
Software Engineeringnamed after L. P. Feldman
Software Engineering
The modern Internet space is changing and forming every day. More and more resources appear media, entertainment, sources of information, content
, and so on. Due to the presence of a huge number of high-quality sources of information in any area of interest of the modern user, a lot of attention is paid by their creators to attract new users and retain the formed audience.
It is nearly impossible to achieve this at the present stage by improving the quality of the main component of the resource only. That is why the formation of a portrait of a particular user's preferences for creating a high-quality recommendation space is becoming an increasingly promising direction.
At this stage of development of Internet technologies and computer data analysis technologies, the success of an Internet resource is mostly determined by the presence of a high-quality system of recommendations. The main purpose of recommendation systems is to inform the user that a particular product, service, or information may be of interest to him at a given time and given circumstances. The work of such systems is based on the analysis of information about the user's profile, the portrait of his actions during a visit to the resource, as well as a regularly updated set of statistical data about all users of the resource.
Depending on the business model, recommendations can be its basis, or they can simply be an additional service designed to improve the user experience. Personalization of online marketing is an obvious trend of the last decade. It is estimated that about 35% of Amazon's revenue or 75% of Netflix comes from recommended products, and this percentage is likely to grow [10]. Recommendation systems bring obvious benefits to owners of online stores, various services, and applications. They show the user exactly what he is interested in and generate profit [12]. Based on the above indicators, the relevance of studying this topic cannot be disputed. An analytical and systematic approach to this issue can help not only business but can also bring many useful discoveries to computer science.
A recommendation system is a complex of algorithms, programs, and services whose task is to predict what a user might be interested in [1].
Modern recommendation systems often require rather complexly organized data processing and storage systems, are not lightweight
, and compensate for their complexity with the accuracy of recommendations and the speed of information processing. However, it's not a secret that every day the number of all requests to the world wide Web from mobile devices is growing, which suggests that an urgent problem is the creation of mobile
recommendation systems that will not be inferior to modern ones in accuracy and speed. Mobile recommendation systems are a particularly difficult area of research since mobile data is more complex than the data that recommendation systems often have to deal with [2].
A recommendation system is a subclass of an information filtering system that seeks to predict the rating
or preference
that a user would give to an element [2]. Recommendations are formed separately for each person, based on their previous actions on a specific resource or based on past activity. In addition, the behavior of previous participants in the process also matters.
Recommendation services collect various information about a person using several methods, according to which all systems share [8].
The first method is explicit data collection. The user provides the materials necessary for the operation of the system. For example, when recommendation systems ask a person to evaluate different elements, make a list of favorites in a certain field, or answer a list of questions. Explicit data collection also includes filling out a profile, as well as selecting so-called tags
from the provided list. If a person refuses to provide data, the second method is relevant.
The second method is implicit data collection. This is a system that provides for tracking the actions of a process participant by a program for further processing and application. The system recognizes purchases, ratings on websites, collects information on views, comments. Of course, the use of such a technique leads to some ethical problems, because the protection of personal data is one of the main requirements imposed by the user to a modern Internet resource.
After receiving information about the user in one way or another, the recommendation system turns to methods for analyzing this data. The list of necessary information also depends on the method of analysis: data about a specific visitor
, about the audience of users in general, about the evaluative judgments of the audience, etc. The most common approaches to analysis in recommendation systems are:
Collaborative filtering is one of the methods of making predictions (recommendations) in recommendation systems that use known preferences (estimates) of a group of users to predict unknown preferences of another user [3].
The idea of this approach is that users who have evaluated some objects in the same way in the past are most likely to give similar ratings to some objects in the future. In this approach, there is a knowledge accumulation scheme: the more the user views and gives ratings, the more accurate and personalized recommendations he receives. Recommendations using this technique are issued based on the behavioral characteristics of one person or group of people, the latter is even more effective [7]. A schematic representation of collaborative filtering is shown in Figure 1.

Figure 1 – Representation of collaborative filtering
Collaborative filtering is divided into 3 types: neighborhood-based, model-based, and hybrid.
The neighborhood-based type is used in most recommendation systems. In this case, a group of users with similar interests is selected for the visitor
, and based on combinations of weights and ratings, content is selected that is more likely to interest a person.
The type of collaborative filtering based on the model provides recommendations based on the parameters of statistical models for user evaluations constructed using the Bayesian network method, clustering, latent semantic model, etc. [4]. This approach is gaining popularity due to more accurate predictions because it takes into account some hidden factors that explain the observed estimates. The hybrid type is more common than the others, especially if the recommendation system is being developed for a commercial site: an online store, marketplace, etc. It combines the first two types and helps to overcome the limitations of the original approach and improve the accuracy of recommendations [5].
Given the peculiarities of the collaborative filtering method, which requires the availability of estimated data from users, it may not always be used. The first use case is to create a recommendation regarding interesting and popular information based on taking into account the votes
of the community [4]. Another use case is the creation of personalized recommendations for the user, based on his previous activity and data on the preferences of other similar users. This method of implementation can be found, for example, on sites such as YouTube, Last.fm, and Amazon.
The essence of this approach is that we match users with the content or products that they liked or were bought by them [6]. Attributes of users and resources (products) play an important role in this approach. Content filtering builds internal links between the offered products or any content [9]. A schematic representation of content-oriented filtering is shown in Figure 2.
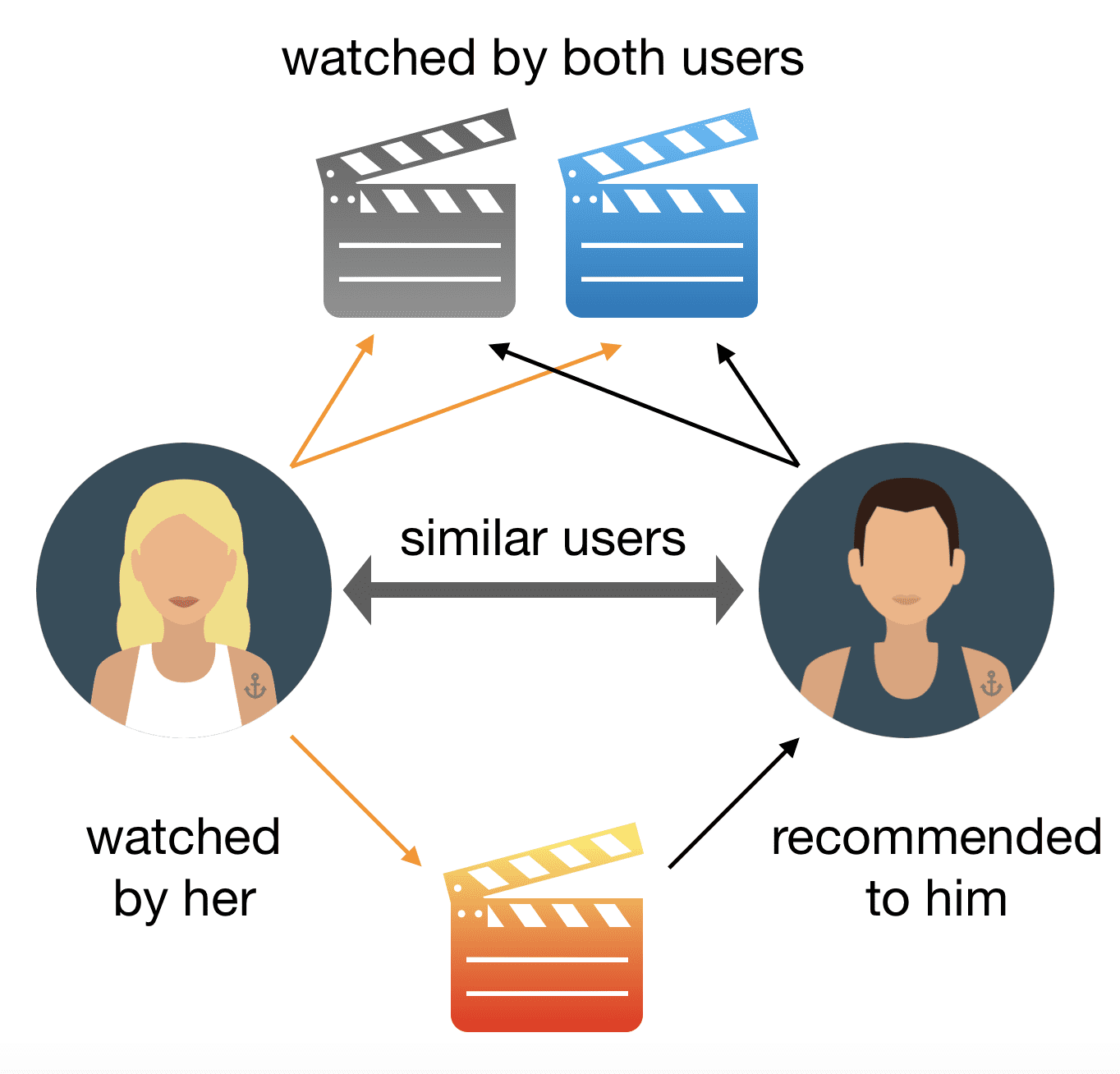
Figure 2 – Content-oriented filtering
In contrast to the collaborative filtering method, which relies only on the interaction of user elements, content-based approaches use additional information about users and/or elements [7]. The idea of content-based methods is to try to build a model based on the available functions
that explain the observed user interactions with the element. Often, to generate recommendations, the system refers to the user's profile, where information about his interests and preferences is stored in a certain format in the form of keywords.
Content-based methods, unlike collaborative ones, suffer much less from the problem of cold start
(cold start
– the absence of any statistical data from the system about users at the very start). This happens because new users or elements (products, resources, etc.) can be described by their characteristics (content), and therefore appropriate proposals can be made for these new elements.
The advantage of content filtering is that it does not require a large number of registered users to start the recommendation system, since the assumptions do not depend on other users of the system. The main disadvantage of this approach is the inability of the system to recommend new objects that are not tied to the interests of users.
Since each of the approaches above has its own set of advantages and disadvantages, hybrid methods are used to combine the advantages of different approaches to create a system that works well in a wide range of applications. Modern systems use various advanced algorithms to solve existing problems. For example, to solve the sparsity problem, the majority uses approaches, clustering, and normalization methods. The method of analyzing demographic and associative rules is used to solve the problem of cold start, and they are quite effective. K-nearest neighbors (KNN) and the Tree of Frequent Patterns (FP) are combined to obtain high-quality proposals that overcome the shortcomings of existing approaches.
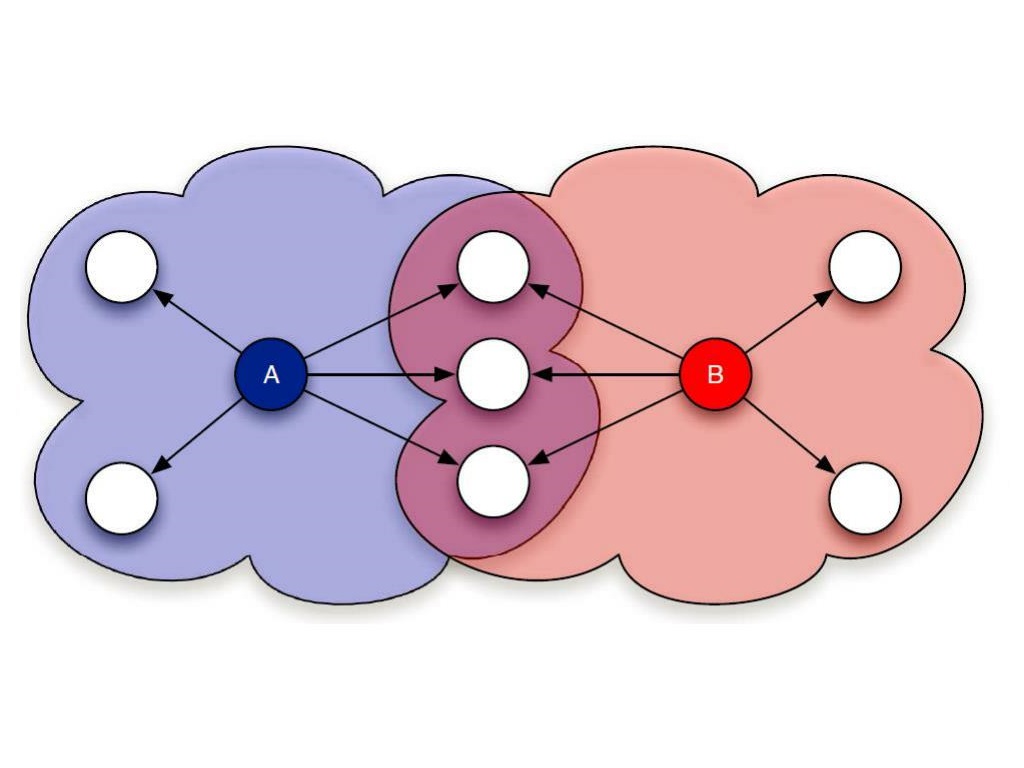
Figure 3 – Nearest Neighbor method
Hybrid deep models are considered to be one of the most powerful tools for solving recommendation tasks [11]. The only problem with traditional hybrid systems is that they use past user information for recommendations. Let's say a user who has been using an application based on a hybrid system for a long time suddenly stops using it. After a few days, when he visits the website or application again, the system will recommend products based on the interest shown earlier, but they may no longer be relevant now.
There are many ways of hybridization. Among them:
In the course of the research, existing algorithms for building recommendation systems and data analysis will be analyzed, a method for improving them and applying them to a real task will be chosen.
A well-organized collection of information about the user and the correct choice of the method of analyzing this information makes it possible to significantly increase the efficiency of using the resource, increases the likelihood of performing related targeted actions and, in the case of a commercial orientation of the resource, significantly increases its profitability. More and more major providers of information, content, goods, and services are resorting to the use of recommendation systems to increase user convenience and attract a new audience [13].
The development of the field of recommendation systems is ongoing since the exponential expansion of the Internet makes it difficult to obtain the necessary information in a fairly short time. The future of recommendation systems will be much broader than simple business use, they will have a much greater impact on our daily lives. The ideal recommendation system would know us better than we do ourselves and makes the decisions needed at every stage of our lives effortlessly and quickly so that we can spend our precious time on more productive activities. Several approaches and methods have already been used, as discussed in the article, but they have their problems, such as the cold start problem. The problem is related to new users who do not yet have a history of visited pages. Thus, it is assumed that the system will provide recommendations to the user without relying on any previous actions. Recommendation systems assume the use of the entire user profile, your likes, and dislikes. This may endanger the user's privacy. Providing accurate recommendations based on a large amount of data may lead to some delay in response time. In addition, in any recommendation system, predicting user interest can be a difficult task, since interest can change over time. To solve these problems, the researchers propose some modifications, such as combining K-nearest neighbors (KNN) and a tree of frequent patterns (FP) to provide high-quality recommendations to users or a hybrid sentiment-based system that works by applying sentiment analysis to a list of recommendations generated to improve the accuracy and performance of existing systems.