2019, Student Research Workshop (pp. 371-377). Florence, Italy: Association for Computational Linguistics.
[31]. Yogarshi Vyas, S. G. (2014). POS Tagging of English-Hindi Code-Mixed Social Media Content. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 974-979). Doha,Qatar: Association for Computational Linguistics.