
Рис. 5.1.1. Пример OSPF-системы
5.2. Построение базы данных состояния связей
- 5.1.1. Метрики
- 5.1.2. База данных состояния связей
- 5.1.3. Алгоритм SPF
- 5.1.4. Пример работы алгоритма SPF
- 5.1.5. Разграничение хостов и маршрутизаторов
- 5.1.6. Поддержка множественных маршрутов
- 5.1.7. Накладывающиеся маршруты
- 5.1.8. Внешние маршруты
- 5.2.1. Протокол Hello
- 5.2.2. Протокол обмена
- 5.2.3. Протокол затопления (flooding)
Оглавление учебного пособия
Страница курса "Телекоммуникационные технологии"
Кафедра КТС
Протокол маршрутизации OSFP (Open Shortest Path First) представляет собой протокол состояния связей, использующий алгоритм SPF поиска кратчайшего пути в графе. OSPF применяется для внутренней маршрутизации в системах сетей любой сложности.
Рассмотрим работу алгоритма SPF и построение маршрутов на примере системы, изображенной на рис. 5.1.1. Для простоты будем рассматривать OSPF-систему, состоящую только из маршрутизаторов, соединенных линиями связи типа "точка-точка".
Рис. 5.1.1. Пример OSPF-системы
Обозначения на рисунке: ,‚ ,ƒ ,„ - маршрутизаторы; A,B,C,D - линии связи (или просто связи), цифры означают метрику каждой связи.
Метрика представляет собой оценку качества связи в данной сети (на данном физическом канале); чем меньше метрика, тем лучше качество соединения. Метрика маршрута равна сумме метрик всех связей (сетей), входящих в маршрут. В простейшем случае (как это имеет место в протоколе RIP) метрика каждой сети равна единице, а метрика маршрута тогда просто является его длиной в хопах.
Поскольку при работе алгоритма SPF ситуации, приводящие к счету до бесконечности, отсутствуют, значения метрик могут варьироваться в широком диапазоне. Кроме того, протокол OSPF позволяет определить для любой сети различные значения метрик в зависимости от типа сервиса. (Тип сервиса запрашивается дейтаграммой в соответствии со значением поля TOS ее заголовка, см. п. 2.4.) Для каждого типа сервиса будет вычисляться свой маршрут, и дейтаграммы, затребовавшие наиболее скоростной канал, могут быть отправлены по одному маршруту, а затребовавшие наименее дорогостоящий канал - по другому.
Метрика сети, оценивающая пропускную способность, определяется как количество секунд, требуемое для передачи 100 Мбит через физическую среду данной сети. Например, метрика сети на базе 10Base-T Ethernet равна 10, а метрика выделенной линии 56 кбит/с равна 1785. Метрика канала со скоростью передачи данных 100 Мбит/с и выше равна единице.
Порядок расчета метрик, оценивающих надежность, задержку и стоимость, не определен. Администратор, желающий поддерживать маршрутизацию по этим типам сервисов, должен сам назначить разумные и согласованные метрики по этим параметрам.
Если не требуется маршрутизация с учетом типа сервиса (или маршрутизатор ее не поддерживает), используется метрика по умолчанию, равная метрике по пропускной способности.
В нашем примере мы будем использовать метрики, указанные на рисунке, без учета типов сервиса. Следует заметить, что маршрутизация по типам сервиса крайне редка, более того, она исключена из последних версий стандарта OSPF.
Для работы алгоритма SPF на каждом маршрутизаторе строится база данных состояния связей, представляющая собой полное описание графа OSPF-системы. При этом вершинами графа являются маршрутизаторы, а ребрами - соединяющие их связи. Базы данных на всех маршрутизаторах идентичны.
За создание баз данных и поддержку их взаимной синхронизации при изменениях в структуре системы сетей отвечают другие алгоритмы, содержащиеся в протоколе OSPF. Мы рассмотрим эти алгоритмы позже, а сейчас будем считать, что базы данных на всех маршрутизаторах каким-то образом построены, синхронизированы и правильно описывают граф системы в данный момент времени.
База данных состояния связей представляет из себя таблицу, где для каждой пары смежных вершин графа (маршрутизаторов) указано ребро (связь), их соединяющее, и метрика этого ребра. Граф считается ориентированным, то есть ребро, соединяющее вершину с вершиной ‚ , и ребро, соединяющее вершину ‚ с вершиной , могут быть различны или это может быть одно и то же ребро, но с разными метриками.
База данных состояния связей в нашем примере (рис. 5.1.1) выглядит следующим образом:

Алгоритм SPF, основываясь на базе данных состояния связей, вычисляет кратчайшие пути между заданной вершиной S графа и всеми остальными вершинами. Результатом работы алгоритма является таблица, где для каждой вершины V графа указан список ребер, соединяющих заданную вершину S с вершиной V по кратчайшему пути.
Алгоритм SPF был предложен Е.В.Дейкстрой (E.W.Dijkstra).
Пусть
S - заданная вершина (источник путей);
E - множество обработанных вершин, т.е. вершин, кратчайший путь к которым уже найден;
R - множество оставшихся вершин графа (т.е. множество вершин графа за вычетом множества E);
O - упорядоченный список путей.
Описание алгоритма
1. Инициализировать E={S}, R={все вершины графа, кроме S}.
Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S,
отсортировав их в порядке возрастания метрик.
2. Если О пуст или первый путь
в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и
закончить работу алгоритма.
3. Рассмотрим P - кратчайший путь в списке
О. Удалить P из О. Пусть V - последний узел в P.
Если V принадлежит E, перейти на шаг 2;
иначе P является кратчайшим путем из S в V (будем записывать как V:P); перенести V из R в E.
Все вычисления производятся локально по известной базе данных, а потому - быстро по сравнению с дистанционно-векторными протоколами, при этом результаты получаются на основе полной, а не частичной информации о графе системы сетей.
Рассмотрим работу алгоритма на примере базы данных состояния связей рассматриваемой системы.
Возьмем в качестве вершины S маршрутизатор ƒ.
Инициализация
S=ƒ , E={ƒ }, R={ ,‚ ,„ }, O={D,C} (из вершины ƒ согласно базе данных выходят только связи D (к „ ) и С (к ), причем метрика D меньше).
Итерация 1
P=D. Поскольку D ведет от ƒ к „ , то V=„ . Так как V не находится в Е, то кратчайший путь ƒ à „ есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути (шаг 4 алгоритма): согласно базе данных из вершины V=„ существует два односегментных пути: B и D. Добавив их к P=D, получим пути DD и DB с метрикой 2 каждый. Эти пути добавляются в упорядоченный список О.
E={ƒ ,„ }, R={ ,‚ }, O={DD,DB,C}.
Результаты: („ : D)
Итерация 2
P=DD. Двигаясь по этому пути из ƒ , мы попадем опять в ƒ , то есть V=ƒ . Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={ƒ ,„ }, R={ ,‚ }, O={DB,C}.
Результаты: („ : D)
Итерация 3
P=DB. Двигаясь по этому пути из ƒ , мы попадем в , то есть V= . Так как V не находится в Е, то кратчайший путь ƒ à есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути: согласно базе данных из V= существует три односегментных пути: A,В и C. Добавив их к P=DB, получим пути DBA, DBB и DBC с метриками 4,3 и 5 соответственно. Эти пути добавляются в упорядоченный список О.
E={ƒ ,„ , }, R={‚ }, O={C, DBB, DBA, DBC}.
Результаты: („ : D; :DB)
Итерация 4
P=С. V= . Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={ƒ ,„ , }, R={‚ }, O={DBB, DBA, DBC}.
Результаты: („ : D; :DB)
Итерация 5
P=DBB. V=„ . Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={ƒ ,„ , }, R={‚ }, O={DBA, DBC}.
Результаты: („ : D; :DB)
Итерация 6
P=DBA, следовательно V=‚ . Так как V не находится в Е, то кратчайший путь ƒ à ‚ есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути: согласно базе данных из V=‚ существует один односегментный путь A. Добавив его к P=DBА, получим путь DBAА с метрикой 6. Этот путь добавляется в упорядоченный список О.
E={ƒ ,„ , ,‚ }, R={}, O={DBC,DBAA}.
Результаты: („ : D; :DB,‚ :DBA)
Итерации 7 и 8
На этих итерациях из списка О будут удалены оставшиеся пути, так как они ведут к вершинам, уже находящимся в множестве Е, больше никаких изменений не произойдет.
Итерация 9
Так как список О пуст и множество R пусто, то кратчайшие пути из S до всех вершин графа построены, недостижимых вершин нет. Работа алгоритма закончена.
Результатом работы является таблица кратчайших путей от маршрутизатора ƒ до всех остальных маршрутизаторов:
ƒ à :DB
ƒ à ‚ :DBA
ƒ à „ :D
На основе этой информации в узле ƒ строится таблица маршрутов, ведущих ко всем узлам OSPF-системы. Для этого из вышеприведенной таблицы нужно взять первую связь каждого пути. Маршрутизатор, к которому ведет эта связь, будет являться следующим маршрутизатором для данного маршрута. При этом алгоритм SPF гарантирует, что и следующий маршрутизатор построил кратчайшие пути, соответствующие путям маршрутизатора ƒ , т.е. если кратчайший путь из ƒ в ‚ (DBA) лежит через узел „ , в который ведет связь D, то кратчайший путь из „ в ‚ будет ВА.
Таким образом, таблица маршрутов в узле ƒ будет выглядеть:
ƒ à : через „ , линия D
ƒ à ‚ : через „ , линия D
ƒ à „ : через линию D
Выше мы разбирали систему сетей, состоящую только из маршрутизаторов, соединенных двухточечными линиями связи. В этой системе отсутствовали хосты.
Предположим, что к маршрутизатору „ подключена сеть N1 из некоторого количества хостов H1-Hk. Следуя разобранной выше модели, каждый хост должен быть также вершиной графа OSPF-системы, хотя сам и не строит базу данных и не производит вычисления маршрутов. Тем не менее, информация о связях маршрутизатора „ с каждым из хостов сети N1 и о метриках этих связей должна быть внесена в базу данных, чтобы все остальные маршрутизаторы системы могли построить маршруты от себя до этих хостов.
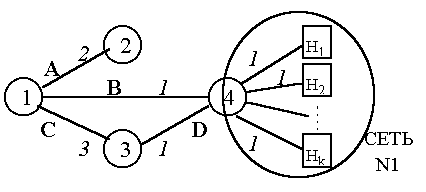
Рис. 5.1.3. OSPF-система с маршрутизаторами и хостами
Очевидно, что такая процедура неэффективна. Вместо информации о связях с каждым хостом в базу данных вносится информация о связи с сетью, то есть сама IP-сеть становится вершиной графа системы, соединенной с маршрутизатором „ с помощью некоторой связи P.

Рис. 5.1.4. OSPF-система с маршрутизаторами и тупиковой сетью
Подчеркнем, что в данном случае сеть, точнее ее адрес, используется как обобщающий идентификатор группы хостов, находящихся в одной IP-сети, к которой маршрутизатор „ непосредственно подключен. Вершина N1 называется тупиковой сетью (stub network); все узлы сети, обозначаемые этой вершиной, являются хостами, у которых установлен маршрут по умолчанию, направленный на маршрутизатор „.
Протокол OSPF производит разграничение хостов и маршрутизаторов. Если к IP-сети N1 подключен еще и один из интерфейсов маршрутизатора ‚ , то связь между ‚ и „ будет установлена отдельно, как если бы они были соединены двухточечной линией связи (при этом у маршрутизатора ‚ также будет связь с тупиковой сетью N1).
При подключении тупиковой сети N1 в базе данных состояния связей появится запись:
| Отàдо | Связь | Метрика |
| „àN1 | P | 1 |
Связей, направленных из вершины N1, в базе данных не будет, потому что вершина N1 не является маршрутизатором. Построение маршрутов до вершины N1 (то есть фактически сразу до всех хоcтов сети N1) будет произведено каждым маршрутизатором обычным способом по алгоритму SPF.
Если между двумя узлами сети существует несколько маршрутов с одинаковыми или близкими по значению метриками, протокол OSPF позволяет направлять части трафика по этим маршрутам в пропорции, соответствующей значениям метрик. Например, если существует два альтернативных маршрута с метриками 1 и 2, то две трети трафика будет направлено по первому из них, а оставшаяся треть - по второму.
Положительный эффект такого механизма заключается в уменьшении средней задержки прохождения дейтаграмм между отправителем и получателем, а также в уменьшении колебаний значения средней задержки.
Менее очевидное преимущество поддержки множественных маршрутов состоит в следующем. Если при использовании только одного из возможных маршрутов этот маршрут внезапно выходит из строя, весь трафик будет разом перемаршрутизирован на альтернативный маршрут, при этом во время процесса массового переключения больших объемов трафика с одного маршрута на другой весьма велика вероятность образования затора на новом маршруте. Если же до аварии использовалось разделение трафика по нескольким маршрутам, отказ одного из них вызовет перемаршрутизацию лишь части трафика, что существенно сгладит нежелательные эффекты.
Рассмотрим теперь следующий пример.

Рис. 5.1.5. Пример особой ситуации при поддержке множественных маршрутов
Узел отправляет данные в ƒ , используя поддержку множественных маршрутов, по маршрутам С (2/3 трафика) и АВ (1/3 трафика). Однако узел ‚ тоже поддерживает механизм множественных путей, и когда к нему пребывают дейтаграммы, адресованные в ƒ (в том числе, и отправленные из ), он применяет к ним ту же логику, то есть 2/3 из них отправляются в ƒ по маршруту В, а одна треть - по маршруту АС. Следовательно, 1/9 дейтаграмм, отправленных узлом в узел ƒ , возвращаются опять в узел , и тот 1/3 из них опять отправляет в ƒ по маршруту С, а 2/3 - по маршруту АВ через узел ‚ и так далее. В итоге сформировался "частичный цикл" при посылке дейтаграмм из в ƒ , который, помимо частичного зацикливания дейтаграмм, ведет к быстрой перегрузке линии А.
Избежать этого явления позволяет следующее правило.
Если узел Х отправляет данные в узел Y, он может пересылать их через узел Q только в том случае, если Q ближе к Y, чем Х.
В разобранном выше примере, следуя этому правилу, не может посылать данные в ƒ через ‚ , поскольку ‚ не ближе к ƒ , чем . Однако такая посылка возможна, если связи между узлами имеют метрики, например, как изображено на следующем рисунке.
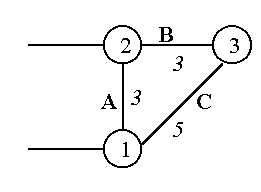
Рис. 5.1.6. Пример корректной ситуации при поддержке множественных маршрутов
Для реализации построения дополнительных альтернативных маршрутов с учетом вышеприведенного правила в алгоритме SPF требуется внести изменения в шаг 3 и добавить шаг 3А. Ниже приводится новая версия алгоритма SPF, в которой изменение и дополнение показаны курсивом.
Алгоритм SPF с поддержкой множественных маршрутов
1. Инициализировать E={S}, R={все вершины графа, кроме S}.
Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S,
отсортировав их в порядке возрастания метрик.
2. Если О пуст или первый путь
в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и
закончить работу алгоритма.
3. Рассмотрим P - кратчайший путь в списке
О. Удалить P из О. Пусть V - последний узел в P.
Если V принадлежит E, перейти на шаг 3А;
иначе P является кратчайшим путем из S в V; перенести V из R в E. Перейти на шаг 4.
Пусть в графе OSPF-системы некий маршрутизатор имеет связи с вершинами N и М, которые представляют сети хостов, подключенные к различным интерфейсам маршрутизатора. Это означает, что в таблице маршрутов этого маршрутизатора, будет две записи: одна для сети N, другая для сети M.
Предположим теперь, что адрес и маска сети М таковы, что она является подсетью сети N. Например, N=172.16.0.0 netmask 255.255.0.0; M=172.16.5.0 netmask 255.255.255.0.
В этом случае дейтаграммы, следующие по адресу, находящемуся в обеих сетях, будут отправлены в сеть с более длинной маской. Например, адрес 172.16.5.1 находится как в сети N, так и в сети М, но маска сети M длиннее, следовательно, дейтаграмма, следующая по этому адресу, будет отправлена в сеть М.
Для достижения сетей, не входящих в OSPF-систему (в автономную систему), используются пограничные маршрутизаторы автономной системы (autonomous system border router, ASBR), имеющие связи, уходящие за пределы системы.
ASBR вносят в базу данных состояния связей данные о сетях за пределами системы, достижимых через тот или иной ASBR. Такие сети, а также ведущие к ним маршруты называются внешними (external).
В простейшем случае, если в системе имеется только один ASBR, он объявляет через себя маршрут по умолчанию (default route) и все дейтаграммы, адресованные в сети, не входящие в базу данных системы, отправляются через этот маршрутизатор.
Если в системе имеется несколько ASBR, то, возможно, внутренним маршрутизаторам системы придется выбирать, через какой именно пограничный маршрутизатор нужно отправлять дейтаграммы в ту или иную внешнюю сеть. Это делается на основе специальных записей, вносимых ASBR в базу данных системы. Эти записи содержат адрес и маску внешней сети и метрику расстояния до нее, которая может быть, а может и не быть сравнимой с метриками, используемыми в OSPF-системе (см. также п. 5.5.12). Если возможно, адреса нескольких внешних сетей агрегируются в общий адрес с более короткой маской.
ASBR может получать информацию о внешних маршрутах от протоколов внешней маршрутизации, а также все или некоторые внешние маршруты могут быть сконфигурированы администратором (в том числе единственный маршрут по умолчанию).
После инициализации модуля OSPF (например, после подачи питания на маршрутизатор) через все интерфейсы, включенные в OSPF-систему, начинают рассылаться Hello-сообщения (формат сообщений см. в п. 5.5.2). Задача Hello-протокола - обнаружение соседей и установление с ними отношений смежности.
Соседями называются OSPF-маршрутизаторы, подключенные к одной сети (к одной линии связи) и обменивающиеся Hello-сообщениями.
Смежными называются соседние OSPF маршрутизаторы, которые приняли решение обмениваться друг с другом информацией, необходимой для синхронизации базы данных состояния связей и построения маршрутов. Не все соседи становятся смежными (этот вопрос будет рассмотрен в пп. 5.3.1, 5.3.4).
Другая задача протокола Hello - выбор выделенного маршрутизатора в сети с множественным доступом, к которой подключено несколько маршрутизаторов (см. пп. 5.3.4, 5.5.2).
Hello-пакеты продолжают периодически рассылаться и после того, как соседи были обнаружены. Таким образом маршрутизатор контролирует состояние своих связей с соседями и может своевременно обнаружить изменение этого состояние (например, обрыв связи или отключение одного из соседей). Обрыв связи может быть также обнаружен и с помощью протокола канального уровня, который просигнализирует о недоступности канала.
В сетях с возможностью широковещательной рассылки (broadcast networks) Hello-пакеты рассылаются по мультикастинговому адресу 224.0.0.5 ("Всем ОSPF-маршрутизаторам"). В других сетях все возможные адреса соседей должны быть введены администратором.
После установления отношений смежности для каждой пары смежных маршрутизаторов происходит синхронизация их баз данных. Эта же операция происходит при восстановлении ранее разорванного соединения, поскольку в образовавшихся после аварии двух изолированных подсистемах базы данных развивались независимо друг от друга. Синхронизация баз данных происходит с помощью протокола обмена (Exchange protocol).
Сначала маршрутизаторы обмениваются только описаниями своих баз данных (Database Description), содержащими идентификаторы записей и номера их версий, это позволяет избежать пересылки всего содержимого базы данных, если требуется синхронизировать только несколько записей (подробнее алгоритм обмена и формат сообщений описан в п. 5.5.3).
Во время этого обмена каждый маршрутизатор формирует список записей, содержимое которых он должен запросить (то есть эти записи в его базе данных устарели либо отсутствуют), и соответственно отправляет пакеты запросов о состоянии связей (Link State Request, см. также п. 5.5.4). В ответ он получает содержимое последних версий нужных ему записей в пакетах типа "Обновление состояния связей (Link State Update)" (см. также п. 5.5.5).
После синхронизации баз данных производится построение маршрутов, как описано в предыдущем разделе.
Каждый маршрутизатор отвечает за те и только те записи в базе данных состояния связей, которые описывают связи, исходящие от данного маршрутизатора. Это значит, что при образовании новой связи, изменении в состоянии связи или ее исчезновении (обрыве), маршрутизатор, ответственный за эту связь, должен соответственно изменить свою копию базы данных и немедленно известить все остальные маршрутизаторы OSPF-системы о произошедших изменениях, чтобы они также внесли исправления в свои копии базы данных.
Подпротокол OSPF, выполняющий эту задачу, называется протоколом затопления (Flooding protocol). При работе этого протокола пересылаются сообщения типа "Обновление состояния связей (Link State Update)" (см. также п. 5.5.5), получение которых подтверждается сообщениями типа "Link State Acknowledgment" (см. также п. 5.5.6).
Каждая запись о состоянии связей имеет свой номер (номер версии), который также хранится в базе данных. Каждая новая версия записи имеет больший номер. При рассылке сообщений об обновлении записи в базе данных номер записи также включается в сообщение для предотвращения попадания в базу данных устаревших версий.
Маршрутизатор, ответственный за запись об изменившейся связи, рассылает сообщение "Обновление состояния связи" по всем интерфейсам. Однако новые версии состояния одной и той же связи должны появляться не чаще, чем оговорено определенной константой.
Далее на всех маршрутизаторах OSPF-системы действует следующий алгоритм.
Протокол OSPF устанавливает также такую характеристику записи в базе данных, как возраст. Возраст равен нулю при создании записи. При затоплении OSPF-системы сообщениями с данной записью каждый маршрутизатор, который ретранслирует сообщение, увеличивает возраст записи на определенную величину. Кроме этого, возраст увеличивается на единицу каждую секунду. Из-за разницы во времени пересылки, в количестве промежуточных маршрутизаторов и по другим причинам возраст одной и той же записи в базах данных на разных маршрутизаторах может несколько различаться, это нормальное явление.
При достижении возрастом максимального значения (60 минут), соответствующая запись расценивается маршрутизатором как просроченная и непригодная для вычисления маршрутов. Такая запись должна быть удалена из базы данных.
Поскольку базы данных на всех маршрутизаторах системы должны быть идентичны, просроченная запись должна быть удалена из всех копий базы данных на всех маршрутизаторах. Это делается с использованием протокола затопления: маршрутизатор затапливает систему сообщением с просроченной записью. Соответственно, в описанный выше алгоритм обработки сообщения вносятся дополнения, связанные с получением просроченного сообщения и удалением соответствующей записи из базы данных.
Чтобы записи в базе данных не устаревали, маршрутизаторы, ответственные за них, должны через каждые 30 минут затапливать систему сообщениями об обновлении записей, даже если состояние связей не изменилось. Содержимое записей в этих сообщениях неизменно, но номер версии больше, а возраст равен нулю.
Вышеописанные протоколы обеспечивают актуальность информации, содержащейся в базе данных состояния связей, оперативное реагирование на изменения в топологии системы сетей и синхронизацию копий базы данных на всех маршрутизаторах системы.
Для обеспечения надежности передачи данных реализован механизм подтверждения приема сообщений, также для всех сообщений вычисляется контрольная сумма.
В протоколе OSPF может быть применена аутентификация сообщений, например, защита их с помощью пароля.