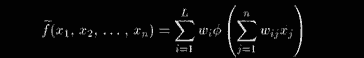Обучение, применение и эффективность нейронных сетей
Источник: Круглов В.В., Дли М.И, ФИЗМАТЛИТ (Издательство Физико-математической литературы), 2001, стр.60-62,78-80,100-102.
Обучение нейронных сетей
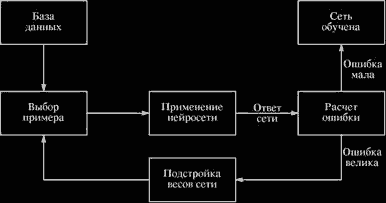
Обучить нейросеть — значит, сообщить ей, чего мы от нее добиваемся. Этот процесс очень похож на обучение ребенка алфавиту. Показав ребенку изображение буквы «А», мы спрашиваем его: «Какая это буква?» Если ответ неверен, мы сообщаем ребенку тот ответ, который мы хотели бы от него получить: «Это буква А». Ребенок запоминает этот пример вместе с верным ответом, т.е. в его памяти происходят некоторые изменения в нужном направлении. Мы будем повторять процесс предъявления букв снова и снова до тех пор, когда все буквы будут твердо запомнены. Такой процесс называют «обучение с учителем» (рис. 2.7).
При обучении сети мы действуем совершенно аналогично. У нас имеется некоторая база данных, содержащая примеры (набор рукописных изображений букв).
Рис. 2.7. Иллюстрация процесса обучения НС
Предъявляя изображение буквы «А» на вход сети, мы получаем от нее некоторый ответ, не обязательно верный. Нам известен и верный (желаемый) ответ — в данном случае нам хотелось бы, чтобы на выходе с меткой «А» уровень сигнала был максимален. Обычно в качестве желаемого выхода в задаче классификации берут набор (1, 0, 0,...), где 1 стоит на выходе с меткой «А», а 0 — на всех остальных выходах. Вычисляя разность между желаемым ответом и реальным ответом сети, мы получаем (для букв русского алфавита) 33 числа — вектор ошибки. Алгоритм обучения — это набор формул, который позволяет по вектору ошибки вычислить требуемые поправки для весов сети. Одну и ту же букву (а также различные изображения одной и той же буквы) мы можем предъявлять сети много раз. В этом смысле обучение скорее напоминает повторение упражнений в спорте — тренировку.
Оказывается, что после многократного предъявления примеров веса сети стабилизируются, причем сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что «сеть выучила все примеры», «сеть обучена», или «сеть натренирована». В программных реализациях можно видеть, что в процессе обучения функция ошибки (например, сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда функция ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную сеть считают натренированной и готовой к применению на новых данных.
Важно отметить, что вся информация, которую сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу. Так, например, бессмысленно использовать сеть для предсказания финансового кризиса, если в обучающей выборке кризисов не представлено. Считается, что для полноценной тренировки требуется хотя бы несколько десятков (а лучше сотен) примеров.
Математически процесс обучения можно описать следующим образом.
В процессе функционирования нейронная сеть формирует выходной сигнал Y в соответствии с входным сигналом X, реализуя некоторую функцию Y = G ( X ). Если архитектура сети задана, то вид функции G определяется значениями синаптических весов и смещений сети.
Пусть решением некоторой задачи является функция Y = = F ( X ), заданная парами входных-выходных данных ( X 1, Y 1 ), ( X 2, Y 2 ),..., ( X N, Y N ), для которых Y fc = F ( X fc ) ( k = 1, 2,....... TV ).
Обучение состоит в поиске (синтезе) функции G, близкой к F в смысле некоторой функции ошибки Е (см. рис. 2.7).
Если выбраны множество обучающих примеров — пар ( X k, Y k ) (где k = 1, 2,..., TV ) и способ вычисления функции ошибки Е, то обучение нейронной сети превращается в задачу многомерной оптимизации, имеющую очень большую размерность, при этом, поскольку функция Е может иметь произвольный вид, обучение в общем случае — многоэкстремальная невыпуклая задача оптимизации.
Для решения этой задачи могут быть использованы следующие (итерационные) алгоритмы:
• алгоритмы локальной оптимизации с вычислением частных производных первого порядка;
• алгоритмы локальной оптимизации с вычислением частных производных первого и второго порядка;
• стохастические алгоритмы оптимизации;
• алгоритмы глобальной оптимизации.
К первой группе относятся: градиентный алгоритм (метод скорейшего спуска); методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента; метод сопряженных градиентов; методы, учитывающие направление антиградиента на нескольких шагах алгоритма.
Ко второй группе относятся: метод Ньютона, методы оптимизации с разреженными матрицами Гессе, квазиньютоновские методы, метод Гаусса-Ньютона, метод Левенберга-Марквардта и др.
Стохастическими методами являются: поиск в случайном направлении, имитация отжига, метод Монте-Карло (численный метод статистических испытаний).
Задачи глобальной оптимизации решаются с помощью перебора значений переменных, от которых зависит целевая функция (функция ошибки Е).
Применение нейросети
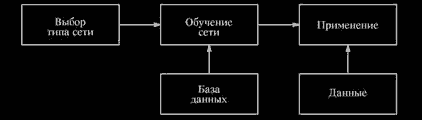
После того как сеть обучена, мы можем применять ее для решения различных задач (рис. 2.14).
Важнейшая особенность человеческого мозга состоит в том, что, однажды обучившись определенному процессу, он может верно
Рис. 2.14. Этапы нейросетевого проекта
действовать и в тех ситуациях, в которых он не бывал в процессе обучения. Например, мы можем читать почти любой почерк, даже если видим его первый раз в жизни. Так же и нейросеть, грамотным образом обученная, может с большой вероятностью правильно реагировать на новые, не предъявленные ей ранее данные. Например, мы можем нарисовать букву «А» другим почерком, а затем предложить нашей сети классифицировать новое изображение.
Веса обученной сети хранят достаточно много информации о сходстве и различиях букв, поэтому можно рассчитывать на правильный ответ и для нового варианта изображения.
Области применения нейросетей: классификация. Отметим, что задачи классификации (типа распознавания букв) очень плохо алгоритмизуются. Если в случае распознавания букв верный ответ очевиден для нас заранее, то в более сложных практических задачах обученная нейросеть выступает как эксперт, обладающий большим опытом и способный дать ответ на трудный вопрос.
Примером такой задачи служит медицинская диагностика, где сеть может учитывать большое количество числовых параметров (энцефалограмма, давление, вес и т.д.). Конечно, «мнение» сети в этом случае нельзя считать окончательным. Классификация предприятий по степени их перспективности — это уже привычный способ использования нейросетей в практике западных компаний (деление компаний на перспективные и убыточные). При этом сеть также использует множество экономических показателей, сложным образом связанных между собой.
Нейросетевой подход особенно эффективен в задачах экспертной оценки по той причине, что он сочетает в себе способность компьютера к обработке чисел и способность мозга к обобщению и распознаванию. Говорят, что у хорошего врача способность к распознаванию в своей области столь велика, что он может провести приблизительную диагностику уже по внешнему виду пациента. Можно согласиться также, что опытный трейдер чувствует направление движения рынка по виду графика. Однако в первом случае все факторы наглядны, т.е. характеристики пациента мгновенно воспринимаются мозгом как «бледное лицо», «блеск в глазах» и т.д. Во втором же случае учитывается только один фактор, показанный на графике, — курс за определенный период времени. Нейросеть позволяет обрабатывать огромное количество факторов (до нескольких тысяч), независимо от их наглядности, — это универсальный «хороший врач», который может поставить свой диагноз в любой области.
Кластеризация и поиск зависимостей. Помимо задач классификации, нейросети широко используются для поиска зависимостей в данных и кластеризации.
Например, нейросеть на основе методики МГУА (метод группового учета аргументов) позволяет на основе обучающей выборки построить зависимость одного параметра от других в виде полинома. Такая сеть может не только мгновенно выучить таблицу умножения, но и найти сложные скрытые зависимости в данных (например, финансовых), которые не обнаруживаются стандартными статистическими методами.
Кластеризация — это разбиение набора примеров на несколько компактных областей (кластеров), причем число кластеров заранее неизвестно. Кластеризация позволяет представить неоднородные данные в более наглядном виде и использовать далее для исследования каждого кластера различные методы. Например, таким образом можно быстро выявить фальсифицированные страховые случаи или недобросовестные предприятия.
Прогнозирование. Задачи прогнозирования особенно важны для практики, в частности, для финансовых приложений, поэтому поясним способы применения нейросетей в этой области более подробно.
Рассмотрим практическую задачу, ответ в которой неочевиден, — задачу прогнозирования курса акций на 1 день вперед.
Пусть у нас имеется база данных, содержащая значения курса за последние 300 дней. Простейший вариант в данном случае — попытаться построить прогноз завтрашней цены на основе курсов за последние несколько дней. Понятно, что прогнозирующая сеть должна иметь всего один выход и столько входов, сколько предыдущих значений мы хотим использовать для прогноза — например, 4 последних значения. Составить обучающий пример очень просто: входными значениями будут курсы за 4 последовательных дня, а желаемым выходом — известный нам курс в следующий день за этими четырьмя, т.е. каждая строка таблицы с обучающей последовательностью (выборкой) представляет собой обучающий пример, где первые 4 числа — входные значения сети, а пятое число — желаемое значение выхода.
Заметим, что объем обучающей выборки зависит от выбранного количества входов. Если сделать 299 входов, то такая сеть потенциально могла бы строить лучший прогноз, чем сеть с 4 входами, однако в этом случае мы имеем дело с огромным массивом данных, что делает обучение и использование сети практически невозможным. При выборе числа входов следует учитывать это, выбирая разумный компромисс между глубиной предсказания (число входов) и качеством обучения (объем тренировочного набора).
Вообще говоря, в зависимости от типа решаемой задачи, целесообразно применять нейронную сеть наиболее подходящей для такой задачи структуры.
Эффективность нейронных сетей
Эффективность нейронных сетей устанавливается рядом так называемых теорем о полноте. Ранее в нестрогой формулировке была приведена одна из них. Рассмотрим еще одну подобную теорему.
В 1989 г. Funahashi показал, что бесконечно большая нейронная сеть с единственным скрытым слоем способна аппроксимировать любую непрерывную функцию, сформулировав данное утверждение в форме следующей теоремы.
Теорема. Пусть ф(х) — непостоянная, ограниченная и монотонно возрастающая непрерывная функция. Пусть, далее,
— ограниченное множество и
— вещественная непрерывная функция, определенная на U.
Тогда для произвольного е > 0 существует целое L и вещественные константы Wi, w ^ такие, что аппроксимация
удовлетворяет неравенству
Другими словами, любое непрерывное отображение может быть аппроксимировано в смысле однородной топологии на U двухслойной нейронной сетью с активационными функциями ф(х) для нейронов скрытого слоя и линейными активационными функциями для нейронов выходного слоя.
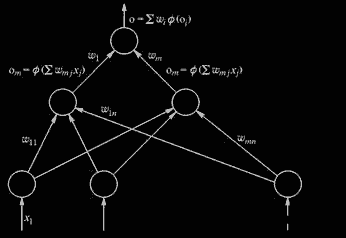
Рис. 2.21. Нейронная сеть Funahashi
На рис. 2.21 представлена НС Fu - nahashi для аппроксимации скалярной функции векторного аргумента.
Отметим еще раз, что приведенная теорема о полноте является далеко не единственной из известных.
Основными недостатками аппарата нейронных сетей являются:
• отсутствие строгой теории по выбору структуры НС;
• практическая невозможность извлечения приобретенных знаний из обученной НС (нейронная сеть практически всегда — «вещь в себе», черный ящик для исследователя).
Приведенный краткий материал о теории искусственных нейронных сетей является достаточным для перехода к следующей главе. Более подробная информация по структурам, алгоритмам обучения и использованию НС приведена, например, в рекомендуемой литературе.