
ОТЧЁТ ПО ПРЕДДИПЛОМНОЙ ПРАКТИКЕ
(1.10.01 – 31.12.01)
TU CHEMNITZ
Чепцова Алексея Алексеевича ( ДНТУ, гр. ВТ-97а )
СОДЕРЖАНИЕ
Практика проводилась студентом группы ВТ-97а Чепцовым А.А., в настоящее время обучающемся в магистратуре ДНТУ, в период с 1.10.2001 по 31.12.2001 в техническом университете г.Chemnitz на кафедре теоретиче ской информатики в рамках заключения международного договора о сотрудничестве между Донецким национальным техническим университетом и техническим университетом г.Chemnitz.
Научный руководитель со стороны ДНТУ - зав.кафедрой ЭВМ ДНТУ проф. В.А.Святный
.Научный руководитель со стороны ТУ г.Chemnitz
- руководитель департамента теоретической информатики проф. Г.Рюнгер.
2. Ознакомление с аппаратными ресурсами TU Chemnitz.
TU Chemnitz обладает развитой и довольно обширной системой компьютерной и коммуникационной техники. В качестве базовой единицы данной системы выступают компьютерные классы (в дальнейшем - пул). Каждый под раздел (департамент) TU Chemnitz поддерживает как свою собственную систему коммуникаций, так и обеспечивает доступ к общеуниверситетской компьютерной сети. Все машины работают в среде удалённого доступа к серверу, т.е. для пользователя не существует раз н ицы в хранимых данных при работе на различных терминалах, что в принципе является высоким достижением в области сетевой организации. Общеуниверситетские компьютерные пулы доступны для любого инициируемого пользователя (студента или преподавателя), внут ре ние компьютерные пулы - лишь для сотрудников данного подразделения.
Программное обеспечение единицы компьютерного пула - Linux (версия RedHat 6.2), Windows NT или совмещённые.
Все компьютерные пулы организованы в виде кластеров, что даёт возможности по их использованию при параллельных вычислениях.
TU Chemnitz обладает современным сверхпроизводительным компьютерным центром (HPCC - High Perfomance Computer Center) CLiC. Он объединяет 550 современных компьютерных машин (частота - 850 мГц, способ коммуникации - Fast Ethernet-2). Он доступен в режим е удалённого доступа с любой машины, имеющей выход в университетскую сеть TU Chemnitz.
3. Изучение языка программирования JAVA.
Язык программирования JAVA был отдельно выделен для изучения во время практики, т.к. в настоящее время это один из самых перспективных и популярных языков программирования, обладает концепцией объектно-ориентиро ванного программированния и содержит развитый набор инструментов практически для любой сферы программирования. Отдельной дисциплины по этому языку программирования учебным планом ДНТУ не предусмотрено.
На сегодняшний день JAVA является мощным инструментом объектно-ориентированного программирования. Во время практики особое внимание уделялось как общей идее концепции ООП, так и практическим особенностям применения средств ЯП JAVA (таких, как особенно сти организации многопотоковых клиент-серверских приложений, возможности создания полгноценного интерфейса пользователя и т.д.).
В частности, были рассмотрены возможности языка программирования JAVA для создания сетевых приложений типа "клиент - сервер". Было разработано программное обеспечение клиентской стороны и стороны хоста, в одно- и многопотоковом исполнении.
Были получены навыки в решении задач тривиального взаимодействия между клиентом и сервером в сети с использованием ЯП JAVA по схеме:
Общая характеристика задачи ПО клиента
Общая характеристика задачи ПО сервера
Как можно увидеть, одной из важных частей в структуре ПО клиента является пользовательский интерфейс. Грамотно сделанный пользовательский интерфейс позволяет обеспечить пользователю лёгкое восприятие довольно сложных прогр амм. Были изучены новейшие возможности языка JAVA-2 по построению пользовательских интерфейсов (с использованием библиотеки "
swing" ).Кроме того, были изучены средства параллельного программирования в параллельной версии языка JAVA - JAVA_MPI. Была произведена инсталляция этого языка на HPCC
CLiC.
Одними из самых трудоёмких задач в современной научной деятельности являются проблемы моделирования динамических (изменяющихся) процессов. Из-за высокой применимости в практике моделирующее програмное обеспечени е обязано соответствовать следующим требованиям:
Последний критерий особенно актуален для систем реального времени.
Выполнение этих критериев позволяет достичь параллельное программирование.
Именно основы распараллелизации базовых алгоритмов и построения параллельного программного обеспечения и были главной целью в изучении во время прохождения практики.
В качестве основы для построения параллельного програмного обеспечения выступал стандарт MPI (Message Passing Interface). Базовый язык для реализации - С и JAVA.
Организация аппаратно-программных средств параллельных вычислений в TU Chemnitz.
В TU Chemnitz доступны следующие аппаратные средства для осуществления параллельных вычислений:
Возможно использование до 100 процессоров одновременно. Лёгкий и гибкий механизм для отладки программ. Скорость межузловых обменных операций большая, т.к. все элементы кластера в первую очередь рассчитаны на работу в пользовательском режиме.
Сосредотачивает 550 процессоров, доступных для работы. Основы архитектуры - высокопроизводительные машины класса P3-800, объединённые высокоскоростной системой коммуникации FastEthernet-2. При использовании возможны проблемы с высокой загруженностью д анной системы.

Более подробную информацию по HPCC CLiC и по особенностям его использования можно найти на интернет-сайте TU Chemnitz
www.tu-chemnitz.de
Использование кластеров возможно с любой точки кластера без предворительной подготовки. Все компьютерные пулы оснащены установленным интерфейсом параллельного взаимодействия MPI. Для использования необходимо лишь указать у никальные имена требуемых машин.
Использование HPCC CLiС для параллельных вычислений также возможно в режиме удалённого доступа с любого узла компьютерных пулов TU Chemnitz в виде задачи (с уникальным именем задачи, которое назначается только руководителями департаментов TU Chemnitz) . Задача становится в специальную очередь задач HPCC CLiC , где происходит ожидание разгрузки HPCC для выполнения данной задачи.
Реально приходится ожидать некоторое время лишь при использовании более 100 процессоров.
Благодаря тому, что распараллелиливание на уровни процессов между задачами в HPCC CLiC не происходит, время выполнения задачи минимальное. Т.к. основное время в выполнении параллельной программы отводится на коммуникации между процессорами, современна я коммуникационная система, используемая в HPCC CLiC также определяет минимальное время выполнения программы.
Моделирование процессов в ячеечном автомате на примере задачи "Gam
e of life"Одним из наиболее трудоёмких типов задач в области моделирования является задача управления ячеечным автоматом.
Ячеечный автомат - это набор ячеек, организованных в виде матрицы, содержимое которых изменяется по определённым законам.
Одним из примеров ячеечного автомата может служить концепция жизни (разработанная в 1867 году). В этом примере содержимым ячеек являются жизненные организмы, существование которых зависит от количества соседних с ним организмов.
|
1 (N=0) |
0 (N=1) |
................... |
1 (N=1) |
|
0 (N=1) |
0 (N=1) |
................... |
1 (N=1) |
|
... |
... |
... |
... |
|
0 (N=1) |
1 (N=0) |
................... |
1 (N=0) |
Общий закон функционирования можно представить в виде (с учётом N = кол-во соседних организмов)
При любой реализации и оптимизации алгоритму моделирования необходим полный перебор ячеек автомата, что может быть неоптимально при большом количестве ячеек (например - более 1 миллиона).
В этом случае наилучшей метод оптимизации - распараллеливание алгоритма с разбиением исходной матрицы на М частей (где М - кол-во процессоров).
|
1 (N=0) |
0 (N=1) |
1 (N=0) |
0 (N=1) |
|
0 (N=1) |
0 (N=1) |
0 (N=1) |
0 (N=1) |
\_____________________/\_______________________/
проц.1 ..................................проц. 2
|
1 (N=0) |
0 (N=1) |
1 (N=0) |
0 (N=1) |
|
0 (N=1) |
0 (N=1) |
0 (N=1) |
0 (N=1) |
\_____________________/\_______________________/
проц. 3................................. проц. 4
В этом случае теоретически количество проверочных циклов уменьшается в М раз. Однако реально этого не происходит из-за учёта очень высокого времени межузловых коммуникаций.
В данной реализации решения коммуникационные циклы необходимы для анализа граничных элементов подматриц, имеющих соседние ячейки, размещённые в других подматрицах (и следовательно других процессорах). Обычно, в параллельной программе время коммуникаци онных обменов превышает время самих вычислений в 10-20 раз.
Поэтому при небольших объёмах вычислительных данных более эффективно использовать непараллельную версию программы.
Графически зависимость между объёмом данных и производительностью в параллельном и непараллельном варианте моделирующей программы можно отобразить как:
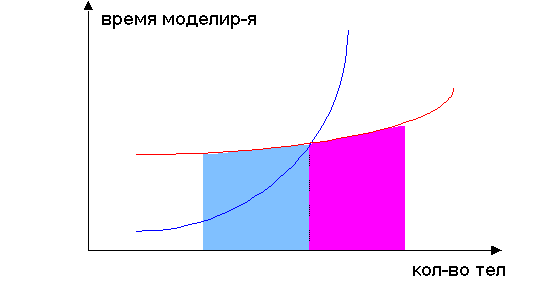
Как было установлено мною в ходе экспериментов, эффективность в использовании параллельной реализации данной задачи возникает при размере решётки более чем 4000х4000.
Для визуализации конечных результатов использовались средства языка JAVA и C++.
Одной из наиболее интересных прикладных задач является группа задач по моделирования поведения определённого количества тел, взаимно связанных между собой некоторой силой. Особую привлекательность данному роду задач придаё т универсальность и переносимость на различные предметные области.
Одной из сфер применения данных вычислений является рассчёт движения астрономических тел, взаимосвязанных между собой силой Ньютона (в роли тел в этой задачи выступают планеты), или так называемая "Gravitational N-Body Problem". Аналогичные задачи при сутствуют в области молекулярной техники и т.д.
Каждое тело (планета) характеризуется следующими параметрами:
![]() масса тела
масса тела
![]() координаты в пространстве (начальные данные задаются пользователем)
координаты в пространстве (начальные данные задаются пользователем)
![]() скорость в пространстве (начальные данные задаются пользователем)
скорость в пространстве (начальные данные задаются пользователем)
Данная задача имеет ряд стандартных и усовершенствованных алгоритмов решения, но ни один из них не позволяет избавиться от полного перебора параметров всех тел для подсчёта силы влияния одних тел на другие, что также определяет необходимость использов ания параллельных алгоритмов решения.
Пример взаимодействия тел
(и следовательно процессоров)
для N=3 астроном. тел.
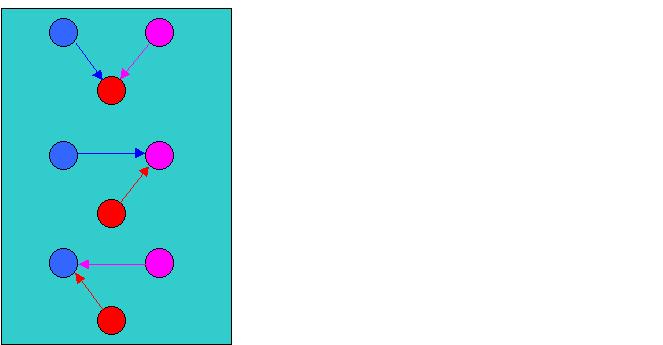
Специально для этой задачи мной был разработан уникальный алгоритм решения данной задачи в паралллельном варианте, который предусматривает минимум коммуникационных операций (которые, как уже уточнялось, самые трудоёмкие в параллельных алгоритмах) с использованием специального метода применения групповых коммуникаций и виртуальных топологий с поддержкой специализированных средств стандарта MPI.
Как и в предыдущей задаче, оптимальность использования параллельного алгоритма возникает лишь при относительно большом количестве моделируемых гравитационных тел. В данном случае использование параллельного варианта целесообразно при количестве планет
> 10000.Результаты оптимизации данной задачи можно представить в следующем виде:
|
Тел \ проц-ров |
5 |
10 |
20 |
40 |
60 |
|
1200 |
0.17 |
0.07 |
0.05 |
0.06 |
0.09 |
|
12000 |
16.54 |
6.7 |
2.95 |
1.37 |
0.92 |
|
24000 |
100.51 |
26.5 |
11.69 |
5.56 |
3.53 |
Увеличение производительности при использовании нового моделирующего программного обеспечения можно представить в таблице:
|
К.тел\проц |
5 |
10 |
20 |
40 |
60 |
|
1200 |
2,6 |
6,28 |
8,14 |
7,3 |
4,94 |
|
12000 |
3,57 |
8,8 |
19,95 |
43 |
63,78 |
|
24000 |
2,22 |
8,38 |
18,9 |
39,92 |
62,9 |
Специально для данной задачи был написан графический интерфейс пользования с использованием средств языка JAVA, позволяющий пользователю легко работать с большими объёмами данных (действительно, как показала практика, несп ециалисту в области информатики довольно трудно самостоятельно редактировать параметры 150000 гравитационных тел !).