If we blindly used POJOs (plain-old Java objects) and lightweight frameworks, we would be repeating the mistake the enterprise Java community made with EJB (Enterprise JavaBeans). Every technology has both strengths and weaknesses, and it's important to know how to choose the most appropriate one for a given situation.
This book is about implementing enterprise applications using design patterns and lightweight frameworks. To enable you to use them effectively in your application, it provides a decision-making framework that consists of five key questions that must be answered when designing an application or implementing the business logic for an individual use-case. By consciously addressing each of these design issues and understanding the consequences of your decisions, you will vastly improve the quality of your application.
In this article you will get an overview of those five design decisions. I briefly describe each design decision's options as well as its respective benefits and drawbacks.
Business logic and database access decisions
There are two quite different ways to design an enterprise Java application. One option is to use the classic EJB 2 approach, which I will refer to as the heavyweight approach. When using the heavyweight approach, you use session beans and message-driven beans to implement the business logic. You use either DAOs (data access objects) or entity beans to access the business logic.
The other option is to use POJOs and lightweight frameworks, which I'll refer to as the POJO approach. When using the POJO approach, your business logic consists entirely of POJOs. You use a persistence framework (a.k.a. object/relational mapping framework) such as Hibernate or JDO (Java Data Objects) to access the database, and you use Spring AOP (aspect-oriented programming) to provide enterprise services such as transaction management and security.
EJB 3 somewhat blurs the distinction between the two approaches because it has embraced POJOs and some lightweight concepts. For example, entity beans are POJOs that can be run both inside and outside the EJB container. However, while session beans and message-driven beans are POJOs, they also have heavyweight behavior since they can only run inside the EJB container. So as you can see, EJB 3 has both heavyweight and POJO characteristics. EJB 3 entity beans are part of the lightweight approach, whereas session beans and message-driven beans are part of the heavyweight approach.
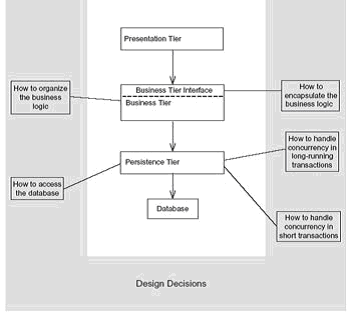
Choosing between the heavyweight approach and the POJO approach is one of the first of myriad design decisions that you must make during development. It's a decision that affects several aspects of the application, including business logic organization and the database access mechanism. To help decide between the two approaches, let's look at the architecture of a typical enterprise application, which is shown in Figure 1, and examine the kinds of decisions that must be made when developing it.
Figure 1. A typical application architecture and the key business logic and database access design decisions.
The application consists of the Web-based presentation tier, the business tier, and the persistence tier. The Web-based presentation tier handles HTTP requests and generates HTML for regular browser clients and XML, and other content for rich Internet clients, such as Ajax-based clients (asynchronous JavaScript and XML). The business tier, which is invoked by the presentation tier, implements the application's business logic. The persistence tier is used by the business tier to access external datasources such as databases and other applications.
The design of the presentation tier is outside the scope of this article, but let's look at the rest of the diagram. We need to decide the structure of the business tier and the interface that it exposes to the presentation tier and its other clients. We also need to decide how the persistence tier accesses databases, which is the main source of data for many applications. We must also decide how to handle concurrency in short transactions and long-running transactions. That adds up to five decisions that any designer/architect must make and that any developer must know in order to understand the big picture.
These decisions determine key characteristics of the design of the application's business and the persistence tiers. There are, of course, many other important decisions that you must make—such as how to handle transactions, security, and caching, and how to assemble the application—but answering those five questions often addresses these other issues as well.
Each of the five decisions shown in Figure 1 has multiple options. Each option has benefits and drawbacks that determine its applicability to a given situation. As you will see in this article, each one makes different trade-offs in terms of one or more areas, including functionality, ease of development, maintainability, and usability. Even though I'm a big fan of the POJO approach, it is important to know these benefits and drawbacks so that you can make the best choices for your application.
Let's now take a brief look at each decision and its options.
Decision 1: Organizing the business logic
These days a lot of attention is focused on the benefits and drawbacks of particular technologies. Although this is certainly very important, it is also essential to think about how your business logic is structured. It is quite easy to write code without giving much thought to how it is organized. For example, it is too easy to add yet more code to a session bean instead of carefully deciding which domain model class should be responsible for the new functionality. Ideally, however, you should consciously organize your business logic in the way that's the most appropriate for your application. After all, I'm sure you've experienced the frustration of having to maintain someone else's badly structured code.
The key decision you must make is whether to use an object-oriented approach or a procedural approach. This isn't a decision about technologies, but your choice of technologies can potentially constrain the organization of the business logic. Using EJB 2 firmly pushes you toward a procedural design, whereas POJOs and lightweight frameworks enable you to choose the best approach for your particular application. Let's examine the options.
Using a procedural design
While I am a strong advocate of the object-oriented approach, there are some situations where it is overkill, such as when you are developing simple business logic. Moreover, an object-oriented design is sometimes infeasible—for example, if you do not have a persistence framework to map your object model to the database. In such a situation, a better approach is to write procedural code and use what Martin Fowler calls the Transaction Script pattern (see Patterns of Enterprise Application Architecture). Rather than doing any object-oriented design, you simply write a method, which is called a transaction script, to handle each request from the presentation tier.
An important characteristic of this approach is that the classes that implement behavior are separate from those that store state. In an EJB 2 application, this typically means that your business logic will look similar to the design shown in Figure 2. This kind of design centralizes behavior in session beans or POJOs, which implement the transaction scripts and manipulate "dumb" data objects that have very little behavior. Because the behavior is concentrated in a few large classes, the code can be difficult to understand and maintain.

Figure 2. The structure of a procedural design: large transaction script classes and many small data objects
The design is highly procedural and relies on few of the capabilities of object-oriented programming (OOP) languages. This is the type of design you would create if you were writing the application in C or another non-OOP language. Nevertheless, you should not be ashamed to use a procedural design when it is appropriate.
Using an object-oriented design
The simplicity of the procedural approach can be quite seductive. You can just write code without having to carefully consider how to organize the classes. The problem is that if your business logic becomes complex, then you can end up with code that's a nightmare to maintain. Consequently, unless you are writing an extremely simple application, you should resist the temptation to write procedural code and instead develop an object-oriented design.
In an object-oriented design, the business logic consists of an object model, which is a network of relatively small classes. These classes typically correspond directly to concepts from the problem domain. As Figure 3 shows, in such a design some classes have only either state or behavior, but many contain both, which is the hallmark of a well-designed class.

Figure 3. The structure of a domain model: small classes that have state and behavior
An object-oriented design has many benefits, including improved maintainability and extensibility. You can implement a simple object model using EJB 2 entity beans, but to enjoy most of the benefits you must use POJOs and a lightweight persistence framework such as Hibernate and JDO. POJOs enable you to develop a rich domain model, which makes use of such features as inheritance and loopback calls. A lightweight persistence framework enables you to easily map the domain model to the database.
Another name for an object model is a domain model, and Fowler calls the object-oriented approach to developing business logic the Domain Model pattern.
Table Module pattern
I have always developed applications using the Domain Model and Transaction Script patterns. But I once heard rumors of an enterprise Java application that used a third approach, which is what Fowler calls the Table Module pattern. This pattern is more structured than the Transaction Script pattern, because for each database table, it defines a table module class that implements the code that operates on that table. But like the Transaction Script pattern, it separates state and behavior into separate classes because an instance of a table module class represents the entire database rather than individual rows. As a result, maintainability is a problem. Consequently, there is very little benefit to using the Table Module pattern.
Decision 2: Encapsulating the business logic
In the previous section, I covered how to organize the business logic. You must also decide what kind of interface the business logic should have. The business logic's interface consists of those types and methods that are callable by the presentation tier. An important consideration when designing the interface is how much of the business logic's implementation should be encapsulated and therefore not visible to the presentation tier. Encapsulation improves maintainability because, by hiding the business logic's implementation details, it can prevent changes to it affecting the presentation tier. The downside is that you must typically write more code to encapsulate the business logic.
You must also address other important issues, such as how to handle transactions, security, and remoting, since they are generally the responsibility of the business logic's interface code. The business tier's interface typically ensures that each call to the business tier executes in a transaction in order to preserve the consistency of the database. Similarly, it also verifies that the caller is authorized to invoke a business method. The business tier's interface is also responsible for handling some kinds of remote clients.
Let's consider the options.
EJB session facade
The classic J2EE approach is to encapsulate business logic with an EJB-based session facade. The EJB container provides transaction management, security, distributed transactions, and remote access. The facade also improves maintainability by encapsulating the business logic. The coarse-grained API can also improve performance by minimizing the number of calls that the presentation tier must make to the business tier. Fewer calls to the business tier reduce the number of database transactions and increase the opportunity to cache objects in memory. It also reduces the number of network round-trips if the presentation tier is accessing the business tier remotely. Figure 4 shows an example of an EJB-based session facade.
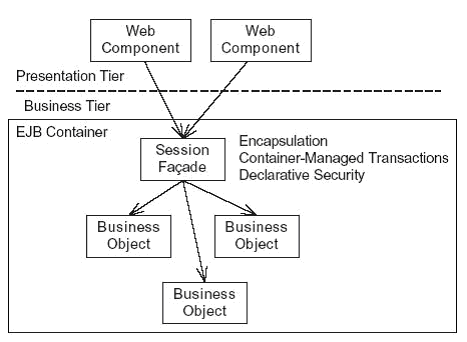
Figure 4. Encapsulating the business logic with an EJB session facade
In this design, the presentation tier, which may be remote, calls the facade. The EJB container intercepts the calls to the facade, verifies that the caller is authorized, and begins a transaction. The facade then calls the underlying objects that implement the business logic. After the facade returns, the EJB container commits or rolls back the transaction.
Unfortunately, using an EJB session facade has some significant drawbacks. For example, EJB session beans can only run in the EJB container, which slows development and testing. In addition, if you are using EJB 2, then developing and maintaining DTOs (data transfer objects), which are used to return data to the presentation tier, is tedious and time consuming.
POJO facade
For many applications, a better approach uses a POJO facade in conjunction with an AOP-based mechanism such as the Spring framework that manages transactions, persistence framework connections, and security. A POJO facade encapsulates the business tier in a similar fashion to an EJB session facade and usually has the same public methods. The key difference is that it's a POJO instead of an EJB and that services such as transaction management and security are provided by AOP instead of the EJB container. Figure 5 shows an example of a design that uses a POJO facade.
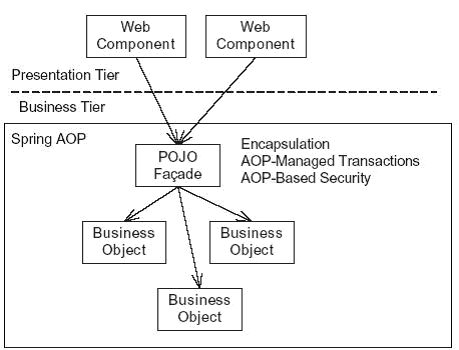
Figure 5. Encapsulating the business logic with a POJO facade
The presentation tier invokes the POJO facade, which then calls the business objects. In the same way that the EJB container intercepts the calls to the EJB facade, the AOP interceptors intercept the calls to the POJO facade and authenticate the caller and begin, commit, and roll back transactions.
The POJO facade approach simplifies development by enabling all of the business logic to be developed and tested outside the application server, while providing many of the important benefits of EJB session beans such as declarative transactions and security. As an added bonus, you have to write less code. You can avoid writing many DTO classes because the POJO facade can return domain objects to the presentation tier; you can also use dependency injection to wire the application's components together instead of writing JNDI (Java Naming and Directory Interface) lookup code.
However, there are some reasons not to use the POJO facade. For example, a POJO facade cannot participate in a distributed transaction initiated by a remote client.
Exposed Domain Model pattern
Another drawback of using a facade is that you must write extra code. Moreover, the code that enables persistent domain objects to be returned to the presentation tier is especially prone to errors. There is the increased risk of runtime errors caused by the presentation tier trying to access an object that was not loaded by the business tier. If you are using JDO, Hibernate, or EJB 3, you can avoid this problem by exposing the domain model to the presentation tier and letting the business tier return the persistent domain objects back to the presentation tier. As the presentation tier navigates relationships between domain objects, the persistence framework will load the objects that it accesses, a technique known as lazy loading. Figure 6 shows a design in which the presentation tier freely accesses the domain objects.
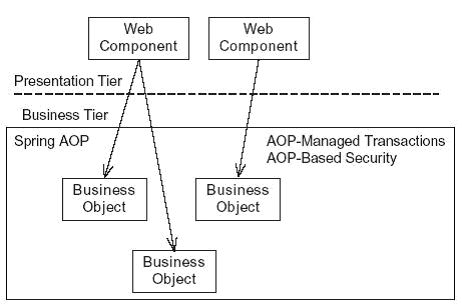
Figure 6. Using an exposed domain model
In the design in Figure 6, the presentation tier calls the domain objects directly without going through a facade. Spring AOP continues to provide services such as transaction management and security.
An important benefit of this approach is that it eliminates the need for the business tier to know what objects it must load and return to the presentation tier. However, although this sounds simple, you will see there are some drawbacks. It increases the complexity of the presentation tier, which must manage database connections. Transaction management can also be tricky in a Web application because transactions must be committed before the presentation tier sends any part of the response back to the browser.
Decision 3: Accessing the database
No matter how you organize and encapsulate the business logic, eventually you have to move data to and from the database. In a classic J2EE application, you had two main choices: JDBC (Java Database Connectivity), which required a lot of low-level coding, or entity beans, which were difficult to use and lacked important features. In comparison, one of the most exciting things about using lightweight frameworks is that you have some new and much more powerful ways to access the database that significantly reduce the amount of database access code that you must write. Let's take a closer look.
What's wrong with using JDBC directly?
The recent emergence of object/relational mapping frameworks (such as JDO and Hibernate) and SQL mapping frameworks (such as iBATIS) did not occur in a vacuum. Instead, they emerged from the Java community's repeated frustrations with JDBC. Let's review the problems with using JDBC directly in order to understand the motivations behind the newer frameworks. There are three main reasons why using JDBC directly is not a good choice for many applications:
Developing and maintaining SQL is difficult and time consuming—Some developers find writing large, complex SQL statements quite difficult. It can also be time consuming to update the SQL statements to reflect changes in the database schema. You need to carefully consider whether the loss of maintainability is worth the benefits.
There is a lack of portability with SQL—Because you often need to use database-specific SQL, an application that works with multiple databases must have multiple versions of some SQL statements, which can be a maintenance nightmare. Even if your application only works with one database in production, SQL's lack of portability can be an obstacle to using a simpler and faster in-memory database such as Hypersonic Structured Query Language Database Engine (HSQLDB) for testing.
Writing JDBC code is time consuming and error-prone—You must write lots of boilerplate code to obtain connections, create and initialize prepared statements, and clean up by closing connections and prepared statements. You also have to write the code to map between Java objects and SQL statements. As well as being tedious to write, JDBC code is also error-prone.
The first two problems are unavoidable if your application must execute SQL directly. Sometimes, you must use the full power of SQL, including vendor-specific features, in order to get good performance. Or, for a variety of business-related reasons, your DBA might demand complete control over the SQL statements executed by your application, which can prevent you from using persistence frameworks that generate the SQL on the fly. Often, the corporate investment in its relational databases is so massive that the applications working with the databases can appear relatively unimportant. Quoting the authors of iBATIS in Action, there are cases where "the database and even the SQL itself have outlived the application source code, or even multiple versions of the source code. In some cases, the application has been rewritten in a different language, but the SQL and database remained largely unchanged." If you are stuck with using SQL directly, then fortunately there is a framework for executing it directly, one that is much easier to use than JDBC. It is, of course, iBATIS.
Using iBATIS
All of the enterprise Java applications I've developed executed SQL directly. Early applications used SQL exclusively, whereas the later ones, which used a persistence framework, used SQL in a few components. Initially, I used plain JDBC to execute the SQL statements, but later on I often ended up writing mini-frameworks to handle the more tedious aspects of using JDBC. I even briefly used Spring's JDBC classes, which eliminate much of the boilerplate code. But neither the homegrown frameworks nor the Spring classes addressed the problem of mapping between Java classes and SQL statements, which is why I was excited to come across iBATIS.
In addition to completely insulating the application from connections and prepared statements, iBATIS maps JavaBeans to SQL statements using XML descriptor files. It uses Java bean introspection to map bean properties to prepared statement placeholders and to construct beans from a ResultSet. It also includes support for database-generated primary keys, automatic loading of related objects, caching, and lazy loading. In this way, iBATIS eliminates much of the drudgery of executing SQL statements. iBATIS can considerably simplify code that executes SQL statements. Instead of writing a lot of low-level JDBC code, you write an XML descriptor file and make a few calls to iBATIS APIs.
Using a persistence framework
Of course, iBATIS cannot address the overhead of developing and maintaining SQL or its lack of portability. To avoid those problems you need to use a persistence framework. A persistence framework maps domain objects to the database. It provides an API for creating, retrieving, and deleting objects. It automatically loads objects from the database as the application navigates relationships between objects and updates the database at the end of a transaction. A persistence framework automatically generates SQL using the object/relational mapping, which is typically specified by an XML document that defines how classes are mapped to tables, how fields are mapped to columns, and how relationships are mapped to foreign keys and join tables.
EJB 2 had its own limited form of persistence framework: entity beans. However, EJB 2 entity beans have so many deficiencies, and developing and testing them is extremely tedious. As a result, EJB 2 entity beans should rarely be used. What's more, it is unclear how some of their deficiencies will be addressed by EJB 3.
The two most popular lightweight persistence frameworks are JDO, which is a Sun standard, and Hibernate, which is an open source project. They both provide transparent persistence for POJO classes. You can develop and test your business logic using POJO classes without worrying about persistence, then map the classes to the database schema. In addition, they both work inside and outside the application server, which simplifies development further. Developing with Hibernate and JDO is so much more pleasurable than with old-style EJB 2 entity beans.
In addition to deciding how to access the database, you must decide how to handle database concurrency. Let's look at why this is important as well as the available options.
Decision 4: Handling concurrency in database transactions
Almost all enterprise applications have multiple users and background threads that concurrently update the database. It's quite common for two database transactions to access the same data simultaneously, which can potentially make the database inconsistent or cause the application to misbehave. Most applications must handle multiple transactions concurrently accessing the same data, which can affect the design of the business and persistence tiers.
Applications must, of course, handle concurrent access to shared data regardless of whether they are using lightweight frameworks or EJB. However, unlike EJB 2 entity beans, which required you to use vendor-specific extensions, JDO and Hibernate directly support most of the concurrency mechanisms. What's more, using them is either a simple configuration issue or requires only a small amount of code.
In this section, you will get a brief overview of the different options for handling concurrent updates in database transactions, which are transactions that do not involve any user input. In the next section, I briefly describe how to handle concurrent updates in longer application-level transactions, which are transactions that involve user input and consist of a sequence of database transactions.
Isolated database transactions
Sometimes you can simply rely on the database to handle concurrent access to shared data. Databases can be configured to execute database transactions that are, in database-speak, isolated from one another. Don't worry if you are not familiar with this concept; for now the key thing to remember is that if the application uses fully isolated transactions, then the net effect of executing two transactions simultaneously will be as if they were executed one after the other.
On the surface this sounds extremely simple, but the problem with these kinds of transactions is that they have what is sometimes an unacceptable reduction in performance because of how isolated transactions are implemented by the database. For this reason, many applications avoid them and instead use what is termed optimistic or pessimistic locking, which is described a bit later.
Optimistic locking
One way to handle concurrent updates is to use optimistic locking. Optimistic locking works by having the application check whether the data it is about to update has been changed by another transaction since it was read. One common way to implement optimistic locking is to add a version column to each table, which is incremented by the application each time it changes a row. Each UPDATE statement's WHERE clause checks that the version number has not changed since it was read. An application can determine whether the UPDATE statement succeeded by checking the row count returned by PreparedStatement.executeUpdate(). If the row has been updated or deleted by another transaction, the application can roll back the transaction and start over.
It is quite easy to implement an optimistic locking mechanism in an application that executes SQL statements directly. But it is even easier when using persistence frameworks such as JDO and Hibernate because they provide optimistic locking as a configuration option. Once it is enabled, the persistence framework automatically generates SQL UPDATE statements that perform the version check.
Optimistic locking derives its name from the fact it assumes that concurrent updates are rare and that, instead of preventing them, the application detects and recovers from them. An alternative approach is to use pessimistic locking, which assumes that concurrent updates will occur and must be prevented.
Pessimistic locking
An alternative to optimistic locking is pessimistic locking. A transaction acquires locks on the rows when it reads them, which prevent other transactions from accessing the rows. The details depend on the database, and unfortunately not all databases support pessimistic locking. If it is supported by the database, it is quite easy to implement a pessimistic locking mechanism in an application that executes SQL statements directly. However, as you would expect, using pessimistic locking in a JDO or Hibernate application is even easier. JDO provides pessimistic locking as a configuration option, and Hibernate provides a simple programmatic API for locking objects.
In addition to handling concurrency within a single database transaction, you must often handle concurrency across a sequence of database transactions.
Decision 5: Handling concurrency in long transactions
Isolated transactions, optimistic locking, and pessimistic locking only work within a single database transaction. However, many applications have use-cases that are long running and that consist of multiple database transactions that read and update shared data. For example, suppose a use-case describes how a user edits an order (the shared data). This is a relatively lengthy process, which might take as long as several minutes and consists of multiple database transactions. Because data is read in one database transaction and modified in another, the application must handle concurrent access to shared data differently. It must use the Optimistic Offline Lock pattern or the Pessimistic Offline Lock pattern, two more patterns described by Fowler in Patterns of Enterprise Application Architecture.
Optimistic Offline Lock pattern
One option is to extend the optimistic locking mechanism described earlier and check in the final database transaction of the editing process that the data has not changed since it was first read. You can, for example, do this by using a version number column in the shared data's table. At the start of the editing process, the application stores the version number in the session state. Then, when the user saves their changes, the application makes sure that the saved version number matches the version number in the database.
Because the Optimistic Offline Lock pattern only detects changes when the user tries to save their changes, it only works well when starting over is not a burden on the user. When implementing such use-cases where the user would be extremely annoyed by having to discard several minutes' work, a much better option is to use the Pessimistic Offline Lock.
Pessimistic Offline Lock pattern
The Pessimistic Offline Lock pattern handles concurrent updates across a sequence of database transactions by locking the shared data at the start of the editing process, which prevents other users from editing it. It is similar to the pessimistic locking mechanism described earlier except that the locks are implemented by the application rather than the database. Because only one user at a time is able to edit the shared data, they are guaranteed to be able to save their changes.
Author Bio
Chris Richardson is a developer, architect, and mentor with more than 20 years of experience. He runs a consulting company that helps development teams become more productive and successful by adopting POJOs and lightweight frameworks. Richardson has been a technical leader at a variety of companies, including Insignia Solutions and BEA Systems. He holds a BA and MA in computer science from the University of Cambridge in England. He lives in Oakland, California, with his wife and three children.