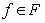 ,
, 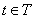 : F R T, где R – нечёткое отношение, которое ставит в соответствие каждой паре элементов
: F R T, где R – нечёткое отношение, которое ставит в соответствие каждой паре элементов  величину функции принадлежности
величину функции принадлежности 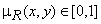 . Набор нечётких отношений R = {r1, r2, ..., rn} определяет словарь эталонов размером n.
. Набор нечётких отношений R = {r1, r2, ..., rn} определяет словарь эталонов размером n.Email: bond005@yandex.ru
Материал взят из электронного сборника трудов II международной научной конференции студентов, аспирантов и молодых учёных «Комп'ютерний моніторинг та інформаційні технології 2006» ( Донецк: ДонНТУ, 2006 )
МЕТОД НЕЧЁТКОГО DTW-СОПОСТАВЛЕНИЯ ОБРАЗОВ ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВЫХ КОМАНД
Рассматривается актуальная проблема создания средств речевой коммуникации между человеком и компьютерными системами. Добавление речевого канала в контур управления сложными человеко-машинными системами позволит значительно повысить эффективность их работы.
В данной статье для разработки речевого канала управления предложен метод нечёткого DTW-сопоставления образов. По сравнению с методом нечёткого сопоставления образов [1] DTW-сопоставление, использующее алгоритм Dynamic Time Warping (DTW) для нелинейной временной нормализации сравниваемых образов [2], позволяет повысить качество распознавания речевых команд. Проведен сравнительный анализ эффективности работы систем распознавания, использующих как нечёткое сопоставление, так и нечёткое DTW-сопоставление образов.
В качестве единиц речи рассматриваются слова, набор которых определяет словарный состав речевого командного интерфейса. Речевой сигнал представляется в виде двумерного спектрального временного образа (СВО), получаемого с помощью оконного преобразования Фурье. СВО позволяет выделить местоположение резонансных частот, т.е. локальных выбросов, что является определяющей особенностью речевого сигнала [1]. На этом основании СВО можно преобразовать к двоичному виду, не теряя указанных информативных признаков речи, с помощью следующей замены: 1 – на месте локального выброса, 0 – в других местах. Полученный образ является двоичным спектральным временным образом (ДСВО) и используется как отражение особенностей речевого сигнала.
Различные реализации речевых образов, относящихся к одному и тому же классу, могут значительно отличаться друг от друга по длительности. Для корректного сопоставления речевых образов необходимо провести их выравнивание по длине. Эта процедура выполнена с помощью нелинейного выравнивания, учитывающего, в отличие от простого линейного выравнивания, неравномерность протекания сигнала во времени [2]. В основу алгоритма нелинейного выравнивания был положен метод DTW [3].
Для распознавания изолированных слов, нормализованных по времени, применялся метод нечёткого сопоставления с эталоном [1]. Эталонные образы для каждого слова словаря формировались как среднее арифметическое ДСВО различных вариантов произношения этого слова. В результате формируется бинарное нечёткое отношение между множеством F (номеров частот f) и множеством T (номеров временных интервалов t) в виде , : F R T, где R – нечёткое отношение, которое ставит в соответствие каждой паре элементов величину функции принадлежности . Набор нечётких отношений R = {r1, r2, ..., rn} определяет словарь эталонов размером n.
Распознаваемый образ y рассматривается как обычное (чёткое) отношение между множеством частот и множеством временных интервалов. Для него вычисляются степени сходства Sj с каждым нечётким отношением rj , и результатом распознавания является номер j слова в словаре, такой, что  , где
, где
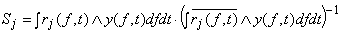 .
.
Были проведены экспериментальные исследования, направленные на определение качества распознавания русских слов по методу нечёткого сопоставления при линейном и нелинейном выравнивании образов. Для эксперимента использовалась речевая однодикторная база данных, включавшая в себя звукозаписи 6 речевых команд управления текстовым процессором. Каждая речевая команда была представлена 30 реализациями, 15 из которых использовались для обучения системы, а 15 – для тестирования.
Результаты распознавания слов тестового множества по методу нечёткого сопоставления представлены в табл. 1, а по методу нечёткого DTW-сопоставления – в табл. 2.
Таблица 1. Результаты тестирования метода нечёткого сопоставления
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Итого, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 14 | 0 | 0 | 1 | 0 | 93,22 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 13 | 0 | 2 | 86,67 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Качество распознавания составило 96,67% | |||||||
Таблица 2. Результаты тестирования метода нечёткого DTW-сопоставления
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Итого, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 15 | 0 | 0 | 0 | 0 | 100,00 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 15 | 0 | 0 | 100,00 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Качество распознавания составило 100,00% | |||||||
В результате исследований установлено, что метод нечёткого сопоставления эффективен для распознавания изолированных слов и словосочетаний русского языка, в том числе речевых команд управления программными системами. Сравнительный анализ линейного выравнивания и выравнивания по методу DTW показал, что второй способ за счёт учёта нелинейности временных изменений речевых образов повышает эффективность метода нечёткого сопоставления при распознавании речевых образов. Полученные результаты позволяют использовать разработанный метод нечёткого DTW-сопоставления для создания систем речевого командного управления.
Список литературы