|
|
Описание параллельного метода
Пусть А и В - квадратные матрицы порядка n, а
p - общее число процессоров. Ниже рассмотрим следующие вопросы:
-
случай p = n2
-
блочная реализация ( p < n2 )
-
пример работы Fox's алгоритма
Случай p = n2
В данном случае получается, что каждому
процессору назначается по одному элементу от каждой из матриц А, В и С. Распределим
элементы матриц между процессорами следующим образом. Процессору с номером
i*n+j ( в дальнейшем процессору (i,j) )
назначим элементы матриц А, В и С, находящиеся в i-той строке и
j-том столбце. Здесь i,j изменяются от 0 до
n-1. В данном частном случае Fox's алгоритм
будет выполнять умножение матриц А и В за n этапов. Примем, что начальный этап
имеет номер 0, а последний этап номер n-1. Тогда на начальном
этапе процессор(i,j) умножает диагональный элемент
ai,i матрицы А на элемент
bi,j матрицы В, а результат умножения
помещает в элемент сi,j
матрицы С:
этап 0 для процессора (i,j):
ci,j = ai,i *
bi,j
Процессор (i,j) будет иметь доступ к элементу
ai,i матрицы А за счет того, что
процессоры обмениваются данными между собой. Вопросы обмена данными будут
рассмотрены позднее.
Перед тем как рассматривать следующий этап, введем понятие деления по модулю n:
i mod n = i, если i < n
i mod n = i % n, если i > = n ( i % n - остаток от деления i на n )
Теперь перейдем непосредственно к рассмотрению следующего этапа.
На первом этапе процессор (i,j) умножает элемент
ai, (i+1) mod n матрицы А на элемент
b(i+1) mod n, j матрицы В. Результат
умножения складывается со значением элемента
ci,j начального этапа, и полученная
сумма снова помещается в элемент
ci,j матрицы С. Следует сказать, что
элемент ai, (i+1) mod n матрицы А - это
элемент, стоящий непосредственно справа от диагонального элемента
ai,i, если i принимает значение от
0 до n-2, и элемент ai, (i+1) mod n равен
элементу ai,0, если i = n-1.
На рисунке элементы ai, (i+1) mod n показаны
для случая, когда n = 4.
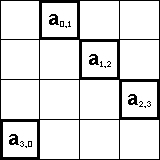
Аналогично элемент b(i+1) mod n, j матрицы В
- это элемент стоящий на одну строчку ниже в отличии от элемента
bi,j этапа 0, если i принимает значение
от 0 до n-2, и элемент b(i+1) mod n, j равен
элементу b0,j, если i = n-1.
этап 1 для процессора (i,j):
ci,j = ci,j +
ai, (i+1) mod n *
b(i+1) mod n, j
В общем случае, во время k-ого этапа процессор (i,j)
выполняет умножение элемента
ai, (i+k) mod n матрицы А на элемент
b(i+k) mod n, j матрицы В, и складывает результат
умножения с элементом
ci,j предыдущего этапа. Обозначим
через k сумму
(i+k) mod n, тогда
этап k для процессора (i,j)
будет выглядеть следующим образом:
этап k для процессора (i,j):
ci,j = ci,j +
ai,k *
bk,j
После выполнения последнего этапа Fox's алгоритма элемент
ci,j будет представляться в виде
следующей суммы:
ci,j =
ai,i * bi,j +
ai,i+1 * bi+1,j +...+
ai,n-1 * bn-1,j +
ai,0 * b0,j +...+
ai,i-1 * bi-1,j
А эта сумма есть ничто иное как сумма произведений элементов i-той
строки матрицы А на элементы j-того столбца матрицы В. Таким
образом, можно сделать вывод о том, что Fox's алгоритм для перемножения
квадратных матриц порядка n и числа процессоров
p = n2
работает правильно.
Блочная реализация ( p < n2 )
Очевидно, что при решении практических задач
требование p = n2 является
трудно выполнимым.
Так, при умножении двух матриц порядка n = 100 уже требуется 10 000
процессоров. Естественным решением проблемы является назначение процессорам
не отдельных элементов, а квадратных подматриц порядка
n/(p1/2) от каждой из матриц A, B и С.
В этом случае Fox's алгоритм будет выполнять умножение матриц А и В за
p1/2 этапов. На каждом этапе
процессор (i,j) будет получать подматрицу
Ci,j, формула для вычисления которой
имеет вид, аналогичный формуле для вычисления элемента
сi,j матрицы С, с той лишь разницей,
что вместо элементов
ai,j и
bi,j следует использовать подматрицы
Ai,j и
Bi,j и i,j будут изменяться
от 0 до p1/2 - 1.
В этом случае этап k для процессора (i,j)
будет иметь следующий вид:
этап k для процессора (i,j):
Ci,j = Ci,j +
Ai,k *
Bk,j
Единственной проблемой при таком подходе является отсутствие какой либо
гарантии в том, что n/(p1/2) будет
целым числом. Основная сложность состоит в неизвестности порядка матриц n,
т.к. p1/2 можно
сделать целым числом, если из общего числа процессоров взять только то число, из
которого извлекается корень, а оставшиеся процессоры будут просто неработающими.
Трудности, связанные с порядком матриц могут быть преодолены за счет
введения недостающих строк и столбцов, заполненных нулевыми элементами.
В дальнейшем будем полагать, что
n/(p1/2) - целое число.
Пример работы Fox's алгоритма
Рассмотрим работу Fox's алгоритма на примере
умножения матриц 6-го порядка
на 9-ти процессорах, то есть n=6, а p=9. В этом случае
каждому процессору назначается подматрица порядка
n/(p1/2) = 2 от каждой из матриц
А, В и С и Fox's алгоритм выполняет умножение матриц за
p1/2 = 3 этапа:
Этап 0 ( шаг 1 ( слева ), шаг 2 ( по центру ), шаг 3 ( справа ) ):
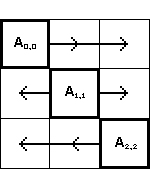
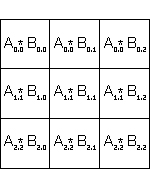
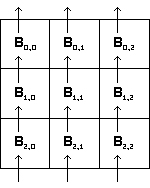 На начальном этапе происходит рассылка
подматриц
Ai,i,
стоящих на главной диагонали, процессорам, работающим с подматрицами в той же
строке. Далее на каждом процессоре происходит умножение полученной диагональной
подматрицы
Ai,i на подматрицу
Bi,j, хранящуюся на данном процессоре.
Результат умножения помещается в подматрицу
Ci,j
процессора (i,j). Здесь i,j изменяются от 0 до 2. Перед переходом
к следующему этапу происходит перемещение подматрицы
Bi,j от процессора (i,j) к
процессору (i-1,j), то есть к непосредственно "верхнему" процессору.
Процессоры нулевой строки посылают подматрицы
B0,j
процессорам последней ( в данном случае второй ) строки.
На начальном этапе происходит рассылка
подматриц
Ai,i,
стоящих на главной диагонали, процессорам, работающим с подматрицами в той же
строке. Далее на каждом процессоре происходит умножение полученной диагональной
подматрицы
Ai,i на подматрицу
Bi,j, хранящуюся на данном процессоре.
Результат умножения помещается в подматрицу
Ci,j
процессора (i,j). Здесь i,j изменяются от 0 до 2. Перед переходом
к следующему этапу происходит перемещение подматрицы
Bi,j от процессора (i,j) к
процессору (i-1,j), то есть к непосредственно "верхнему" процессору.
Процессоры нулевой строки посылают подматрицы
B0,j
процессорам последней ( в данном случае второй ) строки.
Этап 1 ( слева ) и этап 2 ( справа ):
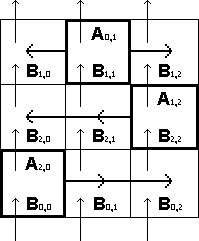
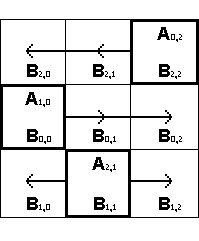
На первом этапе также происходит рассылка,
но только уже подматриц
Ai,(i+1) mod q, где q =
p1/2 = 3, а i изменяется от 0 до 2.
То есть процессоры нулевой, первой и второй строк получат подматрицы
A0,1,
A1,2 и
A2,0 соответственно. Далее на каждом
процессоре происходит умножение полученной подматрицы
Ai,(i+1) mod 3 на подматрицу
Bi,j, полученную на предыдущем этапе
от процессора непосредственно
нижней строки. Результат умножения складывается с подматрицей
Сi,j и снова в нее записывается. Перед
переходом к следующему этапу снова происходит восходящее перемещение подматриц
Bi,j, аналогичное их перемещению на
этапе 0.
Второй ( и в данном случае последний ) этап работы
Fox's алгоритма полностью аналогичен предыдущим этапам и может быть
описан следующей последовательностью шагов:
-
рассылка подматрицы
Ai,(i+2) mod 3
процессорам i-той строки ( на рисунке эти подматрицы
выделены )
-
умножение на процессоре (i,j) подматриц
Ai,(i+2) mod 3 и
Bi,j ( Понятно, что в общем
случае, подматрицы
Bi,j на данном этапе и
предыдущем не совпадают )
-
Ci,j =
Ci,j +
Ai,(i+2) mod 3 *
Bi,j
Заметим также, что перемещение подматриц
Bi,j на последнем этапе является
излишним. После заключительного этапа мы получим 9 подматриц
Сi,j, которые будут составлять
матрицу С, являющуюся решением данной задачи.
|