А.Д. Жидких, В.И. Костин
Доклад опубликован в сборнике конференции "Компьютерный мониторинг и информационные технологии", которая проходила в ДонНТУ 15 декабря 2005 года.
В наше время актуальной является тема фильтрования текстовых данных. Например, в цензурировании web-форумов, удалении повторных сообщений, отправленных злоумышленником для перегрузки системы, которая может привести к некорректной работе этой системы, также фильтрация текста может использоваться в электронных словарях, чтобы перевести заданное предложение, в соответствии с контекстом, а не вывести почти бессвязный набор слов и фраз.
Существуют различные способы решения данной проблемы, и, в основном, они сводятся к задачам текстового поиска и ассоциативному мышлению.
В данном докладе рассматриваются задачи анализа строк, возникающие при обработке текстовой информации - обзор существующих алгоритмов. Термин анализ строк используется здесь в довольно общем смысле и обозначает целый класс задач – выделение совпадающих подстрок двух строк[2].
В обобщенной задаче требуется локализовать все вхождения образца в текст. Алгоритмы, решающие основную задачу, легко распространить на обобщенную.
В ходе работы были рассмотрены алгоритмы:
• Наивный подход;
• Кнута-Морриса-Пратта;
• Бойера-Мура;
• Бойера-Мура-Хорспула;
• Сандея;
• Хьюма и Сандея;
• Харрисона;
• Карпа и Рабина.
Из анализа данных алгоритмов были сделаны выводы об относительной эффективности[1]:
• алгоритм Бойера-Мура-Хорспула является наилучшим;
• эффективность Хорспула, приблизительно, равен исходному алгоритму Бойера-Мура, но лучше, чем наивный подход;
• алгоритм Кнута-Морриса-Пратта не дает на практике значительного преимущества в скорости к наивному подходу, и алгоритм Бойера-Мура.
• Метод Карпа-Рабина сильно уступает остальным.
• Вариант Сандея (быстрый поиск) совместно с упрощенным алгоритмом Бойера-Мура очень эффективен.
• Хьюм и Сандей более эффективны по сравнению с исходным алгоритмом Бойера-Мура,но они не учитывают громоздких и медленных предварительные вычислений.
Рассмотрим максимально эффективные алгоритмы поиска:
1.Алгоритм Бойера-Мура-Хорспула.
В его основе – идея: если полнее использовать информацию, получаемую в процессе поиска, то можно избежать возвратов при несовпадении. Текстовая строка последовательно просматривается слева направо. Если попытка сопоставления потерпела неудачу на одном из символов, то предыдущие символов текста нам известны: они содержатся в массиве. Этот факт, конечно, желательно использовать, чтобы определить величину шага вправо, то есть смещение для следующей попытки сопоставления с образцом. Смещения содержатся в другой таблице. При количестве просмотров:
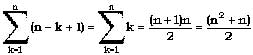
, где n –длина последовательности, k – количество символов в шаблоне (1..n). При k=const – вычисляется (n-k+1)
Этот метод хорошо работает для образцов и текстов с большим количеством повторов. Пирклбауер предложил вариант алгоритма Кнута-Морриса-Пратта, в котором сопоставления образца и текста производятся справа налево. Средняя эффективность увеличилась, однако анализ входного текста перестал быть строго последовательным.
2. Быстродействие алгоритма Бойера-Мура
Скорость в алгоритме Бойера-Мура достигается за счет того, что пропускаются те части текста, которые заведомо не участвуют в успешном сопоставлении.
В алгоритме Бойера-Мура образец движется вдоль строки текста слева направо, однако фактические сравнения символов выполняются справа налево. Первыми, таким образом, сравниваются символы xk и yk., где х – шаблон, а y – строка. Если они не совпадают и yk не встречается нигде в x, мы можем спокойно сдвинуть образец на k символов вправо, так как можем быть уверены, что ни одна из начинающихся с одной из первых k позиций подстрок не совпадает с образцом. Следующими сравниваются xk и y2k.Пусть отвергающими оказались символы xk и yi ., где i – индекс строки. Как уже говорилось, если yi не содержится нигде в образце, шаблон можно сдвинуть на k позиций вправо. С другой стороны, если yi присутствует в образце, и xk-s (где s – количество сравненных символов х с y i) – его самое правое вхождение, то образец можно сдвинуть лишь на s позиций вправо, совмещая xk-s с yi. Проверку можно продолжить сравнением xk с yi+s, то есть текстовый индекс мы увеличиваем на s.
Сандей предложил использовать символ, находящийся в тексте непосредственно за неодинаковым символом. Он разработал алгоритм Быстрый поиск (Quick Search) сравнения производятся слева направо.Он обнаружил, что в алгоритме Бойера-Мура при обнаружении несовпадения, когда xk совмещен с i-м символом текста, для сопоставления вместо yi можно использовать следующий символ, то есть yi+1. Основанием для этого является то, что при минимальном сдвиге образца, то есть на один символ вправо, yi+1 является частью следующей проверяемой подстроки текста.
Об ассоциативном мышлении[3]:
Проблема -сложность точной формулировки запроса программы (подбор ключевых словосочетаний, которые предстоит искать в текстах). Это может быть связано с рядом причин: недостаточным знанием пользователем терминологии предметной области, наличием в языке синонимичных слов, различного контекста, и орфографических ошибок в написании искомых слов, которые могут встречаться в текстах. Помощь в решении данных проблем - технологии, предназначенных для автоматического анализа содержания текстовых документов и выявления основных смысловых единиц, работа с которыми призвана облегчить процессы поиска информации. Выявление смысловых структур, в сжатом описывающих содержание материала, основано на модели механизмов обработки информации правым полушарием человеческого мозга (развивать ассоциации между связанными событиями и закреплять рефлексы путем повторений). О подходе: В основе процедур, используемых для анализа документов, лежит представление смысла текста в форме семантической сети. Семантическая сеть — это множество понятий, связанных между собой. В семантическую сеть включаются более часто встречающиеся слова текста, которые несут основную смысловую нагрузку. Для каждого понятия формируется набор ассоциативных связей. Считается, что частота встреч понятий в предложениях текста, прямо пропорционально вероятности связи по смыслу.
Литература
1. Ахо А.В. (1990) "Алгоритмы для поиска подобных строк" ESP, Amsterdam.
2. Пилкбауэр К.(1992) "Обучение примерно похожим алгоритмам" SP, NY.
3. http://www.3ka.mipt.ru/vlib/books/Programming/ComputerScience/StryngAnalysis


