Диссертация Библиотека Биография Ссылки
Кластеры и суперкомпьютеры – близнецы или
братья?
Александр Андреев, Владимир Воеводин, Сергей
Жуматий
Источник:
http://www.osp.ru/os/2000/05-06/009.htm
|
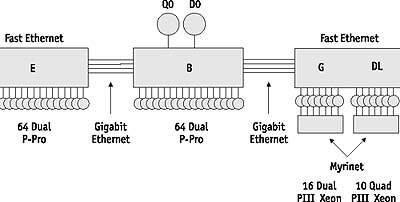
Сегодня вычислительный мир находится в состоянии ожидания чего-то необычного: с одной стороны, появилась уникальная возможность создавать недорогие установки суперкомпьютерного класса – вычислительные кластеры, а с другой, есть устойчивое сомнение в серьезности этого направления. Однако при всех «за» и «против» постоянным обитателям списка Top500 – компаниям Сray, Sun, Hewlett-Packard и другим уже пришлось потесниться, пропустив 11 кластерных установок в элитные ряды чемпионов. А производители сетевых решений на базе cLAN, Myrinet, ServerNet, SCI продолжают и дальше совершенствовать свои технологии, давая возможность практически каждому собрать у себя свой собственный вариант суперкомпьютера.Сразу оговоримся, в компьютерной литературе понятие «кластер» употребляется в различных значениях, в частности, «кластерная» технология используется для повышения надежности серверов баз данных или web-серверов. В данной статье мы будем говорить только о вычислительных кластерах, используемых в качестве доступной альтернативы традиционным «числовым молотилкам» – суперкомпьютерам. Классические суперкомпьютеры всегда ассоциировались с чем-то большим: размеры, гигантская производительность, немереная память и, конечно же, колоссальная стоимость [1]. Первым серьезным прорывом в уменьшении отношения цена/производительность стало появление компьютеров с массовым параллелизмом. Использование серийных микропроцессоров позволило не только гибко менять мощность установки в зависимости от потребностей и возможностей, но и значительно удешевить производство. Примерами суперкомпьютеров этого класса могут служить Intel Paragon, IBM SP, Сray T3D/T3E и ряд других. Единственным способом взаимодействия процессоров в рамках подобных систем было их общение через некоторую коммуникационную среду, объединяющую процессоры в единую вычислительную установку. Например, в компьютерах семейства Сray T3D/T3E все процессоры объединены специальными высокоскоростными каналами в трехмерный тор, в котором каждый вычислительный узел имеет шесть непосредственных соседей. В компьютере IBM SP/2 взаимодействие процессоров идет через иерархическую систему переключателей, потенциально обеспечивающей непосредственное соединение каждого процессора с любым другим. Однако все уникальные решения, да еще и с рекордными характеристиками обычно недешевы, поэтому и стоимость подобных систем никак не могла быть сравнима со стоимостью систем, находящихся в массовом производстве. Шло время, и прогресс в области сетевых технологий сделал свое дело: на рынке появились недорогие, но эффективные коммуникационные решения. Это и предопределило появление кластерных вычислительных систем, фактически являющихся одним из направлений развития компьютеров с массовым параллелизмом (MPP — massive parallel processing). Если говорить кратко, то вычислительный кластер — это совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи. В качестве вычислительных узлов обычно используются доступные на рынке однопроцессорные компьютеры, двух- или четырехпроцессорные SMP-серверы. Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются стандартные операционные системы: Linux, NT, Solaris и т.п. Состав и мощность узлов может меняться даже в рамках одного кластера, давая возможность создавать неоднородные системы. Выбор конкретной коммуникационной среды определяется многими факторами: особенностями класса решаемых задач, доступным финансированием, необходимостью последующего расширения кластера и т.п. Возможно включение в конфигурацию специализированных компьютеров, например, файл-сервера, и, как правило, предоставлена возможность удаленного доступа на кластер через Internet. Ясно, что простор для творчества при проектировании кластеров огромен. Рассматривая крайние точки, кластером можно считать как пару ПК, связанных локальной 10-мегабитной сетью Ethernet, так и вычислительную систему, создаваемую в рамках проекта Cplant в Национальной лаборатории Sandia: 1400 рабочих станций на базе процессоров Alpha, связанных высокоскоростной сетью Myrinet. Чтобы немного почувствовать масштаб и технологию существующих систем, сделаем краткий обзор наиболее интересных современных кластерных установок. Кластерные проектыОдин из первых проектов, давший имя целому классу параллельных систем – кластеры Beowulf [2] – возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проект Beowulf стартовал летом 1994 года, и вскоре был собран 16-процессорный кластер на процессорах Intel 486DX4/100 МГц. На каждом узле было установлено по 16 Мбайт оперативной памяти и по 3 сетевых Ethernet-адаптера. Для работы в такой конфигурации были разработаны специальные драйверы, распределяющие трафик между доступными сетевыми картами. Позже в GSFC был собран кластер theHIVE – Highly-parallel Integrated Virtual Environment (http://newton.gsfc.nasa.gov/thehive/), структура которого показана на рис. 2. Этот кластер состоит из четырех подкластеров E, B, G, и DL, объединяя 332 процессора и два выделенных хост-узла. Все узлы данного кластера работают под управлением RedHat Linux.
В 1998 году в Лос-Аламосской национальной лаборатории астрофизик Майкл Уоррен и другие ученые из группы теоретической астрофизики построили суперкомпьютер Avalon, который представляет собой Linux-кластер на базе процессоров Alpha 21164A с тактовой частотой 533 МГц. Первоначально Avalon состоял из 68 процессоров, затем был расширен до 140. В каждом узле установлено по 256 Мбайт оперативной памяти, жесткий диск на 3 Гбайт и сетевой адаптер Fast Ethernet. Общая стоимость проекта Avalon составила 313 тыс. долл., а показанная им производительность на тесте LINPACK – 47,7 GFLOPS, позволила ему занять 114 место в 12-й редакции списка Top500 рядом с 152-процессорной системой IBM RS/6000 SP. В том же 1998 году на самой престижной конференции в области высокопроизводительных вычислений Supercomputing’98 создатели Avalon представили доклад «Avalon: An Alpha/Linux Cluster Achieves 10 Gflops for $150k», получивший первую премию в номинации «наилучшее отношение цена/производительность». В апреле текущего года в рамках проекта AC3 в Корнелльском Университете для биомедицинских исследований был установлен кластер Velocity+, состоящий из 64 узлов с двумя процессорами Pentium III/733 МГц и 2 Гбайт оперативной памяти каждый и с общей дисковой памятью 27 Гбайт. Узлы работают под управлением Windows 2000 и объединены сетью cLAN компании Giganet. Проект Lots of Boxes on Shelfes (LoBoS, http://www.lobos.nih.gov) реализован в Национальном Институте здоровья США в апреле 1997 года и интересен использованием в качестве коммуникационной среды технологии Gigabit Ethernet. Сначала кластер состоял из 47 узлов с двумя процессорами Pentium Pro/200 МГц, 128 Мбайт оперативной памяти и диском на 1,2 Гбайт на каждом узле. В 1998 году был реализован следующий этап проекта – LoBoS2, в ходе которого узлы были преобразованы в настольные компьютеры с сохранением объединения в кластер. Сейчас LoBoS2 состоит из 100 вычислительных узлов, содержащих по два процессора Pentium II/450 МГц, 256 Мбайт оперативной и 9 Гбайт дисковой памяти. Дополнительно к кластеру подключены 4 управляющих компьютера с общим RAID-массивом емкостью 1,2 Тбайт. Интересная разработка появилась недавно в Университете штата Кентукки – кластер KLAT2 (Kentucky Linux Athlon Testbed 2, http://parallel.ru/news/kentucky_klat2.html). Система KLAT2 состоит из 64 бездисковых узлов с процессорами AMD Athlon/700 МГц и оперативной памятью 128 Мбайт на каждом. Программное обеспечение, компиляторы и математические библиотеки (SCALAPACK, BLACS и ATLAS) были доработаны для эффективного использования технологии 3DNow! процессоров AMD, что позволило увеличить производительность. Значительный интерес представляет и использованное сетевое решение, названное «Flat Neighbourghood Network» (FNN). В каждом узле установлено четыре сетевых адаптера Fast Ethernet от Smartlink, а узлы соединяются с помощью девяти 32-портовых коммутаторов. При этом для любых двух узлов всегда есть прямое соединение через один из коммутаторов, но нет необходимости в соединении всех узлов через единый коммутатор. Благодаря оптимизации программного обеспечения под архитектуру AMD и топологии FNN удалось добиться рекордного соотношения цена/производительность – 650 долл. за 1 GFLOPS. Идея разбиения кластера на разделы получила интересное воплощение в проекте Chiba City (http://parallel.ru/news/anl_chibacity.html), реализованном в Аргоннской Национальной лаборатории. Главный раздел содержит 256 вычислительных узлов, на каждом из которых установлено два процессора Pentium III/500 МГц, 512 Мбайт оперативной памяти и локальный диск емкостью 9 Гбайт. Кроме вычислительного раздела в систему входят раздел визуализации (32 персональных компьютера IBM Intellistation с графическими платами Matrox Millenium G400, 512 Мбайт оперативной памяти и дисками 300 Гбайт), раздел хранения данных (8 серверов IBM Netfinity 7000 с процессорами Xeon/500 МГц и дисками по 300 Гбайт) и управляющий раздел (12 компьютеров IBM Netfinity 500). Все они объединены сетью Myrinet, которая используется для поддержки параллельных приложений, а также сетями Gigabit Ethernet и Fast Ethernet для управляющих и служебных целей. Все разделы делятся на «города» (town) по 32 компьютера. Каждый из них имеет своего «мэра», который локально обслуживает свой «город», снижая нагрузку на служебную сеть и обеспечивая быстрый доступ к локальным ресурсам. Коммуникационные технологии построения кластеровТаким образом видно, что различных вариантов построения кластеров очень много. Одно из основных различий лежит в используемой сетевой технологии, выбор которой определяется, прежде всего, классом решаемых задач. Первоначально Beowulf-кластеры строились на базе обычной 10-мегабитной сети Ethernet. Сегодня чаще всего используется сеть Fast Ethernet, как правило, на базе коммутаторов, основное достоинство которого – низкая стоимость оборудования (40-50 долл. за сетевой адаптер и менее 100 долл. за один порт коммутатора). Однако большие накладные расходы на передачу сообщений в рамках Fast Ethernet приводят к серьезным ограничениям на спектр задач, которые можно эффективно решать на таком кластере. Если от кластера требуется большая универсальность, то нужно переходить на другие, более производительные коммуникационные технологии.
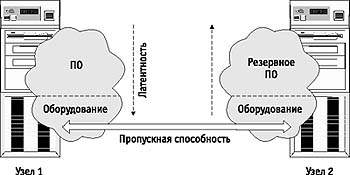
Какими же числовыми характеристиками выражается производительность коммуникационных сетей в кластерных системах? Основных характеристик две: латентность – время начальной задержки при посылке сообщений и пропускная способность сети, определяющая скорость передачи информации по каналам связи (рис. 3). При этом важны не столько пиковые характеристики, заявляемые производителем, сколько реальные, достигаемые на уровне пользовательских приложений, например, на уровне MPI-приложений. В частности, после вызова пользователем функции посылки сообщения Send() сообщение последовательно пройдет через целый набор слоев, определяемых особенностями организации программного обеспечения и аппаратуры, прежде, чем покинуть процессор – отсюда и вариации на тему латентности. Кстати, наличие латентности определяет и тот факт, что максимальная скорость передачи по сети не может быть достигнута на сообщениях с небольшой длиной. Скорость передачи данных по сети в рамках технологий Fast Ethernet и Scalable Coherent Interface (SCI) зависит от длины сообщения. Для Fast Ethernet характерна большая величина латентности – 160-180 мкс, в то время как латентность для SCI это величина около 5,6 мкс. Максимальная скорость передачи для этих же технологий 10 Мбайт/c и 80 Мбайт/с соответственно. Сейчас на рынке представлено несколько коммуникационных технологий «гигабитного» уровня. Прежде всего, это Gigabit Ethernet – развитие Fast Ethernet. По соображениям стоимости, производительности и масштабируемости Gigabit Ethernet редко используется в кластерных решениях и обычно предпочтение отдается технологиям Myrinet или SCI. Таблица 1 содержит краткое сравнительное описание технологий Fast Ethernet, SCI, Myrinet, cLAN и ServerNet, используемых в существующих кластерах [1]. Любопытно то, что на современном рынке представлено не так много поставщиков готовых кластерных решений. По всей видимости, это связано с доступностью комплектующих, легкостью построения самих систем, значительной ориентацией на свободно распространяемое ПО, а значит и проблематичностью последующей поддержки со стороны производителя. Среди наиболее известных поставщиков стоит отметить SGI, VALinux и Scali Computer. Летом прошлого года Корнелльским университетом был основан Консорциум по кластерным технологиям (Advanced Cluster Computing Consortium – AC3), основная цель которого – координация работ в области кластерных технологий и помощь в осуществлении разработок в данной области. Ведущими компаниями, обеспечивающими инфраструктуру консорциума, стали Dell, Intel и Microsoft. Среди других членов можно назвать Аргоннскую национальную лабораторию, Нью-Йоркский, Корнелльский и Колумбийский университеты, компании Compaq, Giganet, IBM, Kuck & Associates и другие. Кластерные проекты в РоссииВ России всегда была высока потребность в высокопроизводительных вычислительных ресурсах, и относительно низкая стоимость кластерных проектов послужила серьезным толчком к широкому распространению подобных решений в нашей стране. Одним из первых появился кластер «Паритет», собранный в ИВВиБД и состоящий из восьми процессоров Pentium II, связанных сетью Myrinet. В 1999 году вариант кластерного решения на основе сети SCI был апробирован в НИЦЭВТ, который, по сути дела, и был пионером использования технологии SCI для построения параллельных систем в России. Благодаря Федеральной целевой программе «Интеграция» ожидается появление большого числа высокопроизводительных кластеров в российских образовательных и научно-исследовательских организациях. Это и понятно, поскольку использование высокопроизводительных вычислительных ресурсов жизненно необходимо для получения качественно новых результатов и поддержания выполняемых фундаментальных научных исследований на мировом уровне. Первой ласточкой в этом направлении стал высокопроизводительный кластер на базе коммуникационной сети SCI, установленный в Научно-исследовательском вычислительном центре Московского государственного университета (http://parallel.ru/cluster/). Кластер НИВЦ (рис.4) включает 12 двухпроцессорных серверов «Эксимер» на базе Intel Pentium III/500 МГц, в общей сложности 24 процессора с суммарной пиковой производительностью 12 млрд. операций в секунду. Общая стоимость системы – около 40 тыс. долл. или примерно 3,33 тыс. за 1 GFLOPS. Вычислительные узлы кластера соединены однонаправленными каналами сети SCI в двумерный тор 3x4 и одновременно подключены к центральному серверу через вспомогательную сеть Fast Ethernet и коммутатор 3Com Superstack. Сеть SCI – это ядро кластера, делающее данную систему уникальной вычислительной установкой суперкомпьютерного класса, ориентированной на широкий класс задач. Максимальная скорость обмена данными по сети SCI в приложениях пользователя составляет более 80 Мбайт/с, а время латентности около 5,6 мкс. При построении данного вычислительного кластера использовалось интегрированное решение Wulfkit, разработанное компаниями Dolphin Interconnect Solutions и Scali Computer (Норвегия). Основным средством параллельного программирования на кластере является MPI (Message Passing Interface) версии ScaMPI 1.9.1. На тесте LINPACK при решении системы линейных уравнений с матрицей размера 16000х16000 реально полученная производительность составила более 5,7 GFLOPS. На тестах пакета NPB производительность кластера сравнима, а иногда и превосходит производительность суперкомпьютеров семейства Cray T3E с тем же самым числом процессоров. Основная область применения вычислительного кластера НИВЦ МГУ – это поддержка фундаментальных научных исследований и учебного процесса. Важно отметить, что несмотря на неизбежные затраты на освоение новой вычислительной техники и новых технологий программирования, использование подобных параллельных систем зачастую дает уникальную возможность для получения принципиально новых научных результатов. В этой связи для многих читателей окажутся интересными эмоциональные заметки профессора Д.Д. Соколова «Параллельные вычисления и солнечный ветер: впечатления пользователя», опубликованные им по адресу http://parallel.ru/info/stories/sokolov.html. Из других интересных проектов следует отметить решение, реализованное в Санкт-Петербургском университете на базе технологии Fast Ethernet (http://www.ptc.spbu.ru): собранные кластеры могут использоваться и как полноценные независимые учебные классы, и как единая вычислительная установка, решающая единую задачу. В Самарском научном центре пошли по пути создания неоднородного вычислительного кластера, в составе которого работают компьютеры на базе процессоров Alpha и Pentium III. В Санкт-Петербургском техническом университете собирается установка на основе процессоров Alpha и сети Myrinet без использования локальных дисков на вычислительных узлах. В Уфимском государственном авиационном техническом университете проектируется кластер на базе двенадцати Alpha-станций, сети Fast Ethernet и ОС Linux. Это перечисление можно продолжать и дальше, тем более, что число подобных систем растет очень быстро. Но основная идея понятна: каждый делает те акценты и собирает именно ту конфигурацию, которая лучше отвечает его потребностям, возможностям и желаниям. НапутствиеГоворить про высокопроизводительные кластерные установки можно еще долго: тема актуальная, интересная, переживает этап бурного развития и, что самое замечательное, благодаря доступности каждый сегодня может внести свой реальный вклад в развитие этого направления. Отдельного обсуждения заслуживают темы технологий параллельного программирования и приложений, специализированных прикладных пакетов и базовых библиотек, вопросы эффективности сетевых технологий, безопасности, надежности, масштабируемости, кластеров MOSIX и многие другие. Анализируя аргументы сторонников и противников кластеров сегодня можно с уверенностью констатировать два факта. Ясно то, что с помощью высокопроизводительных кластеров найден эффективный способ решения большого класса задач. Однако ясно и то, что пока кластеры ни в коей мере не являются вычислительной панацеей – у традиционных суперкомпьютеров практически все показатели намного лучше... кроме стоимости. |
![]()