
Скворцов
Павел
Владимирович
группа: СП-06м
e-mail: cyfaws@mail.ru
Тема магистерской работы: "Разработка и исследование решателя уравнений параллельной моделирующей среды на основе OpenMP-стандарта"
Руководитель: проф. Святный В.А.
Автобиография
Автореферат
Перечень ссылок
Отчёт о поиске
Библиотека
Моделирующая программа
ДонНТУ
Магистры ДонНТУ
Mixed Mode programming on Clustered SMP Systems
Authors: Lorna Smith, Mark Bull
Первоисточник: http://www.nesc.ac.uk/events/ahm2003/AHMCD/pdf/173.pdf
Аннотация: Статья о разработке данных приложений. Содержит общую информацию, рекомендации и описание техники "смешанного" программирования для кластерных SMP-систем.
Abstract
MPI / OpenMP mixed mode codes could potentially offer the most effective parallelization strategy for an SMP cluster, as well as allowing the different characteristics of both paradigms to be exploited to give the best performance on a single SMP. This paper discusses the implementation, development and performance of mixed mode MPI / OpenMP applications. While this style of programming is often not the most effective mechanism on SMP systems, significant performance benefit can be obtained on codes with certain communication patterns, such as those with a large number of collective communications.
1. Introduction
Shared memory architectures have gradually become more prominent in the HPC market, as advances in technology have allowed larger numbers of CPUs to have access to a single memory space. In addition, manufacturers have increasingly clustered these SMP systems together to go beyond the limits of a single system. These clustered SMPs have recently become more prominent in the UK, one such example being the HPCx system – the UK's newest and largest National High Performance Computing system, comprising 40 IBM Regatta-H SMP nodes, each containing 32 POWER4 processors. Hence it has become important for applications to be portable and efficient on these systems. Message passing codes written in MPI are obviously portable and should transfer easily to clustered SMP systems. Whilst message passing may be necessary to communicate between nodes, it is not immediately clear that this is the most efficient parallelization technique within an SMP node. In theory, a shared memory model such as OpenMP should offer a more efficient parallelization strategy within an SMP node. Hence a combination of shared memory and message passing parallelization paradigms within the same application (mixed mode programming) may provide a more efficient parallelization strategy than pure MPI. In this paper we will compare and contrast MPI and OpenMP before discussing the potential benefits of a mixed mode strategy on an SMP system. We will then examine the performance of a collective communication routine, using pure MPI and mixed MPI/OpenMP
2. HPCx
HPCx is the UK's newest and largest National High performance Computing system. It has been funded by the Engineering and Physical Sciences Research Council (EPSRC). The project is run by the HPCx Consortium, a consortium involving The University of Edinburgh, EPCC, CCLRC's Daresbury Laboratory and IBM. HPCx consists of 40 IBM p690 Regatta nodes, each containing 32 Power4 processors. Within a node there are 16 chips: each chip contains two processors with their own level 1 caches and a shared level 2 cache. The chips are packaged into a Multi-Chip Module (MCM) containing 4 chips (8 processors) and a 128 Mbyte level 3 cache, which is shared by all 8 processors in the MCM. Each Regatta node contains 4 MCMs and 32 Gbytes of main memory. The MCMs are connected to each other and to main memory by a 4-way bus interconnect to form a 32-way symmetric multi-processor (SMP). In order to increase the communication bandwidth of the system each Regatta node has been divided into 4 logical partitions (LPAR), coinciding with each MCM. Each LPAR runs its own copy of the AIX operating system and operates as an 8-way SMP.
3. Programming model characteristics
The message passing programming model is a distributed memory model with explicit control parallelism. MPI [1] is portable to both distributed and shared memory architecture and allows static task scheduling. The explicit parallelism often provides a better performance and a number of optimized collective communication routines are available for optimal efficiency. Data placement problems are rarely observed and synchronization occurs implicitly with subroutine calls and hence is minimized naturally. However MPI suffers from a few deficiencies. Decomposition, development and debugging of applications can be time consuming and significant code changes are often required. Communications can create a large overhead and the code granularity often has to be large to minimize the latency. Finally, global operations can be very expensive. OpenMP is an industry standard [2] for shared memory programming. Based on a combination of compiler directives, library routines and environment variables it is used to specify parallelism on shared memory machines. Communication is implicit and OpenMP applications are relatively easy to implement. In theory, OpenMP makes better use of the shared memory architecture. Run time scheduling is allowed and both fine and coarse grain parallelisms are effective. OpenMP codes will however only run on shared memory machines and the placement policy of data may causes problems.
Coarse grain parallelism often requires a parallelization strategy similar to an MPI strategy and explicit synchronization is required. By utilizing a mixed mode programming model we should be able to take advantage of the benefits of both models. For example a mixed mode program may allow the data placement policies of MPI to be utilized with the finer grain parallelism of OpenMP. The majority of mixed mode applications involve a hierarchical model; MPI parallelization occurring at the top level, and OpenMP parallelization occurring below. For example, Figure 1 shows a 2D grid which has been divided geometrically between four MPI processes. These sub-arrays have then been further divided between three OpenMP threads. This model closely maps to the architecture of an SMP cluster, the MPI parallelization occurring between the SMP nodes and the OpenMP parallelization within the nodes.
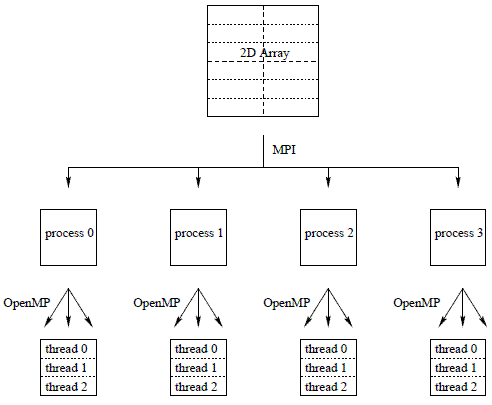
Figure 1: Schematic representation of a hierarchical mixed mode programming model for a 2D array.
4. Benefits of mixed mode programming
This section discusses various situations where a mixed mode code may be more efficient than a corresponding MPI implementation, whether on an SMP cluster or single SMP system.
Codes which scale poorly with MPI
One of the largest areas of potential benefit from mixed mode programming is with codes which scale poorly with increasing MPI processes. One of the most common reasons for an MPI code to scale poorly is load imbalance. For example irregular applications such as adaptive mesh refinement codes suffer from load balance problems when parallelized using MPI. By developing a mixed mode code for a clustered SMP system, MPI need only be used for communication between nodes, creating a coarser grained problem. The OpenMP implementation may not suffer from load imbalance and hence the performance of the code would be improved.
Fine grain parallelism problems
OpenMP generally gives better performance on fine grain problems, where an MPI application may become communication dominated. Hence when an application requires good scaling with a fine grain level of parallelism
a mixed mode program may be more efficient. Obviously a pure OpenMP implementation would give better performance still, however on SMP clusters MPI parallelism is still required for communication between nodes.
By reducing the number of MPI processes required, the scaling of the code should be improved.
Replicated data
Codes written using a replicated data strategy often suffer from memory limitations and from poor scaling due to global communications. By using a mixed mode programming style on an SMP cluster, with the MPI parallelization occurring across the nodes and the OpenMP parallelization inside the nodes, the problem will be limited to the memory of an SMP node rather than the memory of a processor (or, to be precise, the memory of an SMP node divided by the number of processors), as is the case for a pure MPI implementation. This has obvious advantages, allowing more realistic problem sizes to be studied.
Restricted MPI process applications
A number of MPI applications require a specific number of processes to run. Whilst this may be a natural and efficient implementation, this limits the number of MPI processes to certain combinations. By developing a mixed mode MPI/OpenMP code the natural MPI decomposition strategy can be used, running the desired number of MPI processes, and OpenMP threads used to further distribute the work, allowing all the available processes to be used effectively.
Poorly optimized intra-node MPI
Although a number of vendors have spent considerable amounts of time optimizing their MPI implementations within shared memory architecture, this may not always be the case. On a clustered SMP system, if the MPI implementation has not been optimized, the performance of a pure MPI application across the system may be poorer than a mixed MPI / OpenMP code. This is obviously vendor specific, but in certain cases a mixed mode code could offer significant performance improvement. For example, IBM's MPI is not optimized for clustered systems.
Poor scaling of the MPI implementation
Clustered SMPs open the way for systems to be built with ever increasing numbers of processors. In certain situations the scaling of the MPI implementation itself may not match these ever increasing processor numbers or may indeed be restricted to a certain maximum number. In this situation developing a mixed mode code may be of benefit (or required), as the number of MPI processes needed will be reduced and replaced with OpenMP threads.
5. Collective Communications
Having discussed various situations where a mixed mode code may be more efficient than a corresponding MPI implementation, this section considers one specific situation relevant to HPCx: collective communications.
Many scientific application use collective communications and to achieve good scaling on clusters SMP systems such as HPCx, these communications need to be implemented efficiently. Collective communications were included in the MPI standard to allow developers to implement optimized versions of essential communication patterns. A number of collective operations can be efficiently implemented using tree algorithms - including Broadcast, Gather, Scatter and Reduce. On a system such as HPCx, where communication is faster within
a node than between nodes, the tree algorithm can be constructed such that communications corresponding to branches of the tree at the same level should run at the same speed, otherwise the speed of each stage of the algorithm will be limited by the performance of the slowest communication. To demonstrate this, two techniques have been used. Firstly, a library has been used that, by creating multiple communicators, performs collective operations in two stages [3]. For example, an all reduce operation involves a reduction operation carried out across the processors within an LPAR, followed by an all reduce of these results across LPARs. This library uses the MPI profiling interface and hence is easy to use, as it requires no code modification. Secondly, a mixed mode version of the code has been developed that also performs the operation in two stages: stage 1 uses OpenMP and stage 2 MPI. For example, an all reduce operation involves a reduction operation carried out using OpenMP across threads within and LPAR, followed by an MPI all reduce operation of these results across LPARs. To ensure the
MPI and OpenMP operations are comparable, the OpenMP reduction operation is carried out across variables that are private to each thread. To avoid the use of an ATOMIC directive, all the private variables are copied to a different piece of a shared array, based on their thread identifier. The contents of this shared array are then reduced into a second shared array by the master thread. The master thread on each LPAR is then involved in an MPI all reduce operation across LPARs. A simple benchmark code, that executes an all reduce operation across a range of data sizes, has been used to compare the performance of these two techniques to carry out a reduction operation against the standard all reduce operation of the IBM MPI library. Figure 2 shows the performance (in bytes/s) for each operation on a range of data sizes on 32 processors. It is clear from this diagram that the two-stage operation, using multiple communicators, is significantly faster than the standard MPI operation for all data sizes. As mentioned above, the collective operation is dominated by its slowest communication. The slowest communication within the standard MPI operation is communication between LPARs and this is dominating the performance. By carrying out this process in two stages, the amount of data being communicated between LPARs has reduced significantly, hence reducing the execution time of sending messages between LPARs. For small data sizes, the two-stage mixed operation is faster again than the two-stage operation using multiple communicators. This operation also reduces the amount of data being communicated between LPARs, reducing
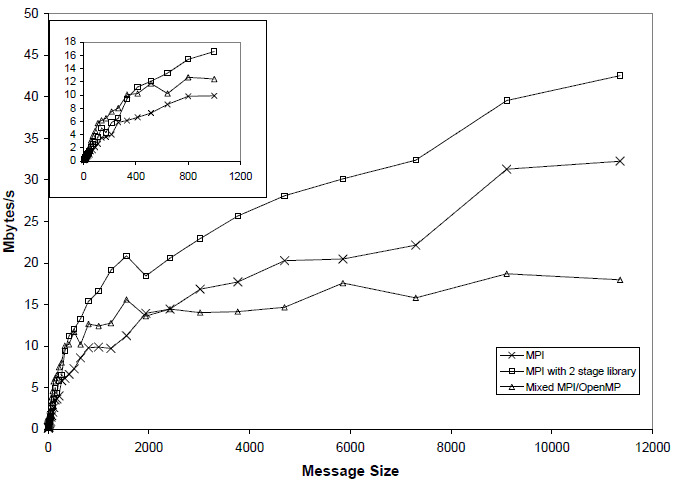
Figure 2: Performance in Mbytes/s of the two stages all reduces operations and the standards all reduce operation of the IBM MPI library.
the execution time for sending messages between LPARs. In addition, this operation benefits from carrying out communication within an LPAR through direct read and writes to memory (using OpenMP), which eliminates the overhead of calling the MPI library. For larger data sizes however, the performance of this mixed operation is worse than both the original MPI operation and the operation with two stage MPI library.
6. Conclusions
For applications that are dominated by collective communications, the two-stage MPI library offers a simple and quick mechanism to obtain significant performance improvement. Using a mixed MPI/OpenMP version of the collective communication improves the performance for low data sizes, but has a detrimental effect for larger data sizes.
References
[1] MPI, MPI: A Message-Passing Interface standard. Message Passing Interface Forum, June 1995.
http://www.mpi-forum.org/.
[2] OpenMP, The OpenMP ARB.
http://www.openmp.org/.
[3] Developed by Stephen Booth, EPCC.
Автобиография
Автореферат
Перечень ссылок
Отчёт о поиске
Библиотека
Моделирующая программа
ДонНТУ
Магистры ДонНТУ