Анотация
Классификация настроений песен на основе текста песен направлена на то, чтобы присвоить песням соответствующие эмоциональные ярлыки, такие как беззаботные и тяжелые. Четыре проблемы делают неэффективным подход к классификации текста, основанный на модели векторного пространства (VSM): 1) Многие слова в текстах песен на самом деле мало влияют на настроение; 2) Существительные и глаголы, используемые для выражения чувств, неоднозначны; 3) Отрицания и модификаторы вокруг ключевых слов настроения вносят особый вклад в настроение; 4) Текст песни обычно очень короткий. Для решения этих проблем предлагается модель векторного пространства настроений (s-VSM) для представления текстов песен. Предварительные эксперименты доказывают, что модель s-VSM превосходит модель VSM в задаче классификации настроений песен на основе текста.
1. Введение
Классификация музыкальных композиций в настоящее время становится горячей темой исследований в основном из-за растущего спроса на повсеместный доступ к песням, особенно через мобильный телефон. В своем музыкальном телефоне W910i Sony и Ericsson предоставляют компонент Sense Me, чтобы улавливать настроение владельца и соответственно проигрывать песни. Классификация настроений песен - это ключевая технология для рекомендации песен. Сообщается о многих исследовательских работах, направленных на достижение этой цели с использованием аудиосигнала [1]. Но исследований по классификации песен на основе лирики очень мало.
Предварительные эксперименты показывают, что метод классификации текстов на основе VSM [2] неэффективен при классификации настроений песен (см. Раздел 5) по следующим четырем причинам. Во-первых, модель VSM рассматривает все содержательные слова в тексте песни как элементы классификации текста. Но на самом деле многие слова в песенной лирике мало способствуют выражению настроения. Используя все слова содержания в качестве признаков, методы классификации на основе VSM плохо справляются с классификацией тональности песен. Во-вторых, наблюдение за текстами тысяч китайских поп-песен показывает, что существительные и глаголы, связанные с настроениями, обычно несут множественные смыслы. К сожалению, неоднозначность не обрабатывается должным образом в модели VSM. В-третьих, отрицания и модификаторы постоянно встречаются вокруг слов сантиментов в текстах песен, чтобы перевернуть, усилить или ослабить сантименты, которые несут в себе предложения. Но модель VSM не способна отразить эти функции. Наконец, текст песни обычно очень короткий, а именно 50 слов в среднем по длине, что создает серьезную проблему с разреженными данными в классификации на основе VSM.
Для решения вышеупомянутых проблем модели VSM в данной работе предлагается модель векторного пространства настроений (s-VSM). Мы применяем модель s-VSM для извлечения тонкостей из текстов песен и реализуем алгоритм классификации SVM-light [2] для присвоения тональных меток данным песням.
2. Сопутствующие работы
Классификация тональности песен изучается с 1990-х годов в сообществе специалистов по обработке аудиосигналов, и исследовательские работы в основном основываются на аудиосигнале для принятия решения с использованием алгоритмов машинного обучения [3] [4]. Обычно классы настроений определяются на основе эмоциональной плоскости возбуждения-валентности [5]. Вместо того, чтобы присвоить песням один из четырех типичных эмоциональных ярлыков, Лу [4] предлагает иерархическую структуру для выполнения классификации настроений песен в два этапа. На первом этапе уровень энергии определяется с помощью характеристик интенсивности, а уровень стресса определяется на втором этапе с помощью характеристик тембра и ритма. Доказано, что сложно определить уровень стресса, используя звук в качестве доказательства классификации.
Классификация тональности песни с использованием лирики в качестве доказательства недавно исследована Ченом [6]. Они принимают иерархическую структуру и используют текст песни для определения уровня стресса на втором этапе. Фактически, было выпущено множество литературы, посвященной проблеме анализа тональности в исследованиях обработки естественного языка. Преобладают три подхода: подход, основанный на знаниях [7], подход, основанный на поиске информации [8] и подход машинного обучения [9], в котором используется последний подход. очень популярный. Пэнг [9] применяют модель VSM для представления обзоров продуктов и применяют алгоритмы классификации текста, такие как наивный байесовский алгоритм, максимальная энтропия и вспомогательные векторные машины, для прогнозирования полярности настроений в отношении данного обзора продукта.
Чен [6] также применяют модель VSM в классификации тональности песен на основе лирики. Однако наши эксперименты показывают, что классификация настроений песен с помощью модели VSM дает разочаровывающее качество (см. Раздел 5). Анализ ошибок показывает, что модель VSM проблематична при представлении лирики песни. Для классификации тональности песен необходимо разработать новую модель лирического представления.
3. Модель векторного пространства настроений
Мы предлагаем модель векторного пространства настроений (s-VSM) для классификации настроений песен. Принципы модели s-VSM перечислены ниже.
- Только слова, относящиеся к тональности, используются для создания характеристик тональности для модели s-VSM.
- Слова настроения соответствующим образом устраняют неоднозначность с соседними отрицаниями и модификаторами.
- Отрицания и модификаторы включены в модель s-VSM, чтобы отразить функции инверсии, усиления и ослабления.
Единица настроения - это соответствующий элемент, отвечающий указанным выше принципам.
Чтобы быть общими, мы сначала представим следующие обозначения для лексики настроений.
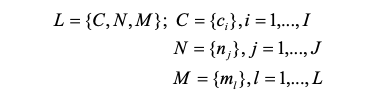
в котором L представляет собой лексику тональности, набор тональных слов C, набор отрицаний N и набор модификаторов M. Эти слова могут быть автоматически извлечены из семантического словаря, и каждому тональному слову присваивается метка тональности, а именно беззаботный или тяжелый в соответствии с его лексическим определением.
Учитывая отрывок из лирики песни, обозначенный следующим образом,
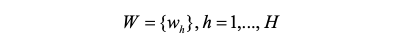
где W обозначает набор слов, которые появляются в тексте песни, семантический лексикон, в свою очередь, используется для определения единиц тональности, обозначенных следующим образом.
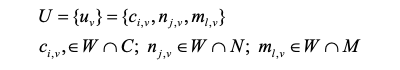
Обратите внимание, что единицы настроения - это однозначные выражения настроения, каждое из которых содержит одно слово настроения и, возможно, один модификатор и одно отрицание. Отрицания и модификаторы полезны для определения уникального значения тональных слов в определенном контекстном окне, например, в нашем случае 3 предшествующих слова и 3 последующих слова. Тогда модель s-VSM представлена следующим образом.
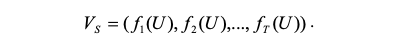
в котором VS представляет вектор тональности для данной лирики песни и особенности тональности fi (U), которые обычно представляют собой определенные статистические данные о единицах тональности, которые появляются в тексте.
Мы классифицируем эмоциональные единицы в зависимости от встречаемости эмоциональных слов, отрицаний и модификаторов. Если слово настроения является обязательным для любой единицы тональности, получается восемь видов единиц тональности. Пусть fPSW обозначает количество слов с положительным настроением (PSW), fNSW количество слов с отрицательным настроением (NSW), fNEG количество отрицаний (NEG) и fMOD количество модификаторов (MOD). В таблице 1 определены восемь тонкостей.
Таблица 1. Определение тональности

Обратите внимание, что одна эмоциональная единица содержит только одно эмоциональное слово. Таким образом, невозможно, чтобы fPSW и fNSW оба были больше нуля.
Очевидно, что проблема разреженных данных может быть решена с использованием статистики по единицам тональности, а не отдельным словам или единицам тональности.
4. Классификация настроений песен на основе текста
Классификацию тональности песни на основе лирики можно рассматривать как задачу классификации текста, поэтому с ней можно справиться с помощью некоторых стандартных алгоритмов классификации. В этой работе алгоритм SVM-light реализован для выполнения этой задачи благодаря его превосходным качествам в классификации текста.
Обратите внимание, что классификация тональности песни отличается от традиционной классификации текста извлечением признаков. В нашем случае сначала обнаруживаются единицы настроения, а затем характеристики настроения генерируются на основе единиц настроения. Поскольку единицы настроения несут однозначные настроения, считается, что модель s-VSM является многообещающей для эффективного выполнения задачи классификации настроений песен.
5. Оценка
Для оценки модели s-VSM вручную создается корпус песни, то есть 5SONGS. Он охватывает 2 653 китайских поп-песен, из которых 1 632 отнесены к категории беззаботных (положительный класс) и 1 021 отнесены к категории тяжелых (отрицательный класс). Мы случайным образом выбираем 2001 песню (около 75%) для обучения, а остальные для тестирования. Мы принимаем стандартные критерии оценки в классификации текстов, а именно: точность (p), отзыв (r), мера f-1 (f) и точность (a) [10].
В наших экспериментах реализуются три подхода к классификации настроений песен: аудиоподход (AB), подход, основанный на знаниях (KB) и подход машинного обучения (ML), в которых также упоминаются два последних подхода. как текстовый (TB) подход. Намерения заключаются в следующем: 1) сравнить подход AB с двумя подходами TB, 2) сравнить подход ML с подходом KB и 3) сравнить подход ML на основе VSM с подходом на основе s-VSM.
Аудио-ориентированный подход
Мы извлекаем 10 характеристик тембра и 2 особенности ритма [4] из аудиоданных каждой песни. Таким образом, каждая песня представлена 12-мерным вектором. Мы запускаем алгоритм SVM-light для обучения на обучающих выборках и классификации тестовых.
Подход, основанный на знаниях
Мы используем HowNet [11], чтобы определять слова настроения, распознавать соседние отрицания и модификаторы и, наконец, определять местоположение единиц настроения в тексте песни. Тональность (SM) единицы тональности (SU) определяется с учетом слов тональности (SW), отрицания (NEG) и модификаторов (MOD) с использованием следующего правила.
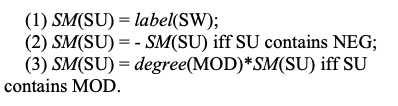
В приведенном выше правиле метка (x) - это функция для чтения метки тональности (∈ {1, -1}) данного слова в лексиконе тональности и степень (x) для чтения степени ее модификации (∈ {1/2 , 2}). Поскольку метки настроения представляют собой целые числа, следующая формула используется для получения метки данного текста песни.
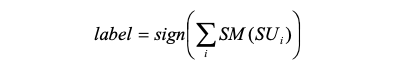
Подход машинного обучения (ML)
Подход ML использует алгоритмы классификации текстов для прогнозирования тональности текста песни. Алгоритм SVM-light реализован на основе модели VSM и модели s-VSM соответственно. Для модели VSM мы применяем алгоритм (CHI) [12] для выбора эффективных характеристик тонального слова. Для модели s-VSM мы используем HowNet в качестве лексикона настроений для создания векторов настроений. Результаты экспериментов представлены в таблице 2.
Таблица 2. Результаты экспериментов
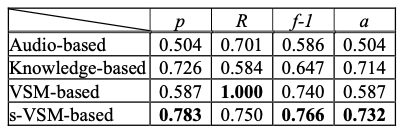
Таблица 2 показывает, что методы на основе текста превосходят методы на основе звука. Это оправдывает наше заявление о том, что текст лучше звука в определении тональности песни. Второе наблюдение заключается в том, что машинный подход к обучению превосходит подход, основанный на знаниях. Третье наблюдение заключается в том, что метод на основе s-VSM превосходит метод на основе VSM по шкале f-1. Кроме того, мы неожиданно обнаружили, что метод на основе VSM присваивает всем тестовым образцам беззаботную метку, таким образом, запоминаемость достигает 100%. Это делает результаты метода на основе VSM недостоверными. Мы изучаем файл модели, созданный с помощью алгоритма SVM-light, и обнаруживаем, что 1868 из 2001 обучающих векторов VSM выбраны в качестве опорных векторов, а 1222 опорных вектора s-VSM выбраны. Это указывает на то, что модель VSM действительно страдает проблемами, упомянутыми в Разделе 1 в классификации тональности песен на основе лирики. Для сравнения: модель s-VSM дает более разборчивые вспомогательные векторы для классификатора SVM, таким образом, дает надежные прогнозы.
6. Выводы и дальнейшие работы
Модель s-VSM представлена в этой статье как модель представления документа для решения проблем, возникающих при классификации тональности песен. Эта модель учитывает единицы настроения в определении характеристик и создает более разборчивые вспомогательные векторы для классификации настроений песен. Некоторые выводы можно сделать из предварительных экспериментов по классификации тональности песен. Во-первых, текстовые методы более эффективны, чем аудио. Во-вторых, подход машинного обучения превосходит подход, основанный на знаниях. В-третьих, модель s-VSM надежнее и точнее модели VSM. Таким образом, нам рекомендуется провести дополнительные исследования для дальнейшего совершенствования модели s-VSM в классификации настроений. В будущем мы добавим некоторые лингвистические правила для повышения производительности обнаружения единиц тональности.
Между тем, характеристики настроений в модели s-VSM в настоящее время имеют одинаковый вес. Мы воспользуемся некоторыми методами оценки, чтобы оценить их вклад в модель s-VSM. Наконец, мы также рассмотрим, как модель s-VSM улучшает качество классификации полярности при изучении мнений.
Подтверждение
Исследования в этой статье частично поддерживаются NSFC (№ 60703051) и Университетом Цинхуа в рамках Фонда фундаментальных исследований (№ JC2007049).
Ссылки
1. P. Knees, T. Pohle, M. Schedl and G. Widmer. A Music Search Engine Built upon Audio-based and Web- based Similarity Measures. Proc. of SIGIR'07, pp.47- 454. 2007
2. T. Joachims. Learning to Classify Text Using Support Vector Machines, Methods, Theory, and Algorithms. Kluwer (2002).
3. T. Li and M. Ogihara. Content-based music similarity search and emotion detection. Proc. IEEE Int. Conf. Acoustic, Speech, and Signal Processing, pp. 17–21. 2006.
4. L. Lu, D. Liu and H. Zhang. Automatic mood detection and tracking of music audio signals. IEEE Transac- tions on Audio, Speech & Language Processing 14(1): 5-18 (2006).
5. R. E. Thayer, The Biopsychology of Mood and Arousal, New York, Oxford University Press. 1989.
6. R.H. Chen, Z.L. Xu, Z.X. Zhang and F.Z. Luo. Content Based Music Emotion Analysis and Recognition. Proc. of 2006 International Workshop on Computer Music and Audio Technology, pp.68-75. 2006.
7. S.-M. Kim and E. Hovy. Determining the Sentiment of Opinions. Proc. COLING’04, pp. 1367-1373. 2004.
8. P. D. Turney and M. L. Littman. Measuring praise and criticism: Inference of semantic orientation from as- sociation. ACM Trans. on Information Systems, 21(4):315–346. 2003.
9. B. Pang, L. Lee and S. Vaithyanathan. Thumbs up? Sen- timent Classification using Machine Learning Tech- niques. Proc. of EMNLP-02, pp.79-86. 2002.
10. Y. Yang and X. Liu. A Re-Examination of Text Catego- rization Methods. Proc. of SIGIR’99, pp. 42-49. 1999.
11. Z. Dong and Q. Dong. HowNet and the Computation of Meaning. World Scientific Publishing. 2006.
12. Y. Yang and J. O. Pedersen. A comparative study on feature selection in text categorization. Proc. ICML’97, pp.412-420. 1997.