|
Источник: М.Федосеев. Экономико-математические методы и прикладные модели. -М.: ЮНИТИ, 1999.-391с. -с.187-228.
МЕТОД ЭКСТРАПОЛЯЦИИ НА ОСНОВЕ КРИВЫХ РОСТА
Основная цель создания трендовых моделей экономической динамики — на их основе сделать прогноз о развитии изучаемого процесса на предстоящий промежуток времени. Прогнозирование на основе временого ряда экономических показателей относится к одномерным методам прогнозирования, базирующимся на экстраполяции, т.е. на продлении на будущее тенденции, наблюдавшейся в прошлом. При таком подходе предполагается, что прогнозируемый показатель формируется под воздействием большого количества факторов, выделить которые либо невозможно, либо по которым отсутствует информация. В этом случае ход изменения данного показателя связывают не с факторами, а с течением времени, что проявляется в образовании одномерных временных рядов. Рассмотрим метод экстраполяции на основе так называемых кривых роста экономической динамики. В настоящее время насчитывается большое количество типов кривых роста для экономических процессов. Чтобы правильно подобрать наилучшую кривую роста для моделирования и прогнозирования экономического явления, необходимо знать особенности каждого вида кривых. Наиболее часто в экономике используются полиномиальные, экспоненциальные и S-образные кривые роста. 1) полиномиальные кривые роста имеют вид полинома k-й степени: 2) экспоненциальные кривые роста предполагают, что дальнейшее развитие зависит от достигнутого уровня, например, прирост зависит от значения функции. В экономике чаще всего применяются две разновидности экспоненциальных (показательных) кривых: - простая экспонента, которая представляется в виде функции - модифицированная экспонента имеет вид Для моделирования процессов, которые сначала растут медленно, затем ускоряются, а затем снова замедляют свой рост, стремясь к какому-либо пределу, используются так называемые S-образные кривые роста, среди которых выделяют кривую Гомперца и логистическую кривую. 3)кривая Гомперца имеет аналитическое выражение В кривой Гомперца выделяются четыре участка: на первом — прирост функции незначителен, на втором — прирост увеличивается, на третьем участке прирост примерно постоянен, на четвертом — происходит замедление темпов прироста и функция неограниченно приближается к значению к. В результате конфигурация кривой напоминает латинскую букву S.
4)логистическая кривая, или кривая Перла—Рида — возрастающая функция, наиболее часто выражаемая в виде В этих выражениях а и b — положительные параметры; k — предельное значение функции при бесконечном возрастании времени. Конфигурация графика логистической кривой близка графику кривой Гомперца, но в отличие от последней логистическая кривая имеет точку симметрии, совпадающую с точкой перегиба. Рассмотрим проблему предварительного выбора вида кривой роста для конкретного временного ряда. Допустим, имеется временной ряд y1,y2,у3,...,yп.. Для выбора вида полиномиальной кривой роста наиболее распространенным методом является метод конечных разностей (метод Тинтнера). Этот метод может быть использован для предварительного выбора полиномиальной кривой, если, во-первых, уровни временного ряда состоят только из двух компонент: тренд и случайная компонента, и во-вторых, тренд является достаточно гладким, чтобы его можно было аппроксимировать полиномом некоторой степени.
На первом этапе этого метода вычисляются разности (приросты) до k-го порядка включительно: Затем для исходного ряда и для каждого разностного ряда вычисляются дисперсии по следующим формулам:
для исходного ряда: Производится сравнение отклонений каждой последующей дисперсии от предыдущей, т.е. вычисляются величины Более универсальным методом предварительного выбора кривых роста, позволяющим выбрать кривую из широкого класса кривых роста, является метод характеристик прироста. Он основан на использовании отдельных характерных свойств кривых, рассмотренных выше. При этом методе исходный временной ряд предварительно сглаживается методом простой скользящей средней: Затем вычисляются первые и вторые средние приросты:
А также ряд производных величин, связанных с вычисленными средними приростами и сглаженными уровнями ряда: В соответствии с характером изменения средних приростов и производных показателей выбирается вид кривой роста для исходного временного ряда, при этом используется специальная таблица.
Рассмотрим методы определения параметров отобранных кривых роста. Параметры полиномиальных кривых оцениваются, как правило, методом наименьших квадратов, суть которого заключается в том, чтобы сумма квадратов отклонений фактических уровней ряда от соответствующих выровненных по кривой роста значений была наименьшей. Этот метод приводит к системе так называемых нормальных уравнений, которая для полинома k-го порядка имеет вид: Параметры экспоненциальных и S-образных кривых находятся более сложными методами. Для простой экспоненты предварительно логарифмируют выражение по некоторому основанию (например, десятичному или натуральному): При определении параметров кривых роста, имеющих асимптоты (модифицированная экспонента, кривая Гомперца, логистическая кривая), различают два случая. Если значение асимптоты k известно заранее, то путем несложной модификации формулы и последующего логарифмирования определение параметров сводят к решению системы нормальных уравнений, неизвестными которой являются логарифмы параметров кривой. Если значение асимптоты заранее неизвестно, то для нахождения параметров указанных выше кривых роста используются приближенные методы: метод трех точек, метод трех сумм и др. Таким образом, при моделировании экономической динамики, заданной временным рядом, путем сглаживания исходного ряда, определения наличия тренда, отбора одной или нескольких кривых роста и определения их параметров в случае наличия тренда получают одну или несколько трендовых моделей для исходного временного ряда. Встает вопрос, насколько эти модели близки к экономической реальности, отраженной во временном ряду, насколько обосновано применение этих моделей для анализа и прогнозирования изучаемого экономического явления. То есть на следующем этапе необходима оценка адекватности и точности трендовых моделей. Трендовая модель конкретного временного ряда yt считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента et= Проверка случайности колебаний уровней остаточной последовательности означает проверку гипотезы о правильности выбора вида тренда. Характер этих отклонений изучается с помощью ряда непараметрических критериев. Одним из таких критериев является критерий серий, основанный на медиане выборки. Ряд из величин et располагают в порядке возрастания их значений и находят медиану em полученного вариационного ряда. Возвращаясь к исходной последовательности et и сравнивая значения этой последовательности с em, ставят знак «плюс», если значение et превосходит медиану, и знак «минус», если оно меньше медианы; в случае равенства сравниваемых величин соответствующее значение et опускается. Последовательность подряд идущих плюсов или минусов называется серией. Для того чтобы последовательность et была случайной выборкой, протяженность самой длинной серии не должна быть слишком большой, а общее число серий — слишком малым. Обозначим протяженность самой длинной серии через Кmaх , а общее число серий — через v. Выборка признается случайной, если выполняются следующие неравенства для 5%-ного уровня значимости:
Если хотя бы одно из этих неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая модель признается неадекватной. Другим критерием для данной проверки может служить критерий пиков (поворотных точек). Уровень последовательности et считается максимумом, если он больше двух рядом стоящих уровней, т.е. et-1< et > et+l, и минимумом, если он меньше обоих соседних уровней, т.е. et-1 > et < et+l. В обоих случаях ?t считается поворотной точкой; общее число поворотных точек для остаточной последовательности ?t обозначим через р. В случайной выборке математическое ожидание числа точек поворота р и дисперсия выражаются формулами: Расчетное значение этого критерия задается формулой Проверка независимости значений уровней случайной компоненты, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности может осуществляться по ряду критериев, наиболее распространенным из которых является d-критерий Дарбина—Уотсона. Расчетное значение этого критерия определяется по формуле Расчетное значение критерия Дарбина-Уотсона в интервале от 2 до 4 свидетельствует об отрицательной связи: в этом случае его надо преобразовать по формуле d'=4-d и в дальнейшем использовать значение d'. Расчетное значение критерия d (или d') сравнивается с верхним d2 и нижним d1 критическими значениями статистики Дарбина—Уотсона, значения которых для различного числа уровней ряда п и числа определяемых параметров модели k для заданного уровня значимости имеются в специальных таблицах. Если расчетное значение критерия d больше верхнего табличного значения d2, то гипотеза о независимости уровней остаточной последовательности, принимается. Если значение d меньше нижнего табличного значения d1, то эта гипотеза отвергается, и модель неадекватна. Если значение d находится между значениями d1и d2, включая сами эти значения, то считается, что нет достаточных оснований сделать тот или иной вывод и необходимы дальнейшие исследования, например, по большему числу наблюдений. Вывод об адекватности трендовой модели делается, если все указанные выше четыре проверки свойств остаточной последовательности дают положительный результат. Для адекватных моделей имеет смысл ставить задачу оценки их точности. Точность модели характеризуется величиной отклонения выхода модели от реального значения моделируемой переменной (экономического показателя). Для показателя, представленного временным рядом, точность определяется как разность между значением фактического уровня временного ряда и его оценкой, полученной расчетным путем с использованием модели, при этом в качестве статистических показателей точности применяются среднее квадратическое отклонение На основании указанных показателей можно сделать выбор из нескольких адекватных трендовых моделей экономической динамики наиболее точной, хотя может встретиться случай, когда по некоторому показателю более точна одна модель, а по другому — другая. Данные показатели точности моделей рассчитываются на основе всех уровней временного ряда и поэтому отражают лишь точность аппроксимации. Для оценки прогнозных свойств модели целесообразно использовать так называемый ретроспективный прогноз — подход, основанный на выделении участка из ряда последних уровней исходного временного ряда в количестве, допустим, n2 уровней в качестве проверочного, а саму трендовую модель в этом случае следует строить по первым точкам, количество которых будет равно n1 = n - n2. Тогда для расчета показателей точности модели по ретроспективному прогнозу применяются те же формулы, но суммирование в них будет вестись не по всем наблюдениям, а лишь по последним n2 наблюдениям. Оценивание прогнозных свойств модели на ретроспективном участке весьма полезно, особенно при сопоставлении различных моделей прогнозирования из числа адекватных. Однако надо помнить, что оценки ретропрогноза — лишь приближенная мера точности прогноза и модели в целом, так как прогноз на период упреждения делается по модели, построенной по всем уровням ряда. Прогнозирование экономических показателей на основе трендовых моделей, как и большинство других методов экономического прогнозирования, основано на идее экстраполяции. Под экстраполяцией обычно понимают распространение закономерностей, связей и соотношений, действующих в изучаемом периоде, за его пределы. При экстраполяционном прогнозировании экономической динамики на основе временных рядов с использованием трендовых моделей выполняются следующие основные этапы: 1) предварительный анализ данных; 2) формирование набора моделей, называемых функциями-кандидатами; 3) численное оценивание параметров моделей 4) определение адекватности моделей; 5) оценка точности адекватных моделей; 6) выбор лучшей модели; 7) получение точечного и интервального прогнозов; 8) верификация прогноза. Прогноз на основании трендовых моделей (кривых роста) содержит два элемента: точечный и интервальный прогнозы. Точечный прогноз — это прогноз, которым называется единственное значение прогнозируемого показателя. Это значение определяется подстановкой в уравнение выбранной кривой роста величины времени t, соответствующей периоду упреждения: t=n+1; t=n+2 и т. д. Очевидно, что точное совпадение фактических данных в будущем и прогностических точечных оценок маловероятно. Поэтому точечный прогноз должен сопровождаться двусторонними границами, т.е. интервальным прогнозом. Интервальный прогноз на базе трендовых моделей осуществляется путем расчета доверительного интервала — такого интервала, в котором с определенной вероятностью можно ожидать появления фактического значения прогнозируемого экономического показателя. Методы, разработанные для статистических совокупностей, позволяют определить доверительный интервал, зависящий от стандартной ошибки оценки прогнозируемого показателя, от времени упреждения прогноза, от количества уровней во временном ряду и от уровня значимости (ошибки) прогноза. Величина доверительного интервала определяется в общем виде следующим образом: Увеличение неопределенности прогнозируемого процесса с ростом периода упреждения проявляется в постоянном расширении доверительного интервала. При экстраполяционном прогнозировании экономической динамики с использованием трендовых моделей весьма важным является заключительный этап — верификация прогноза. Верификация прогнозной модели представляет собой совокупность критериев, способов и процедур, позволяющих на основе многостороннего анализа оценивать качество получаемого прогноза. На практике не всегда удается сразу построить достаточно хорошую модель прогнозирования, поэтому описанные в данной главе этапы построения трендовых моделей экономической динамики выполняются неоднократно. |
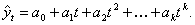 Полиномиальные кривые роста можно использовать для аппроксимации (приближения) и прогнозирования экономических процессов, в которых последующее развитие не зависит от достигнутого уровня.
Полиномиальные кривые роста можно использовать для аппроксимации (приближения) и прогнозирования экономических процессов, в которых последующее развитие не зависит от достигнутого уровня.
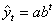 ,
где а и b — положительные числа, при этом если b>1, то функция возрастает с ростом времени t, если b<1 — функция убывает.
,
где а и b — положительные числа, при этом если b>1, то функция возрастает с ростом времени t, если b<1 — функция убывает.
 , где постоянные величины: а<0, b положительна и меньше единицы, а константа k носит название асимптоты этой функции, т.е. значения функции неограниченно приближаются (снизу) к величине k.
, где постоянные величины: а<0, b положительна и меньше единицы, а константа k носит название асимптоты этой функции, т.е. значения функции неограниченно приближаются (снизу) к величине k.
 , где а, b — положительные параметры, причем b меньше единицы; параметр k — асимптота функции.
, где а, b — положительные параметры, причем b меньше единицы; параметр k — асимптота функции.
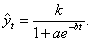 .
другие виды этой кривой:
.
другие виды этой кривой:  ;
; 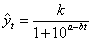 .
.
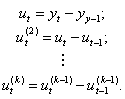
 для разностного ряда k-гo порядка (k = 1, 2,...):
для разностного ряда k-гo порядка (k = 1, 2,...):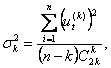 где
где 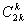 - биномиальный коэффициент.
- биномиальный коэффициент.
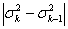 , и если для какого-либо k эта величина не превосходит некоторой наперед заданной положительной величины, т.е. дисперсии одного порядка, то степень аппроксимирующего полинома должна быть равна k - 1.
, и если для какого-либо k эта величина не превосходит некоторой наперед заданной положительной величины, т.е. дисперсии одного порядка, то степень аппроксимирующего полинома должна быть равна k - 1.
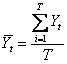 .
.
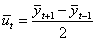 ,
, 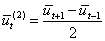 , t=2,3,…,n-1.
, t=2,3,…,n-1.
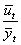 ;
; 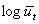 ;
; 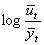 ;
; 

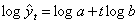 , т.е. для логарифма функции получают линейное выражение, а затем для неизвестных параметров log а и log b составляют на основе метода наименьших квадратов систему нормальных уравнений, аналогичную системе для полинома первой степени. Решая эту систему, находят логарифмы параметров, а затем и сами параметры модели.
, т.е. для логарифма функции получают линейное выражение, а затем для неизвестных параметров log а и log b составляют на основе метода наименьших квадратов систему нормальных уравнений, аналогичную системе для полинома первой степени. Решая эту систему, находят логарифмы параметров, а затем и сами параметры модели.
 -yt (t=1,2,...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
-yt (t=1,2,...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
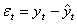 (t=1,2,…n).
(t=1,2,…n).
 , где квадратные скобки означают целую часть числа.
, где квадратные скобки означают целую часть числа.
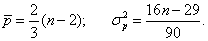 . Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства
. Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства 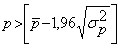 . Если это неравенство не выполняется, трендовая модель считается неадекватной.
Проверка соответствия распределения случайной компоненты нормальному закону распределения может быть произведена с помощью метода Вестергарда, RS-критерия и т. д. RS-критерий численно равен отношению размаха вариации случайной величины R к стандартному отклонению S. Значение RS-критерия сравнивается с табличными (критическими) нижней и верхней границами данного отношения, и если это значение не попадает в интервал между критическими границами, то с заданным уровнем значимости гипотеза о нормальности распределения отвергается; в противном случае эта гипотеза принимается.
Проверка равенства математического ожидания случайной компоненты нулю, если она распределена по нормальному закону, осуществляется на основе t-критерия Стьюдента.
. Если это неравенство не выполняется, трендовая модель считается неадекватной.
Проверка соответствия распределения случайной компоненты нормальному закону распределения может быть произведена с помощью метода Вестергарда, RS-критерия и т. д. RS-критерий численно равен отношению размаха вариации случайной величины R к стандартному отклонению S. Значение RS-критерия сравнивается с табличными (критическими) нижней и верхней границами данного отношения, и если это значение не попадает в интервал между критическими границами, то с заданным уровнем значимости гипотеза о нормальности распределения отвергается; в противном случае эта гипотеза принимается.
Проверка равенства математического ожидания случайной компоненты нулю, если она распределена по нормальному закону, осуществляется на основе t-критерия Стьюдента. 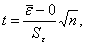 , где
, где 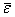 - среднее арифметическое значение уровней остаточной последовательности,
- среднее арифметическое значение уровней остаточной последовательности, 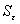 - стандартное отклонение для этой последовательности. Если расчетное значение t меньше табличного значения t статистики Стьюдента с заданным уровнем значимости a и числом степеней свободы n-1, то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается; в противном случае эта гипотеза отвергается и модель считается неадекватной.
- стандартное отклонение для этой последовательности. Если расчетное значение t меньше табличного значения t статистики Стьюдента с заданным уровнем значимости a и числом степеней свободы n-1, то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается; в противном случае эта гипотеза отвергается и модель считается неадекватной.
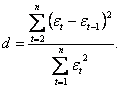
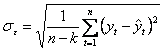 ;
средняя относительная ошибка
;
средняя относительная ошибка 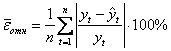 ;
коэффициент сходимости
;
коэффициент сходимости 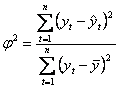 ;
коэффициент детерминации
;
коэффициент детерминации  ,
где
,
где 
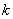 -количество уровней ряда,
-количество уровней ряда, 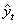 -число параметров модели, -оценка уровней ряда модели,
-число параметров модели, -оценка уровней ряда модели,  -среднее арифметическое значений уровней ряда.
-среднее арифметическое значений уровней ряда.
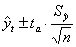 , где
, где 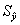 - среднее квадратическое отклонение от тренда;
- среднее квадратическое отклонение от тренда; 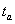 - табличное значение t-критерия Стьюдента при уровне значимости a(%) и числе степеней свободы n-k.
- табличное значение t-критерия Стьюдента при уровне значимости a(%) и числе степеней свободы n-k.