Фон Неймановская модель компьютера подразумевает наличие процессора, на котором выполняется последовательность инструкций. Каждая инструкция, кроме типа арифметической операции, может определять адрес данных, которые необходимо прочесть или записать и/или адрес следующей инструкции, которую необходимо выполнить. Несмотря на то, что возможно программировать в терминах этой основной модели, используя машинный язык, этот метод для большинства целей предельно сложный, потому что мы должны запомнить миллионы адресов в памяти и организовать выполнение тысяч машинных инструкций. Ныне применяется модульный подход к проектированию, в соответствии с которым сложные программы создаются на основе простых компонент, а компоненты структурированы в терминах высокоуровневых абстракций, таких как структуры данных, циклы и процедуры. Такие абстракции как процедуры делают использование модульного подхода легче, позволяя манипулировать объектами, не вникая в их внутреннюю структуру. Высокоуровневые языки такие как Fortran, Pascal, C и Ada позволяют создавать дизайн программы в терминах этих абстракций и автоматически переводят его в исполнимый код.
Параллельное программирование выступает дополнительным источником сложности: если бы мы программировали на низком уровне, возросло бы не только число исполняемых инструкций, но нам также пришлось бы явно управлять работой тысяч процессоров и координировать миллионы межпроцессных взаимодействий. Поэтому абстрактность и модульность тут также важна, как и в последовательном программировании. На самом деле мы придадим модульности значение четвертого фундаментального требования по отношению к параллельному ПО, на ряду с параллельностью, масштабируемостью и локальностью.
1. Задачи и каналы
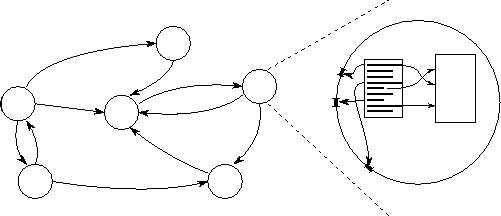
Рисунок 1.7: Простая модель параллельного программирования. Рисунок показывает мгновенный снимок состояния вычисления и детализированную картину одной задачи. Вычисление состоит из набора задач (представляемых циклами) соединенных каналами (стрелками). Задача инкапсулирует программу, локальную память и определяет свой интерфейс по отношению к внешней среде. Канал – это очередь сообщений, в которую отправитель может посылать сообщения, а получатель может удалять сообщения, переходя в «заблокированное» состояние, если сообщение недоступно.
В дальнейшем мы обсудим необходимость и полезность абстракций в модели параллельного программирования. На самом деле, необходима система, которая позволила бы вести четкий диалог о параллелизме и локальности, и которая бы облегчила создание масштабируемых, модульных программ. Также необходимы абстракции, с которыми легко работать и, которые совпадали бы с архитектурной моделью суперкомпьютера. Можно выделить много подобных абстракций, однако две особенно хорошо отвечают вышеуказанным требованиям: задачи и каналы. Они продемонстрированы на рисунке 1.7 и могут быть охарактеризованы следующим образом:

Рисунок 1.8 - Четыре основных действий, производимых задачами. В дополнение к чтению и записи в локальную память, задача может отправлять и получать сообщения, создавать и прекращать выполнение новых задач.
1. Параллельная программа (вычисление) состоит из одной или более задач. Задачи выполняются параллельно. Число задач может варьироваться на протяжении выполнения программы.
2. Задача инкапсулирует последовательную программу в локальной памяти. (В конечном счете, это виртуальная фон Неймановская машина). Набор входных и выходных портов определяют интерфейс задачи по отношению к окружающей среде.
3. Задача может выполнять 4 основных действия помимо операций чтения/записи в локальную память (Рис. 1.8): отправлять сообщения в исходящие порты, получать сообщения из входящих портов, создавать новые задачи и прерывать работу.
4. Операция посылки – асинхронная: она практически мгновенная. Операция получения – синхронная: выполнение задачи блокируется до тех пор, пока сообщение будет получено.
5. Исходящие/входящие пары портов могут быть соединены очередями сообщений, называемых каналами. Каналы могут быть созданы и удалены, и ссылки на каналы (порты) могут включаться в сообщения, таким образом, связность задач может динамически изменяться.
6. Задачи могут соотноситься с физическими процессорами по-разному; соотношение задач и процессоров не влияет на семантику программы. В частном случае, множество задач может выполняться на одном процессоре. (Мы также можем представить себе ситуацию, когда одна задача может выполняться на множестве процессоров, но этот вариант не рассматривается здесь).
Абстракция «задача» представляет собой механизм, который позволяет говорить о локальности: данные, которые находятся в локальной памяти задачи – это «закрытые» данные. Все остальные данные – «удаленные». Абстракция «канал» представляет собой механизм, который позволяет определить случай, когда выполнение одной задачи требует данных из другой задачи (это называется «зависимостью по данным»( data dependency)). Последующий простой пример иллюстрирует вышесказанное.
Пример. Строительство моста. Представьте себе реальную проблему. Мост строится из балок, которые производятся в литейном цеху. Грузовики транспортируют балки от цеха к месту строительства моста. Эта ситуация проиллюстрирована на рис. 1.9(а), цех и мост представляют собой задачи, а поток грузовиков - это канал. Заметьте, что этот подход позволяет строить мост и создавать балки параллельно без явной координации: как только цех производит балку, ее погружают на грузовик и затем, когда балку доставят к мосту, ее используют при строительстве.

Рис. 1.9 – Два решения проблемы строительства моста. Обе представляют работу цеха и строительство моста как различные задачи. Первое решение использует единственный канал, по которому балки, производимые в цехе, транспортируются по мере их производства. Если цех производит балки быстрее, чем они расходуются при строительстве, то балки накапливаются на стороне моста. Второе решение проблемы использует второй канал, чтобы отправлять контрольные сообщения цеху во избежание переполнения.
Недостаток такой схемы в том, что цех может производить балки гораздо быстрее, чем команда строителей использовать их. Чтобы предотвратить переполнение на стороне моста, команда строителей может явно запрашивать доставку балок в случае необходимости. Этот вариант изображен на рис. 1.9(b), поток запросов представляет собой второй канал. Второй канал также может использоваться для прекращения поставок балок, когда строительство закончиться.
2. Другие программные модели
Модель «задача/канал» не единственный подход к описанию параллельных алгоритмов. Было предложено множество других моделей, различных по гибкости, механизму взаимодействия между задачами, степенью структурированности задач и поддержки локальности, масштабируемости и модульности. Вот, обзор некоторых из них.
Message passing. Message passing, возможно, одна из наиболее распространенных параллельных моделей сейчас. Программы, ориентированные на модель Message passing, также как и задачи в модели «задача/канал», создают множество задач, и каждая задача инкапсулирует локальные данные. Каждая задача идентифицируется уникальным именем, и задачи взаимодействуют, посылая и получая сообщения от именованных задач. В этом контексте, Message passing – это всего лишь минимальный вариант модели «задача/канал», отличия существуют только в механизме обмена данными. Например, вместо того чтобы посылать сообщение в «канал ch», мы посылаем сообщение «задаче 17».
Модель Message passing не отрицает динамического создания задач, выполнения множества задач на одном процессоре или выполнения различных программ различными задачами. Однако, на практике большинство систем основанных на модели Message passing создают фиксированное количество идентичных задач в начале программы и не создают и не уничтожают задачи во время выполнения программы. говорят, что такие системы реализуют модель «одна задача множественные данные»(single program multiple data-SPMD) потому что каждая задача выполняет одну и ту же программу, но оперирует различными данными.
Параллелизм данных (Data Parallelism). Еще одна распространенная модель параллельного программирования – параллелизм данных. Данная модель использует параллелизм, основанный на выполнении одной и той же операции над множеством элементов структуры данных. Например, «добавить 2 к каждому элементу этого массива», или «увеличить зарплату всех работников с пятилетним стажем». Программа, использующая параллелизм данных, состоит из последовательности таких операций. О каждой операции можно думать как о независимой задаче, для параллелизма данных характерна мелкозернистось, концепция локальности не поддерживается согласно природе подхода. Поэтому, компиляторы, основанные на параллелизме данных, требуют, чтобы программист указал то, каким образом данные будут распределяться между процессорами, другими словами, как данные будут распределены между задачами.
Общая память. В модели программирования общая память, задачи используют общее адресное пространство, в которое они пишут и считывают асинхронно. Различные механизмы, такие как блокировки и семафоры используются, чтобы контролировать доступ к общей памяти. С точки зрения программиста, преимущество этой модели в том, что данные явно не принадлежат не одной из задач и, поэтому нет необходимости явно определять перемещение данных между задачами. Эта модель может упростить разработку программ. Однако понимание и управление локальностью становиться более сложным и этому необходимо уделять большое внимание в большинстве архитектур на основе общей памяти. Также может усложниться написание детерминированных программ.
Ссылки
1. ACM. Resources in Parallel and Concurrent Systems. ACM Press, 1991.
2. G. Adams, D. Agrawal, and H. Siegel. A survey and comparison of fault-tolerant multistage interconnection networks. IEEE Trans. Computs., C-20(6):14--29, 1987.
3. J. Adams, W. Brainerd, J. Martin, B. Smith, and J. Wagener. The Fortran 90 Handbook. McGraw-Hill, 1992.
4. A. Aggarwal and J. S. Vitter. The input/output complexity of sorting and related problems. Commun. ACM, 31(9):1116--1127, 1988.
5. G. Agha. Actors. MIT Press, 1986.