Efficient XML File Reading for Game Development
Christoph Luerig
SAX model
As mentioned earlier the SAX model stands for “Simple API for XML”. The intention of this model is to provide a lightweight API that is easily adjustable to specific situations; it also comes with a low demand of resources. The idea of a SAX parser is not to generate a DOM tree of the document in memory but rather use certain callback functions when the XML file is streamed and certain elements are encountered. The application has to react to these callbacks and store the data into the correct positions. When the reaction is done, control is returned to the parser.
The main difference between DOM tree and SAX model is that with SAX, the control is governed by the parser in this case that feeds the data into the system. In the DOM model, however, the objects could extract the data themselves, so the control flow is very different. The control flow for our above example looks like:

The SAX parser used for the demonstration here is eXpat [SFX]. This parser is available via SourceForge. eXpat requires three callback handlers to be registered. One handler is for the start of the element; This handler provides all the information about the attributes. The second handler does not provide any specific information but marks the end of an element. The third type of callback provides the text within an element. For simplicity we do not use this feature here, but its implementation is straightforward. eXpat does not read from a file directly, but rather from memory. It is not necessary to load the complete file into memory; it can be read in sections that are processed by the parser. During processing the mentioned C-style callbacks are called, and data is fed to the application. All callbacks can provide a user data entry that is an arbitrary pointer which can be specified up front.
This approach seems a bit irritating and less suited for game development at first sight, which is also probably the reason it is so rarely used. On one hand there is the internal game structure possibly consisting of a large hierarchy of objects that want to grab data from a file. On the other hand there are the C-style callbacks from the SAX parser that want to deliver data in a manner that is not controlled by the object hierarchy. Switching from an internal home brew data format to a DOM tree parser seems to be much easier on first glance than to switch to an SAX parser.
If one takes a closer look, however the difference is not that large. The idea to solve the problem and make the parsing process look the same again is split into two parts. The first idea is to use a visitor that processes the callbacks and feeds the data to the destination objects. This visitor is responsible for associating the information provided by the callbacks with certain objects in the object hierarchy of the game. The second idea refers to the processing of the data within an object. In the DOM tree model, the object was doing a few calls to the tree to extract the data; This is done in the parse function. In the proposed solution, the data input function is called several times by the mentioned visitor. Every call contains a description of the data and the value itself. In an “if” or a “switch” cascade, the description of the data is identified and the data is written to the correct destination. This process is further explained in the following paragraphs.
The first instance in the process that receives data is the visitor. As all the callbacks can be provided with an arbitrary pointer, we set up a pointer to the visitor to process the data. The callbacks themselves are C functions that call their corresponding method in the visitor. The main task of the visitor is to dispatch the information that comes from the parser callbacks to their destination objects. To accomplish this task, it contains a stack of recipients. Data is fed to the recipient on top of the stack. Whenever a new element is started, a new recipient is pushed onto the stack, and when an element has ended, the recipient is popped. This stack hierarchy within the visitor corresponds to the call stack hierarchy when the diverse parse functions are called to extract the data from the DOM tree. Whenever data is fed from the dispatching visitor to a recipient in the form of a start element, the recipient has the opportunity to return a pointer to a new recipient for upcoming data. In this case, the pointer to this internal object is pushed onto the stack. In the other case we simply push the same pointer to the already existing object onto the stack. When an element is ended, a recipient is popped from the stack and any further data is transferred to the original recipient. Visually the process looks like this:
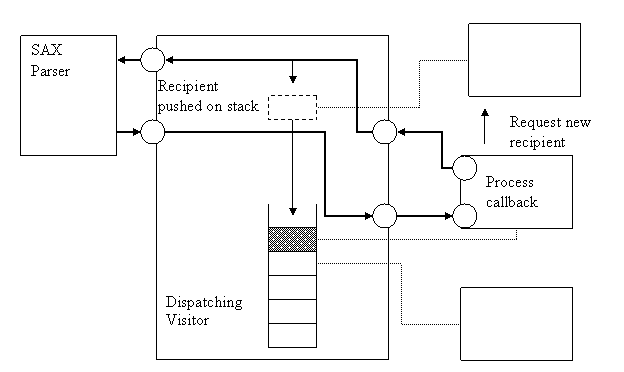
In this example, a call is dispatched to a destination object that requests a new recipient to be pushed onto the stack. When the callback is processed, all subsequent callbacks will get to the new recipient until the end-of-element is encountered for the object that initialized the push command. Then a pop command is executed, and all callbacks are again routed to the old object.
The visitor that dispatches all the calls is the central idea of this approach. The declaration of a dispatcher class looks like this:
class ParseDispatcher
{
public:
void ParseFile(const char* name, Receiver* startObject);
private:
stack m_stackOfReceivers;
static void XMLCALL start(void *data, const char *el,
const char **attr);
static void XMLCALL end(void *data, const char *el);
};
The receiver is an abstract class of every class that can get information and be dispatched to. The main routine parses a file and gets a first receiver handed over. This object is the first to receive information. The two static methods are the two C methods that are registered with eXpat to mark the beginning and the end of an element. The declaration of the abstract receiver class looks like this:
class Receiver
{
public:
virtual Receiver* ProcessData(const char *el, const char **attr)=0;
};
The ProcessData method gets the name of the element and an array of attribute name and value pairs. It returns the new receiver or a NULL pointer if subsequent ProcessData calls should go to that same object.
The implementation of the ParserDispatcher looks like this:
void XMLCALL ParseDispatcher::start(void *data, const char *el,
const char **attr)
{
ParseDispatcher* processor = ((ParseDispatcher*)data);
Receiver* candidate = processor->m_stackOfReceivers.top();
Receiver* followUp = candidate->ProcessData(el,attr);
if (followUp)
processor->m_stackOfReceivers.push(followUp);
else
processor->m_stackOfReceivers.push(candidate);
}
void XMLCALL ParseDispatcher::end(void *data, const char *el)
{
((ParseDispatcher*)data)->m_stackOfReceivers.pop();
}
void ParseDispatcher::ParseFile(const char* name, Receiver* startObject)
{
m_stackOfReceivers.push(startObject);
char buf[BUFSIZ];
XML_Parser parser = XML_ParserCreate(NULL);
XML_SetUserData(parser, this);
int done;
FILE* input = fopen(name, "r");
XML_SetElementHandler(parser, start, end);
do
{
size_t len = fread(buf, 1, sizeof(buf), input);
done = len < sizeof(buf);
XML_Parse(parser, buf, len, done);
}
while (!done);
XML_ParserFree(parser);
m_stackOfReceivers.pop();
}
The parse method generates the parser and registers itself via the arbitrary pointer in “XML_SetUserData”, that it can be referenced later on in the static methods. This way one can have several parsers running at the same time. The file is opened and the handlers are registered. The first receiving object is pushed onto the stack. All the while, loop data is read in chunks to limit storage requirements.
In the static start method, the stack is extracted via user data pointer and the call is dispatched. Depending on whether we get a return value or not, we push the new object or the same object onto the stack. If we would like to process text that appears between an element start and end, we would dispatch it to the same top object on the stack without modifying the stack itself. The end command pops the topmost pointer from the stack again, so that it returns to the old object.
This, of course, is again a minimalist implementation without any error processing or ease of use issues.
The second part is the declaration and implementation of wheel and car. Both have to be derived from the receiver class in order to work properly. The declarations of these classes look like this:
class Wheel : public Receiver
{
public:
virtual Receiver* ProcessData(const char *el, const char **attr);
protected:
float m_radius;
};
class Car : public Receiver
{
public:
virtual Receiver* ProcessData(const char *el, const char **attr);
protected:
Wheel m_wheel;
float m_acceleration;
float m_mass;
};
The declarations look similar to the ones in the DOM parsing model, except for the fact that they are now derived from Receiver and have the “ProcessData” method instead of “Parse”. Even if it looks similar, one always has to keep in mind that the control flow is different. The “ProcessData” method of one object can be called several times and one “ProcessData” of one object never calls the “ProcessData” of another object; but just returns a pointer to the new receiver.
The implementation of the car with the SAX parser now looks like this:
Receiver* Car::ProcessData(const char *el, const char **attr)
{
if ((strcmp(el,"Wheel")==0))
return (&m_wheel);
if ((strcmp(el,"Acceleration")==0)&&(strcmp(attr[0],"a")==0))
sscanf(attr[1],"%f",&m_acceleration);
if ((strcmp(el,"Mass")==0)&&(strcmp(attr[0],"m")==0))
sscanf(attr[1],"%f",&m_mass);
return (NULL);
}
It is a string compare cascade to get the information for the different properties. In the case that the element name is “wheel”, we return a pointer to the wheel because the wheel is the next object that has to process the data. For all the other cases (“Acceleration”, “Mass”) we extract the necessary information and store it in the corresponding member variables. We also return a NULL pointer as we still want to give information to the same object if we did not encounter a wheel. For the wheel, the implementation is also straightforward:
Receiver* Wheel::ProcessData(const char *el, const char **attr)
{
if ((strcmp(el,"Radius")==0)&&(strcmp(attr[0],"r")==0))
sscanf(attr[1],"%f",&m_radius);
return (NULL);
}
One can see that those implementations are not significantly more complex than those of the DOM tree version. However, both have their advantages and disadvantages. The advantages of the SAX model are better than those of the DOM tree. In the following sections these advantages and disadvantages are discussed.
Comparison
In the previous sections we have shown how to use a DOM tree parser and the generally less known SAX parser to read XML data into a game engine. Here we want to compare the two approaches to analyze which method is better suited to which situation.
The implementation that uses the SAX parser is slightly more complex as it needs the dispatcher that travels around the objects as a visitor to gather the information. On the other hand, it is not as complex as one might think after reading the specification of the SAX parser. The dispatcher has only to be implemented once for the whole project. The cascade of string compares in the SAX parser can the program less readable than the DOM version. Eventually, it would make sense to use some macros for the reading process to increase code readability.
One major problem that remains with the SAX parser is that the user who implements the “ProcessData” method has no control over the sequence in which different elements are processed. The processing sequence depends only on the sequence within the XML file. In the DOM tree parser, objects may pick data from arbitrary positions in the DOM tree in arbitrary order. In the context of gaming, this is especially important if the data of one element is necessary to reserve some memory that is used by the upcoming data. One has to make sure that the order within the XML file is correct when an SAX parser is used. This can be a problem when migrating from a DOM tree parser to an SAX parser.
The big advantages of the SAX approach become obvious when it comes to performance. The SAX model is superior when it comes to memory consumption and execution speed. The increase in execution speed stems from the fact that only one pass for getting the data into the engine is used. The effort that is needed to decompile the loaded DOM tree is omitted here as the data is fed directly into the program. The cascade of string compares looks inefficient at first sight. Here, one has to keep in mind that the methods used to get elements from a DOM tree use a string compare internally. Performance-wise the main advantage of the SAX parser is when it comes to memory consumption. The memory needed for the SAX parser is mostly the buffer that is reserved to read the XML file into. The DOM tree parser needs memory to store the complete tree. This tree is not needed any more after the application has grabbed the data from the parse tree and fed into the program. But those trees significantly add to the peak memory consumption during loading. Another serious problem that the SAX parser avoids is memory fragmentation. The allocation of the different elements of the DOM tree may result in several small allocations for the different elements. First the parser reads the DOM tree and does its allocations. Afterwards the objects that make use of the tree do further allocations. Finally, the memory for the DOM tree is freed, leaving big holes in the memory block. The author experienced this phenomenon with a dedicated data format that generated a tree structure in memory from parsing files. To sum up the advantages of the two approaches:
Advantages of SAX
- Low memory consumption
- Low memory fragmentation
- High execution speed
Advantages of DOM
- Easier to understand
- Slightly easier to implement
- Sequence of data in XML file is irrelevant
The advantages of one technique are the disadvantages of the other one and vice versa.
As a final result one can say that applying SAX parsers is useful when performance is an issue or is about to become an issue. Switching from DOM to SAX can require a rework of the code to make sure that the data is fed in the correct order to the respective objects. As performance is always a major issue during development of games, using an SAX parser seems to be mandatory.
Conclusion
In this article we have explained the two basic approaches that exist to parse XML files. Besides the more applied DOM tree model, we have explained how to apply the SAX parser. The application of the SAX parser seems to be more complicated at first sight. In order to overcome the difficulty in adopting the unfamiliar control flow of the SAX parser, we have introduced a concept, based on a visitor pattern, that makes the reading of data into the application easy.
After closer examination, the SAX parser offers a lot of performance advantages that make it especially useful to use with games that have to read a lot of data. With console development one has to face the problems of memory consumption and fragmentation, for which this approach seems ideally suited.
Even if XML data is not used in the final master of the game using the SAX parser during development can significantly reduce turnaround times. It may also become necessary if one uses a development kit with limited memory.
References
[RFC 3076] http://rfc.net/rfc3076.html
[derVlist2002] Eric van der Vlist: XML Schema; 2002 O'Reilly Associates
[XMLSpy] http://www.altova.com/products_ide.html
[W3CR] http://www.w3.org/TR/xslt
[SFTXml] http://sourceforge.net/projects/tinyxml
[SFX] http://sourceforge.net/projects/expat
|