
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Анализ методов распознавания образов
- 4. Сравнительный анализ методов распознавания символов на изображении
- 4.1. Классические техники компьютерного зрения
- 4.2. Специализированное глубокое обучение
- 4.3. Стандартный подход глубокого обучения
- 5. Математическая постановка задачи анализа изображений
- 5.1. Математическая постановка криетериев классификации и детекции
- Выводы
- Список источников
Введение
В современном мире существует множество вариантов хранения денег начиная от наличных сбережений и заканчивая электронными кошельками. Сбережения одного человека могут храниться сразу в нескольких местах и, со временем, их учет становится все более сложным занятием. В таких ситуациях идеально помогают расчетные таблицы для ведения собственной «бухгалтерии [1]», но не у каждого есть возможность вести большие таблицы в Excel, либо изучать новые технологии для достижения цели. Для этого и необходимы системы, которые позволяют рядовому пользователю контролировать свои финансы без надобности особых знаний в этой области.
1. Актуальность темы
Для облегчения учета финансов потребителя возникает необходимость разработки автоматизированной системы, которая предоставит возможность хранения всей необходимой информации о его доходах и расходах. Взаимодействие с системой будет происходить через мобильное приложение, что позволит добавлять актуальную информацию о состоянии денежных средств. Это позволит потребителю избавиться от бумажных записей и надобности вручную формировать отчетную информацию.
Одним из видов расходов являются покупки в магазине. Существуют ситуации, когда у потребителя есть необходимость в учете приобретенных товаров, либо учете с разбиением их на категории. Анализ изображений чеков позволит сократить время, которое будет затрачено на внесение в систему всех записей с их стоимостью, к минимуму. После успешного анализа изображения чека все необходимые данные о покупке будут автоматически занесены в систему и доступны для редактирования.
2. Цель и задачи исследования, планируемые результаты
Целью работы является повышение эффективности учета финансовых средств потребителя за счёт применения современных методов и алгоритмов анализа изображений.
Основные задачи исследования:
- Провести анализ финансовых операций потребителя с целью выявления их категорий и типов.
- Провести анализ структуры чеков различных типов.
- Провести анализ и сравнение существующих методов и алгоритмов анализа изображений.
- Разработать усовершенствованный алгоритм анализа изображений.
- Провести экспериментальные исследования для анализа разработанных математических моделей.
- Разработать автоматизированную систему для учета финансовых средств потребителя.
Объект исследования: процесс учета потребителем его финансовых операций при помощи анализа изображений
Предмет исследования: методы и алгоритмы анализа изображений.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований, в качестве практических результатов планируется разработка автоматизированной системы анализа изображений чеков для учета финансовых средств потребителя:
- Наличие собственного мобильного и web-приложения.
- Реализация анализа изображений чеков и сохранения их результатов.
- Сохранение результатов анализа, а также дальнейший их просмотр и редактирование.
- Формирование отчетности по заданным критериям.
3. Анализ методов распознавания образов
Анализ чека можно разбить на несколько шагов:
- первый шаг — разбиение чека на строки и их анализ. В данном шаге необходимо определить структуру чека и произвести его разбиение на строки. Найденные строки затем распределить по группам (информация о магазине, информация о товаре, информация об оплате и т. д.);
- второй шаг — фильтрация. На этом этапе уже имеются группы найденных строк, поэтому необходимо определить те, информация с которых будет использована в дальнейшем;
- третий шаг — символьное разбиение строк с целью получения их информации и сумм. Производится анализ каждой строки из группы. Например, при анализе информации о товаре будут определены: наименование, приобретенное количество, цена за единицу продукции и общая цена за данный товар.
Краткий алгоритм анализа представлен на рис. 1.

Рисунок 1. Анализ изображения чека.
(анимация: 4 кадра, 10 циклов повторения, 89.93
килобайт)
Каждый магазин имеет свою структуру чека, но у всех чеков есть общие параметры, такие как: наименование товара; количество купленных товаров; цена за единицу товара; итог по товару; итог по всему чеку (рис. 2 —4).

Рисунок 2. Пример чека из магазина
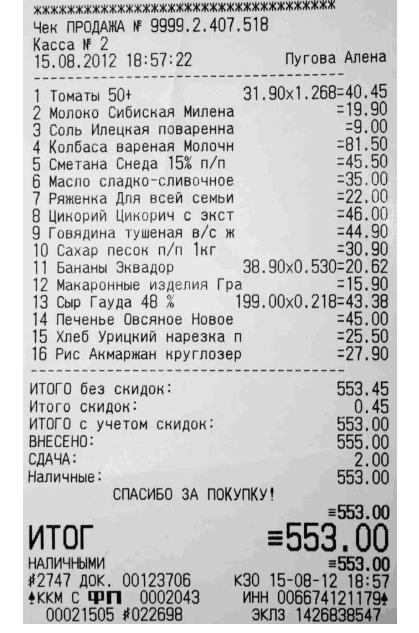
Рисунок 3. Пример чека из магазина

Рисунок 4. Пример чека из магазина
4. Сравнительный анализ методов распознавания символов на изображении
Для распознавания символов на изображении используется технология под названием «OCR». Оптическое распознавание символов (OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко применяется для преобразования книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице [2].
Оптическое распознавание позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Распознавание текста состоит, в основном, из 2 этапов. Во-первых, необходимо определить положение текста на изображении [3].
Во-вторых, после нахождения строки все методы можно объединить в 3 следующие группы:
- Классические техники компьютерного зрения.
- Специализированное глубокое обучение.
- Стандартный подход глубокого обучения.
4.1. Классические техники компьютерного зрения
Подход классического компьютерного зрения состоит из:
- Бинаризации;
- Морфологических операций;
- Построении объекта;
- Выделении контура для набора символов;
- Выделение объектов символов;
- Классификация символов при помощи машинного обучения.
Чем лучше выполнено выделение объектов символов — тем лучше будет их классификация [4].
Однако, для более точного определения контура требуется очень тщательная настройка параметров, которая, порой, является невозможной.
4.2. Специализированное глубокое обучение
Данные подходы отличаются своей универсальностью. Это дает им преимущество, по сравнению с ручной настройкой, но, в некоторых ситуациях, делает их недостаточно точными [5].
К ним можно отнести:
- EAST
- CRNN
- STN-net/SEE
4.3. Стандартный подход глубокого обучения
Суть данного метода заключается в том, что после обнаружения символов применяются стандартные подходы глубокого обучения для обнаружения объектов, такие как SSD, YOLOv3 и Mask RCNN.
Главной особенностью данного подхода является то, что для его успешной работы нужна хорошо обученная модель нейронной сети [6].
После сравнения был выбран 1 метод.
Для определения корректности детектирования и классификации объекта будут рассматриваться следующие критерии:
- Критерий объединение через пересечение (IoU);
- Точность (Accuracy);
- Точность (Precision);
- Полнота (Recall);
- F-мера.
5. Математическая постановка задачи анализа изображений
Пусть U — множество образов в данной задаче анализа. Отдельный образ из этого множества будем обозначать символом x. Каждый образ x∈U может характеризоваться бесконечным (и даже несчетным) числом признаков. На этапе формирования алфавита признаков мы должны выбрать некоторое подмножество признаков (как правило, конечное), которое называют пространством признаков. Это множество будем обозначать через X. Как правило, множество X снабжено линейной или метрической структурами. Чаще всего X — конечномерное метрическое (X = Rn) или линейное пространство. Пусть x — элемент пространства X, соответствующий образу x∈U, а P:U → X — оператор, отображающий x в x.
Заметим, что оператор P является оператором проектирования, т.е. P2 = P. Кроме того, X = P (U).
Предположим, что во множестве образов U в данной задаче анализа нас интересуют некоторые подмножества — классы. В классической задаче классификации считается, что множество классов Ω ={ω ω1,..., m} является конечным, и классы образуют полную группу подмножеств из U (разбиение пространства образов U ), т.е. U и ϖ ∩ ϖi = ∅ для всех i ≠ j . В общем случае классов может быть и бесконечно много, и они могут не составлять полную группу множеств.
Классифицировать образ x∈U по классам ω,...,ωm — это значит найти так называемую индикаторную функцию g:U →Y, Y ={y1,..., ym}, которая ставит в соответствие образу x∈U метку yi ∈Y того класса ϖi , которому он принадлежит, т.е. g x( ) = yi , если x∈ϖi .
Реально мы имеем дело не со всем множеством образов U, а только с проекцией X = P(U) — пространством признаков. Тогда требуется найти такую функцию g:X →Y, которая ставила бы в соответствие каждому вектору x=Px∈X метку yi ∈Y того класса ϖi , которому принадлежит соответствующий образ, т.е. g(x)= yi , если x= Px, x∈ϖi . Такая функция называется решающей.
Заметим, что множество P−1x, x∈ X может не быть одноэлементным, поэтому оно может иметь непустые пересечения с разными классами ϖi.. Следовательно, функция g(x) будет неоднозначной. В этом смысле задача классификации (распознавания) является некорректной задачей. В соответствии с общим подходом решения некорректных задач, из многозначной функции g(x) можно выделить однозначную ветвь, если потребовать, чтобы она удовлетворяла определенным условиям оптимальности. В качестве такого критерия оптимальности может выступать минимальность ошибки неправильной классификации.
В пространстве признаков X множеству классов Ω ={ω,..., ωm} соответствует некоторое, вообще говоря, покрытие X1,...,X m пространства X :
Xi ={x = Px:x∈ϖi}, i =1,...,m. Множества X1,...,X m могут, вообще говоря, пересекаться. Поэтому вместо покрытия X1,..., X m будем рассматривать разбиение X1,...,X m пространства X такое, что Xi ⊆ Xi . Такое разбиение будет определяться неоднозначно. Чем «правильнее» выделены наиболее информативные признаки, тем «степень неоднозначности» выбора разбиения X1,...,Xm будет меньше. Области Xi будем называть областями предпочтения классов ϖi. Как правило, на этапе обучения системе распознавания доступна информация о классах в виде некоторого множества пар (xj, yj), j=1,...,N , где xj = Pxj , y j = g(xj)∈Y . Множество Ξ ={x1,...,xN} называют обучающей выборкой, а пару (xj, y j ) — прецедентом. По множеству прецедентов (Ξ,Y) = {(xj , yj): j=1,...,N} требуется найти решающее правило — функцию g(x), которая осуществляла бы классификацию элементов обучающей выборки с наименьшим числом ошибок.
В некоторых задачах (например, при кластеризации данных) множество меток Y неизвестно. В этом случае система анализа сама должна разбить обучающую выборку на классы, исходя из некоторых критериев оптимальности [7-9].
5.1. Математическая постановка криетериев классификации и детекции
Критерий объединение через пересечение (IoU):
Заключается в отношении пересечения и объединения областей найденного объекта с ожидаемым [10].
$$ IoU = {Пересечение объектов \over Объединение объектов} \xrightarrow . 1 $$Точность (Accuracy) [11]:
$$ Accuracy = {P \over N} \xrightarrow . 1 (max) $$где P — количество объектов классифицированных верно
N — количество объектов классифицированных неверно
Точность (Precision) и Полнота (Recall):
Точность (precision) и полнота (recall) являются метриками, которые используются при оценке большей части алгоритмов извлечения информации. Иногда они используются сами по себе, иногда в качестве базиса для производных метрик, таких как F-мера или R-Precision [12].
Суть точности и полноты очень проста. Точность системы в пределах класса — это доля документов, действительно принадлежащих данному классу относительно всех объектов, которые система отнесла к этому классу. Полнота системы — это доля найденных классфикатором объектов, принадлежащих классу относительно всех объектов этого класса в тестовой выборке.
Значения критериев приведены в таблице 2.1.
Таблица 2.1. Значения критериев
| Экспертная оценка | |||
| Положительная | Отрицательная | ||
| Оценка системы | Положительная | TP | FP |
| Отрицательная | FN | TN | |
$$ Precision = {𝑇𝑃 \over TP + FP} \xrightarrow . 1 $$
где TP — истинно-положительное решение
FP — ложно-положительное решение
$$ Precision = {𝑇𝑃 \over TP + FN} \xrightarrow . 1 $$ $$ Precision = {𝑇𝑃 \over TP + FN} \xrightarrow . 1 $$где TP — истинно-положительное решение
FN — ложно-отрицательное решение
F-мера:
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
$$ F = 2 {Precision * Recall \over Precision + Recall} \xrightarrow . 1 $$Выводы
Исходя из анализа методов распознавания объектов и классификации символов было принято решение использовать нейронные сети в связке со стандартными методами глубокого обучения. Так как большинство чеков имеют собственную структуру, то будет необходимо обучить нейронную сеть таким образом, чтобы она смогла распознавать информацию на всех видах чеков.
Для определения точности распознавания будут использоваться критерии классификации и детекции. Таким образом, можно будет определить в какой момент обучение будет оптимальным.
На данном этапе выполнения магистерской работы были определены цель и задачи для автоматиированной подсистемы,проведен сравнительный анализ существующих автоматизированных систем. Были определены математические методы на основании которых будет реализовываться функционал программы. Разработана структура подсистемы.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: май 2022 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Что такое бухгалтерия и бухгалтерский учет [Электронный ресурс]. — Режим доступа: https://doprof.ru/stati/chto-takoe-buxgalteriya....
- OCR (optical character recognition) [Электронный ресурс]. — Режим доступа: https://searchcontentmanagement.techtarget.com/definition/OCR....
- Optical Character Recognition: What is It and How Does it Work [Электронный ресурс]. — Режим доступа: https://www.v7labs.com/blog/ocr-guide.
- Deep Learning vs. Traditional Computer Vision / Niall O’ Mahony, Sean Campbell, Anderson Carvalho, Suman Harapanahalli, Gustavo Velasco Hernandez, Lenka Krpalkova, Daniel Riordan, Joseph Walsh: Мир, 2019. — 5 с.
- Deep Learning vs Classical Machine Learning [Электронный ресурс]. — Режим доступа: https://towardsdatascience.com/deep-learning-vs-classical....
- Small Data requires Specialized Deep Learning [Электронный ресурс]. — Режим доступа: https://www.kdnuggets.com/2015/03/small-data-specialized-deep....
- Кулясов C. М. Математические методы преобразования изображений с целью выравнивания освещенности и контрастирования слаборазличимых объектов / Кулясов C. М.: Москва, 2003. — 53 с.
- Маликов Р.Ф. Методы математического моделирования обработки и анализа изображений в модифицированных дескриптивных алгребрах изображений / Маликов Р.Ф.: Уфа, 2017. — 25 с.
- Dmitry A. Perfil`ev Segmentation Object Strategy on Digital Image / Dmitry A. Perfil`ev: Journal of Siberian Federal University. Engineering & Technologies, 2018. — 215 с.
- Intersection over Union (IoU) for object detection [Электронный ресурс]. — Режим доступа: https://www.pyimagesearch.com/2016/11/07/intersection...
- Everything You Ever Wanted To Know About Computer Vision. [Электронный ресурс]. — Режим доступа: https://towardsdatascience.com/everything-you-ever-wanted...
- How to Calculate Precision, Recall, and F-Measure for Imbalanced Classification [Электронный ресурс]. — Режим доступа: https://machinelearningmastery.com/precision...