
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Анализ тональности текста
- 4.1 Обзор алгоритмов
- 4.1.1 Концепция определения тональности с помощью Bag-of-words
- 4.1.2 Концепция определения тональности с помощью TF-IDF
- Выводы
- Список источников
Введение
В последние годы значительные усилия были посвящены изучению и классификации двух из трех основных компонентов музыки: тонов и ритмов. Но есть ещё и третий компонент, которым уделялось сравнительно меньше внимания – тест песен.
Изучение текстов песен отличается от общего сентиментального анализа, скажем, культурной литературы. Тексты песен могут иметь атрибуты, которые неуместны в литературе или формальной прозе, например повторение, рифмование и ритмическое исполнение. Более того, можно предположить, что тексты могут иметь более высокую тенденцию быть шаблонными или даже клишированными, что делает их более поддающимися анализу шаблонов, чем проза в целом.
1. Актуальность темы
Тексты песен — это неструктурированная информация, обрабатывать которую вручную чересчур трудозатратно. Но собирать и обрабатывать информацию необходимо хотя бы потому, что это даёт возможность получать новую информацию из уже имеющихся данных, с помощью которой можно повысить разнообразие принятых решений. В связи с этим задача автоматического анализа данных является актуальной, и для её решения разработано множество методов и моделей. Одним из методов является Data Mining.
Data Mining — процесс автоматического обнаружения в исходных данных скрытой информации, которая ранее не была известна, нетривиальна, практически полезна и доступна для интерпретации человеком [1].
Данная тема является актуальной задачей, так как эта тематика на сегодняшний день многие музыкальные службы (Apple Music, Яндекс.Музыка) проводят анализ песен, которые слушает пользователь и подстраивает под них плейлисты с тем настроением песен, которые пользователь слушает больше всего.
2. Цель и задачи исследования
Объект исследования: Определение тональности текста песен.
Предмет исследования: Эффективность методов определения тональности текста, применимых для библиотеки тестов песен.
Целью исследования является изучение подходов к анализу тональности текста, а также разработка инструмента для проведения анализа тональности, загруженного текстов песен и генерации статистики на их основе.
Основные задачи исследования:
- изучение алгоритмов для определения тональности текста;
- создание собственного корпуса текстов популярных песен;
- разработка собственного алгоритма определения тональности текста на примере текстов песен известных испонителей;
- разработка программной модели для определения тональности загруженных текстов песен и составления статистических данных на их основе.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- достоинства и недостатки алгоритмов по определению тональности текста;
- достоинства и недостатки определения тональности текста с использованием компьютера.
Планируется, что данная система будет иметь:
- интуитивно понятный пользовательский интерфейс с подсказками;
- оптимизированный алгоритм для работы;
- возможность сохранения результатов сеансов для последующей работы.
3. Обзор исследований и разработок
Исследуемая тема популярна не только в международных, но и в национальных научных сообществах.
В данном разделе будет представлен обзор исследований в области анализа тональности и настроения текстов песен, а также приближённые тематики как американскими, китайскими учеными, так и отечественными специалистами.
3.1 Обзор международных источников
В статье Rachel Harsley, Bhavesh Gupta, Barbara Di Eugenio1, Huayi Li1 «Hit Songs’ Sentiments Harness Public Mood & Predict Stock Market» [2] исследуется взаимосвязь между настроением в текстах песен Billboard Top 100, акциями и индексом доверия потребителей. Авторы предположили, что настроение песен из 100 лучших песен может отражать общественное настроение и коррелировать с изменениями на фондовом рынке.
В статье Yunqing Xia, Linlin Wang, Kam-Fai Wong, Mingxing Xu «Sentiment Vector Space Model for Lyric-based Song Sentiment Classification» [3] утверждают, что классификация настроений песен на основе лирики направлена на то, чтобы присвоить песням соответствующие эмоциональные ярлыки. Авторы выделили 4 проблемы, которые делают неэффективным подход к классификации текста, основанный на модели векторного пространства (VSM) и предлагают решение этих проблем через модель векторного пространства настроений (s-VSM) для представления текстов песен.
3.2 Обзор национальных источников
В статье Н.Ю. Рязанова, К.М. Сперцян «Сравнительный анализ методов определения эмоциональной окраски сообщений в социальных сетях с применением обучения с учителем» [4] рассматривается проблема анализа эмоциональной окраски сообщений в социальных сетях, способы представления текста в виде векторов признаков, анализируются и сравниваются существующие методы определения эмоциональной окраски текста.
В статье Т.А. Семина. «Анализ тональности текста: современные подходы и существующие проблемы» [5] представлены проблемы, связанные с проведением анализа тональности, включающие в себя выявление имплицитной оценки, сарказм и иронию, вопросы дизамбигуации, монотематичности систем, ко-референтности и референции. Представлены компьютерные подходы к улучшению результатов работы программ анализа тональности.
3.3 Обзор локальных источников
На локальном уровне (в работах магистров) не было найдено такой же задачи, однако были найдены работы со мнежной тематикой.
В реферате Пилипенко Артёма Сергеевича «Исследование методов и алгоритмов определения тональности естественно-языкового текста» [6]были рассмотрены и изучены основные алгоритмы для определения тональности текста (Bag-of-words и Word2Vec), их преимущества и недостатки. Также в работе были рассмотрены сервисы и программы, которые используют средства Text Mining.
В реферате Власюка Дмитрия Александровича «Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях» [7] был представлен анализ методов извлечения знаний из сети Интернет и их хранение. Также был проведен разбор моделей баз данных и хранение информации о спортивных состязаниях.
4. Анализ тональности текста
Рассмотрим ключевые понятия, которые необходимо знать для определения тональности текста, также рассмотрим два подхода (алгоритма) для определения тональности текста и средства, которые используют данные алгоритмы.
Анализ тональности, также называемый интеллектуальным анализом мнений, — это подход к обработке естественного языка, который определяет эмоциональный тон, скрытый за основной частью текста. Это популярный способ для организаций определять и категоризировать мнения о продукте, услуге или идее.
Системы анализа настроений помогают собирать информацию из неорганизованного и неструктурированного текста, который поступает из онлайн-источников, таких как электронные письма, сообщения в блогах, заявки в службу поддержки, веб-чаты, каналы социальных сетей, форумы и комментарии. Алгоритмы заменяют ручную обработку данных реализацией, основанных на правилах, автоматических или гибридных методов [8]. Системы на основе правил выполняют анализ настроений на основе предопределенных правил, основанных на лексике, в то время как автоматические системы учатся на данных с помощью методов машинного обучения. Гибридный анализ настроений сочетает в себе оба подхода.
В общем случае, задача анализа тональности текста эквивалентна задаче классификации текста, где категориями текстов могут быть тональные оценки. Примеры тональных оценок:
- позитивная;
- негативная;
- нейтральная (текст не содержит эмоциональной окраски).
Основные этапы анализа тональности приведена на рисунке 1 [9].

Рисунок 1 — Основные этапы анализа тональности
(анимация: 10 кадров, 3 циклов повторения, 57 килобайт)
Рассмотрим процесс сбора информации. Потребители обычно выражают свои чувства на публичных форумах, таких как блоги, форумы, обзоры продуктов, а также в социальных сетях. Мнения и чувства выражаются по-разному, с разным словарным запасом, контекстом написания, использованием кратких форм и сленга, что делает данные огромными и дезорганизованными [4]. Ручной анализ данных о настроениях практически невозможен. Поэтому для обработки и анализа данных используются специальные языки программирования
Подготовка текста — это не что иное, как фильтрация извлеченных данных перед анализом. Он включает в себя выявление и удаление нетекстового контента и контента, который не имеет отношения к области исследования из данных.
На этапе обнаружения оценки каждое предложение отзыва и мнения проверяется на субъективность. Предложения с субъективными выражениями сохраняются, а предложения с объективными выражениями отбрасываются. Анализ тональности выполняется на разных уровнях с использованием обычных вычислительных методов, таких как униграммы, леммы, отрицание и т. д.
Как мы уже говорили ранее, оценку можно условно классифицировать на три группы: положительные, отрицательные и нейтральные. На этом этапе методологии анализа настроений каждое обнаруженное субъективное предложение классифицируется на группы: положительное, отрицательное, хорошее, плохое, нравится, не нравится.
Основная идея анализа — преобразовать неструктурированный текст в значимую информацию.
4.1 Обзор алгоритмов
Анализ тональности использует различные методы и алгоритмы обработки естественного языка, которые мы рассмотрим более подробно в этом разделе.
Основные типы используемых алгоритмов анализа тональности включают:
- на основе правил: эти системы выполняют анализ настроений на основе набора правил, созданных вручную;
- автоматически: системы полагаются на методы машинного обучения, чтобы учиться на данных;
- гибридные системы сочетают в себе подходы, основанные на правилах и автоматические.
Рассмотрим подходы, основанные на правилах. Обычно система, основанная на правилах, использует набор правил, созданных человеком, чтобы помочь идентифицировать субъективность, полярность или предмет мнения.
4.1.1 Концепция определения тональности с помощью Bag-of-words
Модель набора слов Bag-of-words, или сокращенно BoW, — это способ извлечения функций из текста для использования в моделировании, например, с алгоритмами машинного обучения [10]. Подход очень простой и гибкий, и его можно использовать множеством способов для извлечения функций из документов.
Пакет слов - это представление текста, которое описывает появление слов в документе. Это включает в себя две вещи:
- Словарь известных слов.
- Мера наличия известных слов.
Это называется «мешком» слов, потому что всякая информация о порядке или структуре слов в документе отбрасывается. Модель заботится только о том, встречаются ли известные слова в документе, а не где в документе.
Интуиция подсказывает, что документы похожи, если они имеют похожее содержание. Кроме того, только по содержанию мы можем кое-что узнать о значении документа.
Пакет слов может быть таким простым или сложным, как вам нравится. Сложность заключается как в принятии решения о том, как составить словарь известных слов (или знаков), так и в том, как оценить наличие известных слов.
Рассмотрим корпус (набор текстов) документов D {d1, d2… ..dD}, и N уникальных токенов, извлеченных из корпуса C. N токенов (слов) сформируют список, а размер матрица M мешка слов будет задана DX N. Каждая строка в матрице M содержит частоту токенов в документе D (i).
Например, если у вас есть 2 строчки из песни:
- D1: All my loving I will send to you.
- D2: All my loving, darling I will be true.
Он создает словарь, используя уникальные слова из всех документов («my», «loving», «I», «send», «you», «true», «darling»). Как видно из приведенного выше списка, мы не рассматриваем «all», «will», «be» в этом наборе, потому что они не передают необходимую информацию, необходимую для модели.
Матрица M размера 2x6(D = 2 – количество документов, N = 6 – количество слов в словаре) представлена в таблице 1.
Таблица 1 — Матрица M размера 2x6
| My | loving | I | Send | You | True | Darling | |
| D1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| D2 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
В приведенной выше таблице показаны функции обучения, содержащие частоту терминов каждого слова в каждом документе. Это называется подходом «мешка слов», поскольку в этом подходе имеет значение количество вхождений, а не последовательность или порядок слов.
4.1.2 Концепция определения тональности с помощью TF-IDF
TF-IDF (термин «частота-обратная частота документов») — это статистическая мера, которая оценивает, насколько слово релевантно документу в коллекции документов [11].
TF-IDF был изобретен для поиска документов и получения информации. Он работает, увеличиваясь пропорционально количеству раз, когда слово появляется в документе, но компенсируется количеством документов, содержащих это слово. Таким образом, слова, которые являются общими в каждом документе, такие как this, what и if, имеют низкий рейтинг, даже если они могут встречаться много раз, поскольку они не имеют большого значения для этого документа в частности.
Однако, если слово «ошибка» встречается много раз в документе и не часто встречается в других, это, вероятно, означает, что оно очень актуально [5]. Например, если то, что мы делаем, пытается выяснить, к каким темам относятся некоторые ответы NPS, слово «ошибка», вероятно, будет связано с темой «Надежность», поскольку большинство ответов, содержащих это слово, будут касаться этой темы.
Обычно вес TF-IDF состоит из двух членов:
- частота термина (TF);
- обратная частота документов (IDF).
Первый вычисляет нормализованную частоту термина (TF).
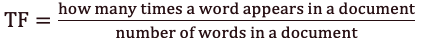
Рисунок 2 — Формула частоты термина (TF)
Рассмотрим текст песни The Way You Make Me Feel Майкла Джексона, содержащий 493 слова, в котором слово «Baby» встречается 10 раз. Тогда термин частоты (TF), для слова Baby равняется 49,3.
Второй член – это обратная частота документов (IDF).
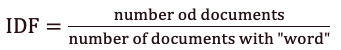
Рисунок 3 — Формула обратной частоты документов (IDF)
Предположим, у нас есть текста 190 песен Майкла Джексона, и слово Baby встречается в 85 из них. Тогда обратная частота документов (IDF) будет равна 0.35.
Формула для определения веса TF-IDF:
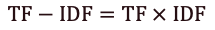
Рисунок 4 — Формула для определения веса TF-IDF
В приведенных выше примерах частота термина равна 49,3, а частота обратного документа – 0,35.
Таким образом, вес TF-IDF является произведением этих величин: 49,3 * 0,35 = 17,2.
Выводы
В ходе выполнения данной работы проанализированы алгоритмы и классификации для идентификации информации. После детального изучения, были выявлены недостатки и плюсы рассмотренных подходов. Как результат проделанного обзора можно отметить следующие направления исследований:
- Подробное исследование методов Bag-of-words и TF-IDF.
- Разработка комбинированных способов.
В частности, интерес представляют методы Bag-of-words и TF-IDF, так как они достаточно просты в понимании и в реализации. Перспективами исследования являются разработка собственного алгоритма на их основе.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2022 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Пескова О. В. Алгоритмы классификации полнотекстовых документов // Автоматическая обработка текстов на естественном языке и компьютерная лингвистика. – М.: МИЭМ (Московский государственный институт электроники и математики), 2011. – С. 170 – 212.
- Rachel Harsley. Hit Songs’ Sentiments Harness Public Mood & Predict Stock Market / Rachel Harsley, Bhavesh Gupta, Barbara Di Eugenio, and Huayi Li // WASSA 16 - 2016 - pp. 17–25 — [Ссылка].
- Yunqing Xia. Lyric-based Song Sentiment Classification with Sentiment Vector Space Model / Yunqing Xia, Linlin Wang, Kam-Fai Wong, Mingxing Xu // ACL-08 - 2008 - pp. 133–136 — [Ссылка].
- Сперцян К.М. Сравнительный анализ методов определения эмоциональной окраски сообщений в социальных сетях с применением обучения с учителем / Н.Ю. Рязанова, К.М. Сперцян. // Новые информационные технологии в автоматизированных системах. Компьютерные и информационные науки. — 2018 — [Ссылка].
- Семина Т.А. Анализ тональности текста: современные подходы и существующие проблемы / Т.А. Семина // Социальные и гуманитарные науки. Отечественная и зарубежная литература. Сер. 6, Языкознание: Реферативный журнал. — 2020 — С. 47-64 [Ссылка].
- Пилипенко А.С., Исследование методов и алгоритмов определения тональности естественно-языкового текста, Донецкий национальный технический университет, 2020 Режим доступа: [Ссылка].
- Власюк Д. А., Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях, Донецкий национальный технический университет, 2018 Режим доступа:[Ссылка]
- Ландэ Д. В. Интернетика Навигация в сложных сетях Модели и алгоритмы. — М.: Книжный дом «ЛИБРОКОМ», 2009. — с. 87-88.
- Классификация текстов и анализа тональности [Электронный ресурс] — [Ссылка].
- Wisam A. Qader. An Overview of Bag of Words; Importance, Implementation, Applications, and Challenges / Wisam A. Qader, Musa M.Ameen, Bilal I. Ahmed //Fifth International Engineering Conference on Developments in Civil & Computer Engineering Applications 2019 - (IEC2019) - Erbil - IRAQ — [Ссылка].
- Bijoyan Das. An Improved Text Sentiment Classification Model Using TF-IDF and Next Word Negation / Bijoyan Das, Sarit Chakraborty // IEEE, Kolkata, India - 2018 — [Ссылка].