Автор перевода: Ломакин Е.С.
Источник: Proc AMIA Symp. 2002 : 56—60.
Современная система оптического распознавания символов в реальной клинической
практике.
Пол Г. Биондич, доктор медицины, Дж. Марк Оверхэдж, доктор медицины, доктор философии, Пол Р. Декстер,
доктор медицины, Стивен М. Даунс, доктор медицины, Ларри Леммон, Клемент Дж. Макдональд, доктор медицины
Регенстриф, Институт здравоохранения и Индиана, Школа медицины, Индианаполис, Индиана
Аннотация
Достижения в области программного обеспечения для оптического распознавания символов (OCR) и
компьютерного
оборудования стимулировали переоценку технологии и ее способности собирать структурированные клинические
данные из ранее существовавших бумажных форм. В ходе нашей экспериментальной оценки мы измерили точность
и
осуществимость сбора данных о жизненно важных функциях из педиатрической формы обращения, которая
использовалась в течение последних двадцати лет. Мы обнаружили, что это программное обеспечение имеет
уровень распознавания цифр в целом 92,4% (95% доверительный интервал: 91,6—93,2). Что еще более важно,
эта
система была примерно в три раза быстрее, чем наш существующий метод ввода данных. Эти предварительные
результаты предполагают, что с дальнейшим усовершенствованием подхода и дополнительной разработкой мы
сможем
включить OCR в качестве еще одного метода сбора структурированных клинических данных.
Вступление
Сбор структурированной клинической информации —первый и самый сложный шаг на пути к развитию электронной медицинской документации (ЭМИ). В последние годы мы сосредоточились на разработке компьютерных рабочих станций для сбора заказов врачей, клинических заметок и других данных [1]. Благодаря обширной обратной связи с пользователем электронный ввод приказов врача стал успешным во всей больнице и во многих клиниках. Мы также добились определенных успехов в работе с врачебным центром клинических заметок на этом же рабочем месте [2].
Однако стили работы, навыки работы с клавиатурой, рабочий процесс и клиническое содержание сильно различаются среди врачей и специалистов, и процесс преобразования бумаги в рабочие станции остается медленным. В результате ручка и бумага остаются часто используемым методом клинических заметок и записи данных в нашей больничной системе. Несмотря на хорошо известные проблемы с разборчивостью и логистикой, бумага прочно удерживает поставщиков медицинских услуг. Это привычный, легкий, гибкий и быстрый [3]. Сегодня мы можем включать изображения этих документов в EMR посредством сканирования документов. Кроме того, компьютеризированная интерпретация печатного текста или технология оптического распознавания символов (OCR) дает возможность структурировать эту клиническую информацию.На этом фоне мы спросили, могут ли интегрированные решения OCR обеспечить хорошее решение для сбора данных, которое врачи могли бы использовать в нескольких клинических установках. Некоторые добились успехов с этой технологией [4,5,6]. Действительно, мы исследовали ОЦР в середине и конце 70-х годов, когда мы распознали артериальное давление и другие клинические измерения по бумажным формам контактов [7]. В то время у технологии были существенные ограничения. Для этого требовались специальные карандашные карандаши, а форма требовала перепечатки с использованием специальных ссылок. Кроме того, тогдашние сканеры не могли предоставить цифровое изображение в виде хранилища записей. Мы также столкнулись со сложными логистическими проблемами, связанными с физической доставкой анкет из клиник на центральную станцию чтения. Это означает копирование и формы, которые никогда не доходили до входной станции.
Последние достижения в области аппаратного обеспечения и технологии оптического распознавания текста устранили многие эти проблемы. Для оптического распознавания текста больше не требуется специальной формы для печати, напечатанной со специальными чернилами. В настоящее время технологию можно читать с форм, напечатанных на черно-белых лазерных принтерах. Готовые документы можно сканировать на месте и отправлять на централизованную станцию оптического распознавания текста, избегая логистических проблем, связанных с копированием и транспортировкой. Кроме того, отсканированный документ можно сохранить как изображение в медицинской записи. С учетом этих достижений мы решили проверить осуществимость и ошибки при записи данных в форматеOCR с бумаги, используя фактические данные в реальных клинических настройках. Для проведения экспериментального исследования данные состояли из рукописных номеров, записанных в слегка измененной версии наших стандартных печатных форм по требованию и встречных форм.
Истоки:Система Regenstrief Medical Records (RMRS) собирает информацию о назначениях и предоставляет клиникам индивидуализированные бумажные формы обращений [8]. Показатели жизнедеятельности и другие числовые наблюдения записываются от руки в поля, отображаемые в столбце слева от каждой формы. После того, как опекуны заполняют эти формы обращения, они фотокопируются и отправляются по почте университетского городка в Regenstrief Institute. Обученные специалисты по данным интерпретировать рукописные значения и ключевые результаты в программе сбора данных в RMRS. Эта программа затем отправляет эти результаты в виде сообщения HL7 в хранилище данных RMRS. При разработке нашего пилота мы стремились исключить этап ввода данных, но в остальном сохранить существующий рабочий процесс.
Методы.Мы получили одобрение на исследование от Институционального наблюдательного совета Университета Индианы, который также является его членом в больнице Вишарда.
Сбор данных:Мы провели исследование в детской амбулаторной клинике Wishard Memorial Hospital, расположенной в центре Индианаполиса. Формы встреч были составлены RMRS и завершены клиническим персоналом и персоналом службы поддержки, которым они трудились более двадцати лет. Сотрудники клиники сдали заполненные формы в сканирующее устройство предприятия Digital Sender 8100C (Hewlett Packard, Пало-Альто, Калифорния, http://www.hp.com), которое было помещено в регистрационную зону клиники вместе с набором инструкций. TheDigitalSende принимает пакет заполненных форм обращения, а затем создает файл в формате TIFF с несколькими страницами, содержащий оцифрованные выходные данные с разрешением 300 точек на дюйм. Эти файлы отправляются по электронной почте на сервер в Институте регенерации через соединение с сетью нашей больницы, расположенной за переадресацией.
Мы использовали Teleforms Elite 7.1rm (Vista, Калифорния, http://www.cardiff.com), интегрированный механизм распознавания программного обеспеченияOCR, чтобы обработать рукописные числа, однозначно противоположно. Программное обеспечение считывает как напечатанные на компьютере, так и рукописные буквенно-цифровые символы, содержащиеся в зонах распознавания, которые определены путем создания шаблонов для конкретных форм. Копия этого программного обеспечения была установлена на наш серверный компьютер с использованием операционной системы Windows XP и почтового клиента Microsoft OutlookXP. Этот сервер получает электронную почту от Digital Sender, а интерфейс, включенный в Teleforms, автоматически извлекает TIFF из почтового ящика Oudook для обработки.
Адаптация формы счетчика для OCR:RMRS генерирует специфические для пациента формы встреч на основе таких переменных, как запланированная клиника, возраст пациента, история иммунизации и т. Д. Существующие формы должны быть немного изменены для считывающего устройства OCR (рис. 1), поскольку фактическое пространство, отведенное для письменной записи, было слишком маленьким и не давало подсказок для правильного размещения. (рис. 2)»
В ходеэкспериментального тестирования стало ясно, что требуется еще больше сигналов, чтобы указать положение десятичной точки и добавить значения двух частей, таких как фунты и унции. В окончательной версии формы, использованной для нашего пилотного исследования, было три пробела для целой части значения и два пробела для указания десятичной позиции. (рис. 3)

Рисунок 1. Оригинал записи
Рисунок 2. Пробная версия OCR
Рисунок 3. Финальная версия с проверенными записями
Источники данных:
150 форм были отправлены через сервер DigitalSendertoourOCR обслуживающим персоналом педиатрической клиники в течение шести дней. В этих формах потенциально записано пятнадцать или более числовых наблюдений, но в этой совокупности для посещений были заполнены три поля: рост (дюймы), вес (в фунтах и унциях) и окружность головы (счетчики импульсов). Медсестры всегда вводят информацию о весе и росте, а врачи измеряют и вводят значения окружности головы пациента. Восемь медсестер и девятнадцать врачей заполнили формы в течение шестидневного периода. Медсестры были проинформированы об испытании системы сканирования и получили краткие инструкции; врачи —нет.
DataEvaluation:Шаблон встречной формы был создан с помощью приложения «Конструктор» в пакете Teleform. Мы применили несколько алгоритмов предварительной обработки, чтобы удалить предварительно напечатанные поля гребенки, которые мы добавили для управления вводом каждого из шести полей, представляющих интерес на этом шаблоне. Каждая форма имеет верхнее и нижнее значение порога достоверности. Когда характеристика анализируется программным обеспечением, оценка, которая соответствует уверенности механизма распознавания текста в идентификационной информации. Если значение достоверности цифры превышает верхний порог формы, программное обеспечение принимает это значение как «правильное». Если достоверность находится между двумя пороговыми значениями, программа делает лучшее предположение и помечает цифру для проверки. Для значений достоверности ниже нижнего порога программное обеспечение не предпринимает попыток и вводит символ-заполнитель для исправления верификатором данных. Мы выбрали верхний порог в 95% и нижний порог в 5% для этих форм встречи. После заполнения шаблона формы затем обрабатывались с помощью приложения «Reader» для обеспечения согласованности результатов.
Чтобы оценить точность программного обеспечения, мы сопоставили общее количество цифр и числовых значений во всех отправленных формах и классифицировали каждую как введенную медсестрой или врачом. Каждая форма проверяется вручную в приложении «Verifier» одним из авторов (PB), чтобы установить золотой стандарт для правильных показаний.
Результат каждой цифры был классифицирован в зависимости от того, попадает ли он в высокий (> 95%) доверительный диапазон и не требует проверки, находится ли он ниже низкого (<5%) диапазона достоверности и может быть введен вручную, или требуется ли проверка распознанной цифры (5—95%). Все эти результаты были внесены в электронную таблицу вместе с некоторыми описательными комментариями об успехах и сбоях программного обеспеченияOCR.
Чтобы оценить удобство использования и скорость компьютеризированного процесса проверки, мы передали распечатанные копии 150 форм встреч нашему самому опытному клерку по вводу данных для традиционного ручного ввода. Примерно через два часа инструктажа и ознакомления, мы попросили того же клерка обработать эти формы после того, как проверочная заявка была обработана в третий раз механизмом ОЦР. Оба метода сбора данных были приурочены к сравнению.
Полученные результаты150 форм в этом исследовании содержали в общей сложности 982 цифры и 564 различных числовых значения. Эти 982 цифры представляют собой 805 различных цифр, введенных медсестрами и 177 цифр, введенных врачами. В целом программное обеспечение могло распознать цифру с достоверностью более 95% в 58% случаев. Цифры, написанные медсестрами, были назначены с более высоким средним уровнем достоверности, чем врачи. Примерно 42% значений требуют некоторой формы обзора (либо ниже среднего) (рис. 4).
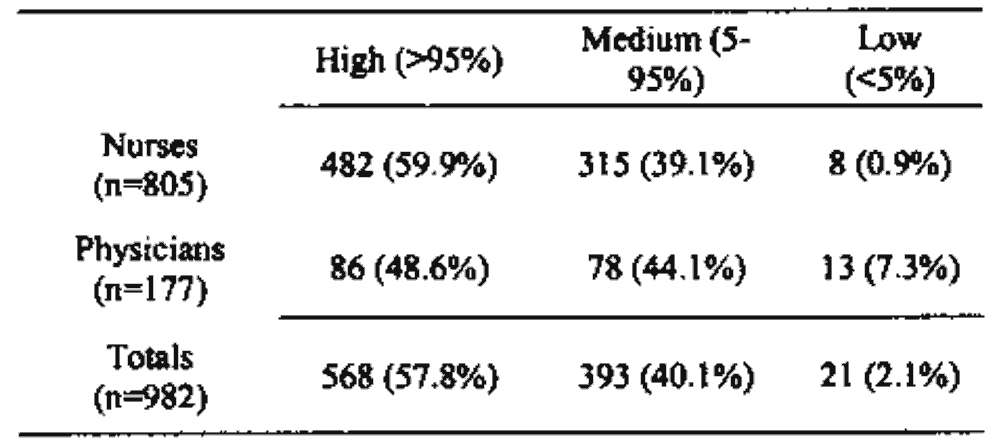
Рисунок 4. Результаты тестирования
Подавляющее большинство всех написанных цифр было правильно распознано программным обеспечением (92,4%, 95% доверительный интервал (ДИ): от 91,6 до 93,2). Не было ошибок для 453 цифр, которым присвоены значения доверительной вероятности более 95% (рис. 5).
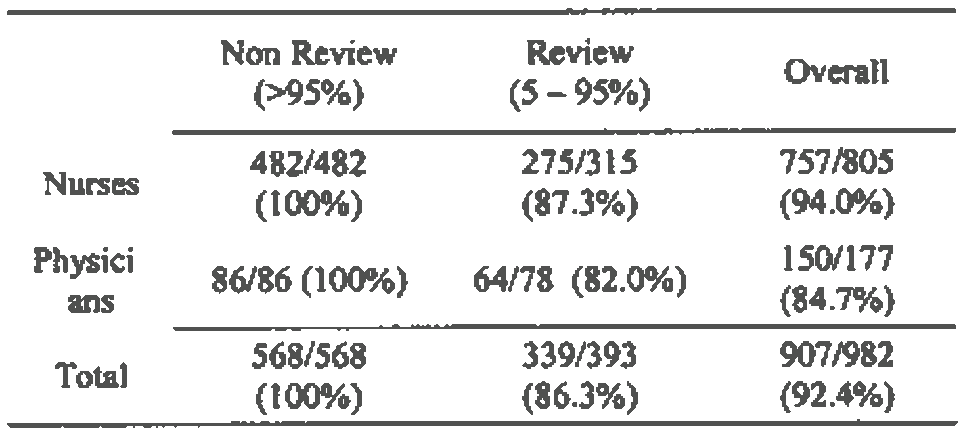
Рисунок 5. Результаты тестирования
Цифры, введенные медсестрами, распознавались более точно (94,0%, 95% ДИ: 93,2—94,8), чем цифры, введенные врачами (84,7%, 95% ДИ: 82,0—87,4). При просмотре числовых значений 499 из 564 были прочитаны правильно (88,5%, 95% ДИ: от 87,2 до 89,8). Эти результаты совпадали в обоих наборах данных.
139 из 150 форм (92,7%) содержали как минимум одну цифру, которая потребовала бы проверки в реальном развертывании с использованием наших пороговых значений достоверности. Программное обеспечение допустило 75 индивидуальных ошибок распознавания, но 43% из-за перечеркивания, ввода дробных значений и несоблюдения указаний (рис. 6).

Рисунок 6. Человеческие ошибки, которые привели к ошибкам распознавания
Сотруднику по вводу данных потребовалось около 36 минут, чтобы вручную ввести информацию из зон распознавания бумажных копий. форм встречи. На этот раз включил руководство просмотр набранных результатов. С другой стороны, это позволило ей выполнить задачу примерно за 12 минут. Персонал клиники с легкостью включил Цифрового отправителя в свой рабочий процесс. Хотя некоторые изображения TIFF поступали перекошенными и даже перевернутыми, программное обеспечение во всех случаях исправляло их ориентацию, делая их пригодными для оценки и архивирования. Они также имели отличное разрешение и не содержали артефактов. Кроме того, сотрудники предпочли модифицированную версию формы столкновения, даже несмотря на то, что эта форма имела немного меньший темп, доступный на оставшуюся часть их заметки.
ОбсуждениеВ условиях человеческого письма частота ошибок, присущих OCR, скорее всего, всегда будет больше нуля. Следовательно, необходим ручной просмотр подмножества интерпретированных результатов. В ходе нашего экспериментального исследования мы обнаружили, что общая частота ошибок при распознавании чисел составляет 8%. Оценка 75 ошибок распознавания показала, что цифры, записанные врачом, были более подвержены ошибкам (27/177 или 15%), чем цифры, введенные медсестрой (48/805 или 6%). В этом исследовании мы не проинформировали врачей о том, что формы будут прочитаны программным обеспечением OCR, и не провели обучение. В результате ошибки распознавания в этих формах были представлены.
Кажется вероятным, что эти и другие типы ошибок можно уменьшить с помощью обратной связи и обучения, а также путем выделения большего количества места для полей записи. Несмотря на то, что ошибка является значительной, она становится более допустимой, учитывая надежность процесса проверки автоматизированной системы. В нашей системе мы собираем данные через обученных клерков, которые вводят номер медицинской карты пациента, затем выбирают тип формы встречи и вводят значения, которые они читают, в левой части формы встречи. Эти введенные значения необходимо распечатать и окончательно сверять с исходными отчетами. Однако с пакетом Teleform этот процесс упрощается и ускоряется. Приложение проверки показывает большую часть формы и выделяет переменную, которую необходимо просмотреть, вдоль части экрана. В нижней части компьютерная интерпретация цифр помещена в непосредственной близости от увеличенного изображения области интереса, записанного сотрудником. Цифры имеют цветовую кодировку, чтобы выделить тех, кто нуждается в просмотре.
Без конфигурации нажатие клавиши табуляции означает принятие наилучшего предположения программного обеспечения. Это позволяет проверяющему быстро проходить через сомнительные области (рис. 7).

Рисунок 7. Пример успешного результата
В этом пилотном испытании мы продемонстрировали, что этот пакет проверки, наряду с присущей программному обеспечению скоростью распознавания, позволяет клерку по вводу данных проверять и исправлять неверно распознанные значения в три раза быстрее, чем наш текущий самый быстрый метод ввода данных. Это значительное улучшение требований к человеческому времени особенно впечатляет, учитывая другие преимущества, которые предоставляет система, в первую очередь цифровая копия, которая может храниться в репозитории данных. Необходима дополнительная работа, чтобы подготовить этот процесс к производству. Чтобы связать выходные данные программного обеспечения с электронной записью конкретного пациента, нам необходимо определить другие поля в шаблоне формы встречи для распознавания идентификаторов пациентов, напечатанных на компьютере. Также есть планы оценить методы, в которых идентичность каждого отсканированного поля может быть распознана по соответствующей этикетке, уже напечатанной на форме. Распознавание компьютерного текста считается очень надежным, но мы не тестировали эту функцию в нашем исследовании.
Специализированная форма встречи отправляет специальные документы для сбора данных, которые печатаются по запросу. Подход, используемый для формы встречи в педиатрических клиниках, потенциально может быть воспроизведен во всей системе больницы, но вопросы, связанные с настраиваемым контентом и способностью Teleform адаптироваться к этому, должны быть рассмотрены в будущих исследованиях.
Нас обнадеживают начальные данные, полученные в результате экспериментального внедрения этой модели DMOCR. Использование DigitalSender вместе с более надежным программным механизмом с поддержкой форм, по-видимому, устраняет многие препятствия, возникшие при нашей реализации 20 лет назад. Дальнейшие исследования и исследования будут посвящены продолжению тестирования и работе по автоматизации потока данных обратно в RMRS через интерфейс HL7.
Выражение признательности: эта работа была выполнена в Институте здравоохранения штата Индиана в Индианаполисе, штат Индиана, при поддержке участника Национальной библиотеки медицины (T15LM-7117-05).
Использованная литература- Макдональд CJ, Тирни WM. Медицинский Gopher —микрокомпьютерная система, помогающая находить, систематизировать и принимать решения о данных пациента. West J Med 1986; 145 (6): 823—829.
- Оверхэдж Дж. М., Перкинс С. М., Тирни В. М., Макдональд С. Дж. Контролируемое испытание прямого доступа к врачу: влияние на использование времени врачом в практике амбулаторной первичной медицинской помощи по внутренним болезням. JAMIA 2001; Vol. 8: № 4.
- Селлен А.Дж., Харпер Р.Х. Миф об безбумажном офисе. MIT Press, 2002.
- ShiffmanRN, BrandtCA, HoffmanM, WiigW, Fernandes LA. SEURAT: отсканированная запись структурированных данных для записи о медицинском обслуживании педиатров. В кн .: Масыс Д.Р., под ред. Материалы ежегодного собрания Американской ассоциации медицинской информатики; Нэшвилл (Теннесси); 1997; на CD-ROM.
- Шиффман Р.Н., Брандт, Калифорния, Фриман Б.Г. Переход на компьютерный амбулаторный учет с использованием сканируемых структурированных форм встреч. ArchPediatrAdolescMed1997 Dec; 151 (12): 1247—53
- KhouryA, SiemonC, MillsG, KalataM. Медицинская автоматизированная система записи Kaiser PermanenteofOhio. Proceedings of theCPR RecognitionSymposium, 1997: 21—100.
- Бхаргава Б.К., Макдональд С.Дж., Ривера Х.П., Маккарти Л.Дж. Разработка и внедрение компьютеризированной клинической лабораторной системы. Лабораторная медицина 1976; 7 (12): 28—37.
- Макдональд С.Дж., Оверхэдж Дж. М., Тирни В. М., Декстер П. Система медицинских записей Regenstrief. Четверть века опыта. Международный журнал медицинской информатики 1999; 54: 225-253.