


4.4 Пример параллельной программы с использованием средств PSE
В заключение раздела рассмотрим классический пример программы вычисления числа ![]() на многопроцессорной
системе nCUBE2 с использованием стандартных средств разработки параллельных программ PSE. Для расчета используем формулу:
на многопроцессорной
системе nCUBE2 с использованием стандартных средств разработки параллельных программ PSE. Для расчета используем формулу:
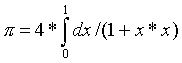 |
(2) |
Интегрирование будем выполнять методом трапеций. Для получения точности 10-8 необходимо интервал разбить на 106 точек. Для начала приведем текст обычной последовательной программы и посмотрим, каким образом ее нужно модифицировать, чтобы получить параллельную версию.
с numerical integration to calculate pi (sequential program)
program calc_pi
integer i, n
double precision w, sum
double precision v
integer np
real*8 time, mflops, time1, dsecnd
c ввод числа точек разбиения интервала
print *, 'Input number of stripes : '
read *, n
np = 1
с включаем таймер
time1 = dsecnd()
w = 1.0 / n
sum = 0.0d0
с основной цикл интегрирования
do i = 1, n
v = (i - 0.5d0 ) * w
v = 4.0d0 / (1.0d0 + v * v)
sum = sum + v
end do
с фиксируем время, затраченное на вычисления
time = dsecnd() - time1
с подсчитываем производительность компьютера в Mflops
mflops = 9 * n / (1000000.0 * time)
print *, 'pi is approximated with ', sum * w
print *, 'time = ', time, ' seconds'
print *, 'mflops = ', mflops, ' on ', np, ' processors'
print *, 'mflops = ', mflops/np, ' for one processor'
end
Это классическая легко распараллеливающаяся задача. Операторы внутри цикла образуют независимые подзадачи, поэтому мы можем выполнять эти подзадачи на различных процессорах. Параллельная версия этой программы с использованием средств PSE выглядит следующим образом:
c numerical integration to calculate pi (parallel program)
program calc_pi
integer i, n
double precision w, gsum, sum
double precision v
integer np, myid, ierr, proc, j, dim, msgtype, maskreal*8 time, mflops, time1, dsecnd
с вызов функции идентификации процессора myid и опроса
c размерности заказанного подкуба dim
c операцию чтения с клавиатуры выполняет только 0-й процессор
print *, 'Input number of stripes : '
read *, n
time1 = dsecnd()
endif
c установка переменных для функции nbroadcast
c рассылка параметра n по всем процессорам
c подсчет заказанного числа процессоров
w = 1.0 / n
sum = 0.0d0
с вычисление частичной суммы на каждом процессоре
do i = myid + 1, n, np
v = (i - 0.5d0 ) * w
v = 4.0d0 / (1.0d0 + v * v)
sum = sum + v
end doc установка переменных для функции dsum
с суммирование частичных сумм с сохранением результата на 0-м
c процессоре
с вывод информации производит только 0-ой процессор
time = dsecnd() - time1
mflops = 9 * n / (1000000.0 * time)
print *, 'pi is approximated with ', gsum * w
print *, 'time = ', time, ' seconds'
print *, 'mflops = ', mflops, ' on ', np, ' processors'
print *, 'mflops = ', mflops/np, ' for one processor'
endifendСредства разработки параллельных программ, входящие в состав PSE, являются типичными для многопроцессорных систем. Те или иные аналоги рассмотренных выше функций можно найти в составе программного обеспечения любой многопроцессорной системы. Как правило, производители многопроцессорных систем включают в программное обеспечение различные варианты коммуникационных библиотек.
Общепризнанным стандартом такой коммуникационной библиотеки сегодня по праву считается MPI, поскольку о его поддержке объявили практически все фирмы-производители многопроцессорных систем и разработчики программного обеспечения для них. Существует несколько бесплатно распространяемых реализаций этой коммуникационной библиотеки:
| MPICH | - разработка Argonne National Laboratory; |
| LAM | - разработка Ohio Supercomputer Center (входит в дистрибутив Linux); |
| CHIMP/MPI | - разработка Edinburgh Parallel Computing Centre. |
На многопроцессорной системе nCUBE2 установлена свободно распространяемая реализация этой библиотеки MPICH, которую мы настоятельно рекомендуем в качестве основного средства разработки параллельных программ. Использование этой коммуникационной библиотеки позволяет:
Опыт работы с этой библиотекой на nCUBE2 показал, что, во-первых, практически не происходит потери производительности, и, во-вторых, не требуется никакой модификации программы при переносе на другую многопроцессорную систему (Linux кластер, 2-х процессорную Alpha DS20E). Технология работы с параллельной программой на nCUBE2 остается той же самой - единственное отличие состоит в том, что при компиляции программы необходимо подключить MPI библиотеку:
ncc -O -o myprog myprog.c -lmpi