
Abstract
When writing this abstract, the master's work has not yet been completed. Final completion: June 2022. The full text of the work and materials on the topic can be obtained from the author or his supervisor after the specified date.
Contents
- Introduction
- 1. The problem of ensuring information security for client-server applications with a database
- 2. Analysis of information security threat risks for client-server applications with a database
- 3. Identifying threat sources and building a threat model for a client-server application with a database
- 4. Research and development overview
- 5. Designing software tools and algorithms for protecting a client-server application with databases based on the threat model
- Conclusion
- References
Introduction
When designing client-server applications with databases for various purposes for storing large and ultra-large amounts of information, designers usually they make a choice in favor of a relational DBMS. At the next stages of design and development, database security is usually reduced to allocating user classes, their information needs and privileges (a security policy is being formed), design of an access control system.
Further, the SQL language is used to assign / revoke privileges, including Grant, REVOKE, etc. statements. most modern relational DBMSs support discretionary (DAC) and mandate (MAC) access control models, as well as additional security tools.
at all stages of the lifecycle of a client-server application with a database built on the basis of a relational DBMS, a large number of threats of different classes can be implemented. These capabilities are derived both from the properties of the relational data model itself, so it is with the features of the DBMS implementation by different manufacturers and the access differentiation model used. Information protection in relational databases has its own specifics, it consists in the fact that the semantics of the processed data provides greater opportunities for implementing various threats against the database than, for example, to the file system.
A threat is usually understood as a potentially possible Event, Action (Impact), process or phenomenon that can lead to harm to someone's interests.
1. The problem of ensuring information security for client-server applications with a database
When designing client-server applications with databases for various purposes for storing large and ultra-large designers usually opt for a relational DBMS for information volumes. At the next stages of design and development database security is usually reduced to allocating user classes, their information needs, and privileges (a security policy is being formed), designing an access control system, as well as selecting algorithms and software security tools.
At all stages of the lifecycle of a client-server application with a database built on the basis of a relational DBMS, a large number of threats of different classes can be implemented. These capabilities are derived both from the properties of the relational data model itself, so it is with the features of the DBMS implementation by different manufacturers and the access differentiation model used. Information protection in the relational databases have a specific feature, which consists in the fact that the semantics of the processed data provides great opportunities for implementations of different threats to the database than, for example, to the file system.
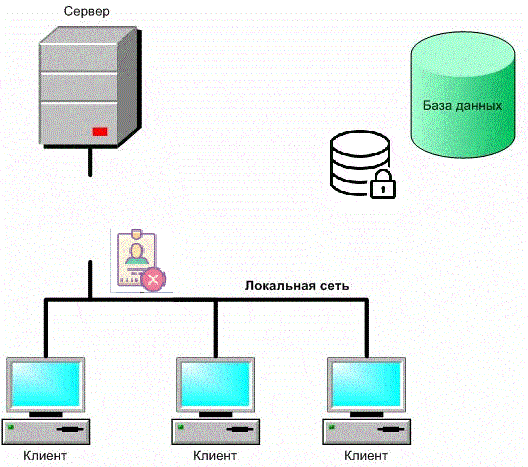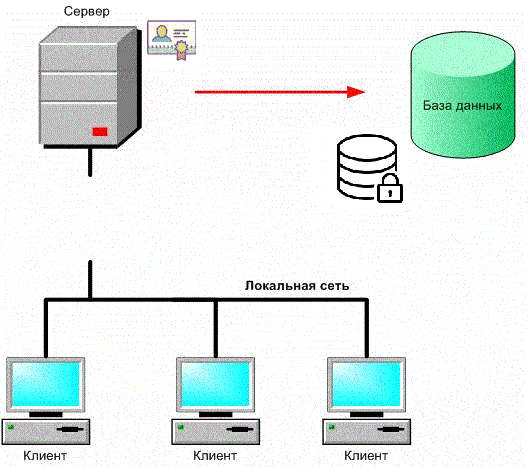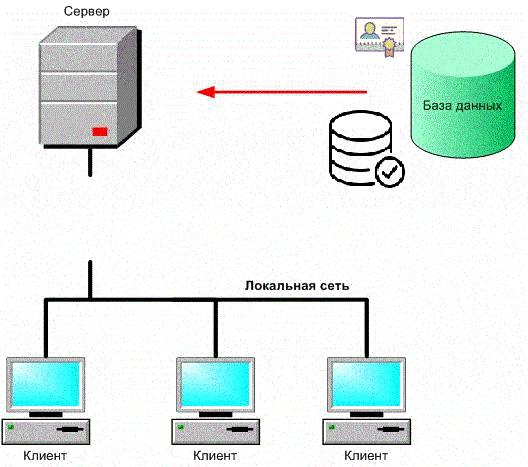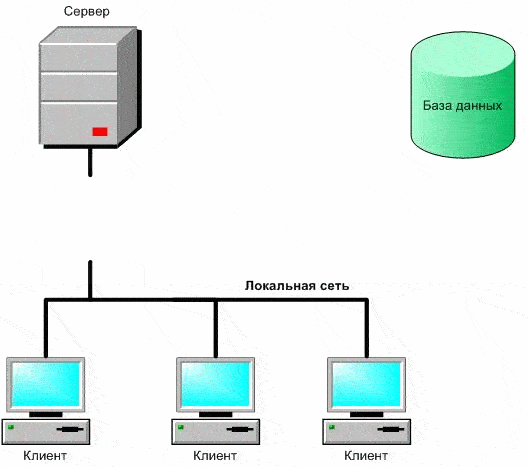
Figure 1 – Security of a client-server application with a database (animation: 9 frames, 6 cycles, 198 kb)
The threat to the information security of a client-server application with a database is the possibility of influencing information, processed in the application, which leads to distortion, destruction, copying, blocking access to information, as well as the ability to influence on the components of the information system, leading to the loss, destruction or failure of the functioning of the information carrier or tools for managing the system's software and hardware complex.
The threat of data privacy breach includes any intentional or accidental disclosure of information, stored in a computer system or transferred from one system to another. Privacy violations lead to both a deliberate action aimed at implementing unauthorized access to data, and an accidental error a program or unskilled action of the operator, which may lead to the transmission of unprotected confidential information over open communication channels.
The threat of integrity breach includes any intentional or accidental modification of the information processed in the information system or entered from the primary data source. A violation of data integrity can be caused by a deliberate destructive action of a certain person, changes to the data to achieve its own goals, as well as an accidental software or hardware error that led to irrevocable data destruction.
To build a threat model for client-server applications with databases, it is necessary to identify them. It is necessary not only to carry out work on identifying and analyzing the threats themselves, but also to study and describe the sources of occurrence of the identified threats. This approach will help you choose a set of security tools. For example, illegal login may result from recreating the original dialog, selecting a password or connecting unauthorized equipment to the network. Obviously, each of these methods of illegal entry requires its own security mechanisms [1].
2. Information security threat risk analysis for client-server applications with a database
Client-server applications with databases are subject to a large number of risks that threaten the information security of the software system.
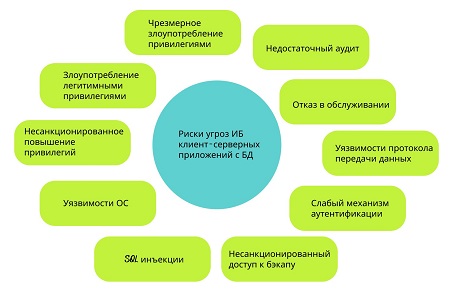
Figure 2 – Security risks for client-server applications with databases
Let's consider and analyze the main ones:
- excessive abuse of privileges-users are granted access rights that allow them to perform other tasks, malicious intent can be detected by such tasks, which leads to abuse of such privileges. When we talk about such abuse, we can give an example of a university automated control system, where the administrator has access to all databases and has the right to change the records of any student. This can lead to misuse, such as changing students ' grades. The source of the vulnerability is for all users who perform various tasks, a default privilege level is provided that grants access in excess of the norm;
- abuse of legitimate privileges may take the form of misuse of the database by users, administrators or system administrators who perform any illegal or unethical actions. This is, among other things, any misuse of confidential data or unjustified use of privileges. The source of vulnerability is the human factor;
- unauthorized privilege increase-attackers can change privileges, for example, grant access to an ordinary user with administrator rights. This may lead to forgery of accounts, transfer of funds, or misinterpretation of certain confidential analytical information. Such cases also occur in database functions, protocols, and even SQL statements. Source of vulnerability-excessive exposure leads to the identification of flaws in the pharmaceutical system ,which can be used by attackers;
- vulnerabilities of platforms where a client-server application with a database is deployed operating system vulnerabilities can cause data leaks from the database, data corruption, or denial-of-service conditions. For example, a blaster worm created denial-of-service conditions due to a vulnerability found in Windows 2008. the source of the vulnerability is system errors, viruses, malfunctions, and holes in operating systems;
- SQL injections-random SQL queries executed on the server by an attacker. In this attack, the SQL statement is followed by a string ID as input. This is confirmed by the server. If it is not checked, it can be executed. With these unobstructed rights, attackers can gain access to the entire database. Source of the vulnerability-not fully processed SQL queries:
- insufficient audit log-the database audit policy ensures automatic, timely and correct recording of database transactions. This policy should be part of database security considerations, since all confidential database transactions have an automatic record, the absence of which poses a serious risk to the organization's databases and can cause instability in operation. Source of vulnerability-the database transaction record is not configured or configured incorrectly;
- denial of Service-an attack that prevents legitimate users of an application/application/data from using or accessing that particular service. DoS can occur using a different technique. An attacker can gain access to the database and try to cause a server crash or resource overload. This is a serious threat to any organization. The source of the vulnerability is network overflow and data corruption.
- database data exchange protocol-vulnerabilities in database communication protocols lead to unauthorized actions that control this susceptibility, they can range from illegal data access to data exploitation and denial of Service. The source of the vulnerability is a large number of weaknesses in the database communication protocols of all vendors;
- weak authentication mechanism-makes databases more vulnerable to attackers database user identification data can be stolen or through any source that then helps in changing data or obtaining confidential information, login credentials can be obtained. Source of vulnerability-authentication is not implemented properly and is weak.
- unauthorized access to backup data is an important threat that needs to be taken care of, since backups on any external media are at high risk. The source of the vulnerability is insufficient or complete lack of protection against attacks such as theft or destruction of a backup [2].
3. Identifying threat sources and building a threat model for a client-server application with databases
The development of an information security system should be based on a certain list of potential security threats and the identification of possible sources of their occurrence. Designing a specific security system for any object, including database systems, involves identifying and scientifically classifying the list of sources of security threats.
We will formulate a list of external and internal threats to the information security of databases.
External destabilizing factors that pose security threats to the functioning of client-server applications with databases and DBMS are:
- deliberate, destructive actions of persons with the aim of distorting, destroying or stealing programs, data and documents of the system, the cause of which is a violation of the information security of the protected object;
- distortions in the transmission channels of information coming from external sources circulating in the system and transmitted to consumers, as well as unacceptable values and changes in the characteristics of information flows from the external environment and within the system;
- failures and failures in computing equipment;
- viruses and other destructive software elements distributed using telecommunications systems that provide communication with the external environment or internal communications of a distributed database system;
- changes in the composition and configuration of the complex of interacting system equipment beyond the limits tested during testing or certification of the system.
Internal sources of threats to client-server applications with databases and DBMS are:
- system errors in setting goals and objectives for designing client-server applications with databases and their components, made when formulating requirements for the functions and characteristics of system security tools;
- design errors in the development and implementation of algorithms for ensuring the security of hardware, software and databases;
- errors in determining the conditions and parameters of the functioning of the external environment in which the client-server application with the database should be used, in particular, software and hardware data protection tools;
- errors and unauthorized actions of users, administrative and maintenance personnel during the operation of the program;
- insufficient effectiveness of the methods and tools used to ensure information security in standard or special operating conditions of the program.
Complete elimination of all potential threats to the information security of client-server applications with databases is fundamentally impossible. The real challenge is to reduce the likelihood of potential threats being implemented to a level acceptable to a particular system. The acceptability of the appropriate level of threats may be determined by the scope of application, the allocated budget, or the provisions of current legislation. Cumulative risk is a rather complex function of the vulnerability of application components. Various negative influences also have a rather complex effect on the main ones quality and security characteristics of client-server applications with databases [3].
4. Research and Development Review
4.1 Overview of international sources
There are many sources devoted to the problem of ensuring the security of client-server applications with databases. For example, the article Database Security and Encryption: a Survey study
examines database security, analyzes problems, requirements, and threats to database security, and discusses the use of encryption protection tools at various levels of database security.
A the article database SECURITY: THREATS and PREVENTIVE MEASURES
analyzes many different threats and vulnerabilities and identifies the most common and problematic ones, and also suggests the most appropriate preventive measures or solutions for each of the analyzed threats and vulnerabilities.
In the book database Reliability Engineering: Designing and Operating Resilient Database Systems
by Laine Campbell and Charity Majors, attention is paid to the requirements for the level of maintenance and risk management of databases, the creation and development of architecture to ensure the hope of database operation, infrastructure development and infrastructure management, secure storage, indexing and replication of data,
defining data warehouse characteristics and best use cases, designing data warehouse architecture components, and data-driven architectures.
4.2 Overview of national sources
Among national sources, many publications are also devoted to ensuring the security of client-server applications with databases. In the Database book.
Design, programming, management and administration-2020
Vovka V. the main concepts and problems of databases are discussed,
the processes of their design, programming and management, as well as technologies of their administration in order to achieve high performance of data access, are considered
and ensuring the necessary level of Information Security.
Book PostgreSQL 11. Schoenig Hans-Jurgen's Mastery of Development 2019 highlights advanced technical aspects of PostgreSQL, including logical replication, database clusters, performance optimization, monitoring and user management. It examines transactions, locks, indexes, and query optimization. In addition, the provision of network security and the mechanism of backups and replications, useful PostgreSQL extensions that allow you to increase performance when working with large databases are considered.
In the book Fundamentals of Database Technologies 2020
Novikova B., Gorshkova E. and Grafeeva N. the basic concepts, the structure and principles of the DBMS, ensuring the safety of work, as well as the technologies (architecture, algorithms, data structures) underlying them are considered in detail.
4.3 Overview of local sources
In the work Optimizations for highly loaded relational databases and alternative solutions
K.K. Babich reviewed the technologies used to optimize relational databases and described the possible implementation of a highly loaded database application.
In the work Performance models of database management systems
Selmi Uayik examines the performance of a database management system by comparing database servers.
5. Designing software tools and algorithms for protecting a client-server application with databases based on the threat model
5.1 Password hiding algorithm
To reduce the risk of unauthorized access to the database by reading passwords, it is planned to use the following password hiding algorithm.
Using the concealment algorithm, it is necessary to ensure the use of a password of unlimited length and any characters that the user likes, secure and efficient password storage in the database, prevention of any attacks using SQL injections, prevention of attacks related to data movement.
If the password is lost or compromised, a reset
should occur, which means that you do not need to store the password in plain text for authentication. One way to solve these problems is to use a one-way hash, that is, encryption that cannot be decrypted. Hashing algorithms are known, such as MD5 hash, SHA-1. These algorithms are good because regardless of the size of the data, the size of the returned data is always the same. MD5 has a length of 128 bits, which is 16 bytes. One hashing algorithm is not enough, as it is easy to crack.
To reduce the risk of hacking, it is necessary to use the most reliable hash algorithm available in our code base. And salt
our passwords, that is, create a random value to add to the end of the password to make it more unique. This is also necessary to prevent password analysis, if only the hashing algorithm is used, all the same passwords will have the same hash. When using a random salt value, the stored hashes become unique, even if the same password is used. Also, during authorization, not the values of variables themselves will be inserted into the request, but their parameters, to prevent SQL injections [4].
From the above, the following registration/authorization algorithm can be formed.
- User Registration:
- entering the user name;
- entering a password;
- creating a random salt to the password;
- application of the hash algorithm;
- saving the user name, hash and salt in the database table.
- User authorization:
- timeout of 2 seconds, to slow down attacks using brute force;
- getting a username and password;
- getting the corresponding record from the database;
- using salt from the database to create a hash to the password;
- comparison of the received hash with the password hash stored in the database;
- refund
Failed to log in
orSuccessful authorization
; (we do not show more detailed messagesuser not found
orincorrect password
, because this gives the intruder a lot of information).
5.2 Algorithm of access rights differentiation
To reduce the risk of unauthorized access to information for which the user has insufficient privileges, it is planned to use an algorithm for delimiting user access rights. This algorithm includes creating roles on the server side of a client-server application with a database, making user entries in a specific role, assigning each role its own set of privileges and access rights to view/edit/creating a table, and processing these roles and privileges on the client side of the application.
Also, for a more secure level of information security, it was decided to access all tables not directly, but only through their representation on the server side. A view is a named dynamically supported server selection from one or more tables. This is a virtual table where records are generated when a user accesses it according to a previously assigned query. With the help of views, access is formed not to the whole table, but to certain records necessary for the user to work.
To do this, you need to create a view for each data table and assign privileges to each view for all available roles.
Next, it is necessary to process the existing roles and privileges in the server part when authorizing the user on the client part of the application.
From the above, the following access rights differentiation algorithm can be formed:
- making a request to the server with the username parameter during authorization.
- getting roles and privileges from the server corresponding to the given user name.
- formation of data corresponding to the privileges of this user into a representation.
- display on the client side of the generated view.
5.3 Algorithm of depersonalization of personal data
To reduce the risk of unauthorized access to personal data or leakage of such data, it is planned to use the algorithm of depersonalization of personal data (Fig. 3).
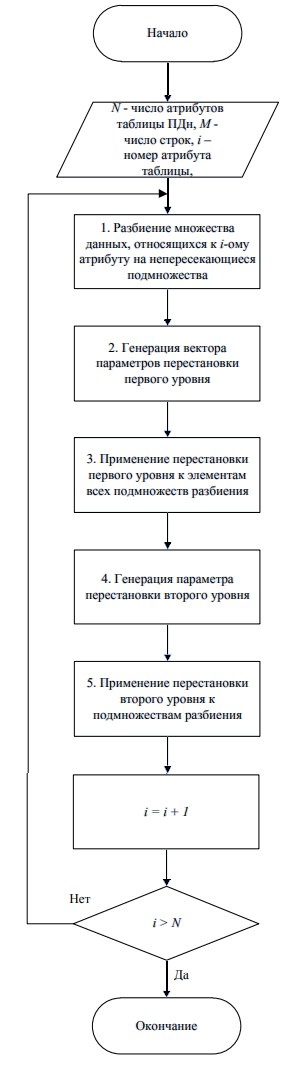
Figure 3 – Flowchart of the personal data depersonalization algorithm
The proposed algorithm for depersonalization of personal data is based on the following principles:
- splitting the original data set into subsets, which reduces the dimension and simplifies its practical implementation;
- using cyclic permutations that implements data shuffling.
The algorithm provides a step-by-step permutation of data from each set of attributes of the original table. The principle of cyclic permutations is used at each step [5].
Splitting each set must have the following properties:
- partitioning subsets include all elements of a data set of the same attribute;
- all elements in subsets are ordered by both internal numbers (element numbers inside the subset) and external numbering of the subsets themselves in the split;
- the total number of elements of all subsets of the data set of one attribute is equal to the total number of elements of this set.
The quality criterion for depersonalization of personal data is the probability of obtaining personal data based on the leakage of depersonalized data of a particular person. In this case, it is assumed that the attacker knows the processing context.
The considered algorithm with depersonalization of personal data is a promising and optimal solution to the problems of ensuring information security of data processed in client-server applications with databases.
This algorithm has the following advantages:
- provides protection of personal information from unauthorized access ,including from compromising information when it is leaked through technical channels;
- provides guaranteed access to personal data when applying legitimately;
- obtaining personal information through contextual analysis or by searching is very time-consuming, and often almost impossible;
- permutation parameters are set using a random number generator, which increases the algorithm's resistance to hacking [6].
The greatest efficiency in applying this algorithm is shown when client-server applications with databases contain a large amount of personal data of subjects, which provides the greatest protection.
5.4 Algorithm for ensuring control over the integrity of depersonalized personal data
To reduce the risk of information substitution, as well as control the integrity of information after the algorithm of depersonalization of personal data, it is planned to monitor the integrity of the received data. This is achieved by checking the current checksum of the entire file (generated after the personal data depersonalization algorithm) and the checksum calculated when the file is opened later. For example, using the MD5 hashing algorithm.
this algorithm has the following advantages:
- the size of the file with personal data coming to the algorithm input can be arbitrary;
- to calculate the hash function used in the algorithm, you do not need a key that needs to be stored and entered, which greatly simplifies the software implementation;
- no additional hardware is required to apply this solution. the MD5 hash function calculation algorithm used is part of open cryptographic libraries;
- the algorithm can be implemented as a software add-on to the algorithm for depersonalizing personal data [7].
5.5 DBMS level protections
Also, to ensure the most secure level of information security of a client-server application with a database, it is planned to use the following PostgreSQL DBMS layer protection tools: row protection policies, encryption of Selected Columns, server logging, database replication, etc.
Conclusion
In this abstract, a threat model was formed for a client-server application with a database. Security tools and algorithms that are planned to be used in the future to improve the efficiency of the level of information security of a client-server application with a database are presented and considered. When considering the selected security approaches, solutions, tools, and algorithms for ensuring the security of client-server applications with databases, their advantages and disadvantages were identified.
When writing this abstract, the master's thesis has not yet been completed. Final completion: June 2022. Full text of the work and materials on the topic can be received from the author or his supervisor after the specified date.
References
- Основные аспекты безопасности СУБД: что следует знать [Электронный ресурс] /. – Режим доступа: https://tproger.ru/articles/dbsecurity-basics. – Заглавие с экрана.
- С чего начинается защита базы данных? [Электронный ресурс] /. – Режим доступа: https://www.dataarmor.ru/с-чего-начинается-защита-базы-данных. – Заглавие с экрана.
- Secure Password Authentication Explained Simply [Электронный ресурс] /. – Режим доступа: https://www.codeproject.com/Articles/54164/Secure-Password-Authentication-Explained-Simply. – Заглавие с экрана.
- Системы управления базами данных [Электронный ресурс] /. – Режим доступа: http://www.bseu.by/it/tohod/sdo4.htm – Заглавие с экрана.
- В.К. Волк. Базы данных. Проектирование, программирование, управление и администрирование: учебник – Санкт-Петербург: Лань, 2020. – 244 с.
- А.С. Куракин. Алгоритм деперсонализации персональных данных // Научно-технический вестник информационных технологий, механики и оптики, № 6 (82), 2012. – p.130-135.
- Ю.А. Гатчин, О.А. Теплоухова, А.С. Куракин. Алгоритм контроля целостности деперсонализированных данных в информационных системах персональных данных // Научно-технический вестник информационных технологий, механики и оптики, № 1 (83), 2013. – p.145-147.