
Скворцов
Павел
Владимирович
группа: СП-06м
e-mail: cyfaws@mail.ru
Тема магистерской работы: "Разработка и исследование решателя уравнений параллельной моделирующей среды на основе OpenMP-стандарта"
Руководитель: проф. Святный В.А.
Автобиография
Автореферат
Перечень ссылок
Отчёт о поиске
Библиотека
Моделирующая программа
ДонНТУ
Магистры ДонНТУ
Performance of Cluster-enabled OpenMP for the SCASH Software Distributed Shared Memory System
Authors: Yoshinori Ojima, Mitsuhisa Sato, Hiroshi Harada, Yutaka Ishikawa
Дата публикации: 2003
Первоисточник: http://ieeexplore.ieee.org/iel5/8544/27003/01199400.pdf
Аннотация: OpenMP has attracted widespread interest because itis an easy-to-use parallel programming model for sharedmemory multiprocessor systems. Implementation of a"cluster-enabled" OpenMP compiler is presented.
Abstract
OpenMP has attracted widespread interest because it is an easy-to-use parallel programming model for shared memory multiprocessor systems. Implementation of a “cluster-enabled” OpenMP compiler is presented. Compiled programs are linked to the page-based software distributed-shared-memory system, SCASH, which runs on PC clusters. This allows OpenMP programs to be run transparently in a distributed memory environment. The compiler converts programs written for OpenMP into parallel programs using the SCASH static library, moving all shared global variables into SCASH shared address space at runtime. As data mapping has a great impact on the performance of OpenMP programs compiled for software distributed-shared-memory, extensions to OpenMP directives are de.ned for specifying data mapping and loop scheduling behavior, allowing data to be allocated to the node where it is to be processed. Experimental results of benchmark programs on PC clusters using both Myrinet and fast Ethernet are reported.
1. Introduction
The performance of a “cluster-enabled” OpenMP compiler for a page-based software distributed-shared-memory system, SCASH, running on a cluster of PCs is presented. In recent years, cluster systems consisting of workstations connected by networks such as Ethernet and Myrinet are commonly used as parallel computing platforms. For programming distributed-memory multiprocessor systems, such as clusters of workstations, message passing is usually used. However, message passing systems require explicit coding of inter-processor communications, making parallel programs dif.cult to write.
OpenMP has attracting widespread interest as an easy to use model for parallel programming. Using OpenMP, a program can be parallelized in a stepwise fashion, without signi.cant changes to the existing sequential structure. Thus, the cost of parallelizing a program can be reduced. Although OpenMP was designed as a model for hardware shared-memory systems, OpenMP can be supported in a distributed-memory environment using a software distributed- shared-memory system (SDSM).
The SDSM used is a page-based software distributedshared- memory system, SCASH[2], which is part of the SCore cluster system software[3]. In most SDSMs, only part of the address space of a process is shared. In SCASH, a shared memory allocation primitive is supported for allocating memory explicitly to be shared among processors. Thus, variables declared in the global scope are private within a process. We call this memory model the “shmem memory model”, as this is the model of the Unix “shmem” system call. In this model, all shared variables must be allocated at run-time at the beginning of program execution. An implementation of the OpenMP compiler applied to the “shmem memory model” was created using the Omni OpenMP compiler system[7]. This compiler detects references to shared data objects, and rewrites them as references to objects in shared memory. We call this implementation Omni/SCASH.
The mapping of data to processors is very important for achieving good performance in SDSM. A set of compiler directives was implemented to specify data mappings and loop scheduling to provide application-speci.c information to the compiler. Using these extended directives, a programmer can exploit data locality, thus reducing the cost of consistency management.
The performance of Omni/SCASH was measured on a cluster connected by Myrinet and fast Ethernet. Although Myrinet is a Giga-bit class, high-speed network developed speci.cally for high-performance computing, fast Ethernet is currently the most commonly used network for PC cluster, and so is also of interest.
2. SCASH Software Distributed Shared Memory System
SCASH is a page-based software distributed-sharedmemory system that uses the PM low-latency highbandwidth communication library for both Myrinet and Ethernet networks, as part of the SCore cluster-system software. The consistency of shared memory is maintained on a per-page basis. SCASH is based on the Eager Release Consistency (ERC) memory model using the multiple writer protocol. In the ERC memory model, the coherence of shared memory is maintained using memory barrier synchronization. Using this scheme only modi.ed regions of memory are transferred during page updates. SCASH make use of the unidirectional ”zero-copy” mode of communication available in PM. This reduces memory copy overhead in the remote page copy functionality of the page fault handler, and avoids any interruptions on the sender’s side. SCASH supports two protocols for keeping pages coherent, invalidate and update. The home node of a page is the node to which that page is assigned, and always has the most up-to-date page data. The invalidate protocol is used by the home node of a page to notify other nodes that are sharing the page that the data has changed. This is done using invalidation messages sent by the home node. The invalidate protocol is used in the implementation of Omni/SCASH.
Explicit data consistency management primitives are also supported for the lock operations. The SCASH API provides blocking and non-blocking functions for locking pages, with these function implemented using a distributed lock queue. Other functionality provided by the SCASH API includes broadcasting of global memory data and the allocation of home nodes for memory pages. SCASH is implemented entirely as a statically linkable runtime library. 3 Translation of OpenMP Programs to SCASH 3.1. The Omni OpenMP Translation System
The Omni compiler translates OpenMP programs written in C or Fortran77 to multi-threadedC programs linked to the SCASH runtime library. C-front and F-front are frontends for parsing C and Fortran source code into an intermediate code, called Xobject. A Java class library, Exc Java Toolkit, has been designed that provides classes and methods to allow a program to be easily analyzed and modi.ed using a high level representation. Xobject code is represented using an AST (Abstract Syntax Tree) in which data type information is included, and each node is a Java object representing a syntactical element of the source code. Xobject code can then be easily transformed. The program for converting an OpenMP program to multi-threaded C code was written in Java using the Exc Java toolkit. The resulting C program is then compiled by the native compiler of the platform and linked with the runtime library.
3.2. Translation to the shmem memory model
In the OpenMP programming model, global variables are shared by default, whereas in SCASH, variables declared in the global scope remain private within a process. Shared address space must be allocated explicitly at runtime using the shared memory allocation primitive. To translate an OpenMP program to use the SCASH shmem memory model, the source code is rewritten such that space is allocated in shared memory at runtime for storing global variables. Thus, OpenMP programs are transformed using the following steps:
1. All declarations of global variables are changed to global variable pointers, which point to a region in shared address space where the actual global variables are stored.
2. All references to global variables are changed to indirect references via the corresponding pointers.
3. A global data initialization function is generated for each compilation unit. These functions allocate the necessary global variables in shared address space and stores the addresses of these in the corresponding global variable pointers.
For example, the following code:
/* global variable declaration */
double x;
/* global array declaration */
double a[100];
...
a[10] = x;
is transformed into:
/* indirect pointer to "x" */
double *_G_x;
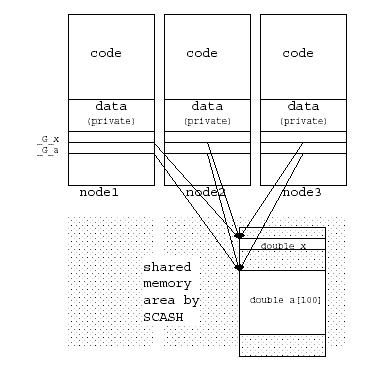
/* indirect pointer to "a" */
double *_G_a;
...
/* reference through the pointers */
(_G_a)[10] = (*_G_x);
The following initialization function __G_DATA_INIT
is generated for the above code:
static int __G_DATA_INIT() {
_shm_data_init(&_G_x,sizeof(double));
_shm_data_init(&_G_a,sizeof(double)*100);
}
The size and address of the global variable pointer are p assed to the _shm_data_init runtime library function. The initialization function also contains any data mapping information speci.ed in the program. Figure 1 gives an illustratation of the code after this conversion.
Global data initialization function entry points are linked into to the ‘.ctors’ section, and are thus called at the start of program execution, prior to “main” being executed. The global variable initialization function does not actually allocate memory, but builds a list of objects to be shared at the node. During SCASH initialization, shared objects are allocated in the shared address space of the master processor (node 0) using this list. Addresses allocated to the objects are then broadcast to each node, allowing the initialization of global variable pointers in each node.
3.3. OpenMP Directive Translation and the Runtime Library
OpenMP compiler directives are translated into SCASH runtime functions for synchronization and communication between processors.
To transform a sequential program containing parallel processing directives into a fork-join parallel program, the compiler moves each section of parallel code into a separate function. The master node then calls a runtime function to invoke slave threads to execute the function in parallel. Threads in each node are created when parallel execution is required, with execution suspended until all threads are ready to run. Nested parallel processing is not supported. In SCASH, all shared memory regions are synchronized at barrier points, similar to the OpenMP memory model. OpenMP lock and synchronization operations are performed explicitly using SCASH consistency management primitives.
From a programming point of view, our implementation of SDSM is almost compatible with hardware-supported SMP, with only a few exceptions.
3.4. OpenMP Extensions for Data Mapping and Loop Scheduling
In SDSMs, the allocation of pages to home nodes greater affects performance because the cost of maintaining coherency between nodes is much higher thin in hardware non-uniform memory access (NUMA) systems. In SCASH, referencing a page that is stored on a remote node causes the page to be transferred across the network. If a page is modi .ed by any node other than the home node, modi.cations are detected and transferred to the home node to update the master copy when barrier points are reached. SCASH can deliver high performance to OpenMP programs if data is located such that that data needed for computations by a particular thread is located on the same node as the thread. In OpenMP, a programmer can specify thread-parallel computation, but the memory model assumes a single memory space and provides no facilities for specifying how data is to be arranged within the memory space. In addition, there are no loops cheduling methods to de.ne the way in which data is passed between iterations.
An extension to the OpenMP compiler directives has
thus been developed to allow the programmer to specify the
arrangement of data and computations across the shared address
space. A data mapping directive was added to allow
the mapping pattern of array objects in the address space
to be speci.ed, similar to High Performance Fortran (HPF).
For example, the following directive speci.es block mapping
in the second dimension of a two-dimensional array A
in C:
double A[200][100];
#pragma omni mapping(A[block][*])
The asterisk (*) for the .rst dimension means that the elements in any given column should be mapped into memory in the same node. The block keyword for the second dimension means that for any given row, the array elements should be mapped across nodes in large blocks of approximately equal size. Consequently, the array is divided into contiguous groups of columns, with each group assigned the same home node. The keyword cyclic(n) can be used to specify cyclic mapping. The alignment mapping directive is also provided to match the data mapping of one array with other arrays.
As allocation of home nodes is performed on a pagebasis in SCASH, shared memory consistency is only supported at page-granularity. Thus, mappings that specify granularities .ner than the size of a page may not have any effect. In contrast to HPF, each processor may have access to the entire copy of the array in the same shared address space. In this sense, the directive is a “mapping” rather than a “distribution”, as in HPF.
In addition to the data mapping directive, a new loop
scheduling clause, “af.nity”, has been implemented so that
loopiterations are scheduled to threads to which the data is
mapped. For example, in the following code, execution of
the loopis divided between threads according to the division
of array elements a[i][*] across home nodes:
#pragma omp for schedule(affinity,a[i][*])
for(i = 1; i < 99; i++)
for(j = 0; j < 200; j++)
a[i][j] = ...;
Bricak et al[4] have proposed similar extensions to OpenMP for NUMA machines. Compared to the omni system, whic only supports one-dimensional mappings with page granularity, the proposed extensions support multidimensional mappings and element-wise granularity by exchanging dimensions. The SGI OpenMP compiler supports similar extensions, allowing the speci.cation of data mappings and loop scheduling af.nity.
4 Performance of Omni/SCASH
4.1. Performance Results and Platform Dependence
Performance tests were conducted on a COSMO Cluster consisting of 8 COMPAQ ProLiant 6500 nodes, with each node consisting of 4 Pentium II 450 MHz processors with 256 KB of L2 cache and 2 GB of main memory. Two out of each of the four processors of each node were used. Nodes are connected by both 800Mbps Myrinet and 100base-TX Ethernet. The cluster is running under SCore 5.0.1 and Linux kernel 2.4.18. Omni OpenMP compiler 1.4a with optimization option -O4 was used to compile the benchmark programs described below.

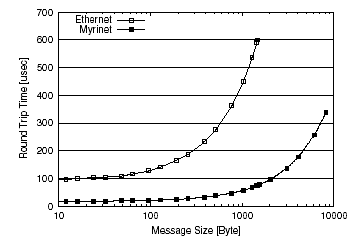
Communication bandwidth and round-tripl atency were measured using “pmbench” which is a benchmark program to measure performance of network using PM library. The results are shown in Figure 2, and 3. When the message size is 1 KB, bandwidth and latency for Myrinet was around 70 MBps and 60 microseconds, and that for Ethernet of around 12.5 MBps and 450 microseconds.
To measure the page transmission cost of SCASH, a master-slave test program was constructed as follows. A one-dimensional array of 32 KB is allocated in shared address space, and is mapped using block distribution. The master thread, which is assigned to processor 0, writes to every element in an array which is followed by a barrier point. At the barrier point, pages assigned that are assigned to different nodes and have been modi.ed are copied back to their home nodes. Execution time from the beginning of the array write operation to completion of the barrier is shown in Figure 4.
To measure the overhead of barrier operation of SCASH, a master-slave test program was constructed as follows. A two-dimensional array of 256 KB is allocated in shared address space, and is mapped using block distribution. The

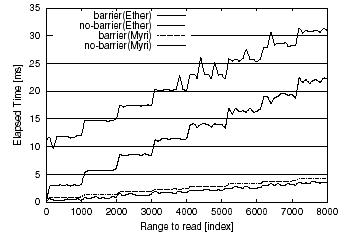
slave threads read every element mapped to master threads which is followed by a barrier point. In Figure 5, the line labeled ’no-barrier’ shows the execution time from the beginning of the array read operation to completion of the operation and the line labeled ’barrier’ shows the execution time from begining of the operation to completion of the barrier. At the barrier point, no consistency maintenance communication is needed. So the difference of two lines shows the overhead of a barrier operation.
As shown in the .gure, the page transmission cost per page with Myrinet is about 0.24 msec, is very stable, and increases in a stepwise fashion. For Ethernet, however, execution time averages around 9 msec, with large .uctuations. This is because the implementation of the SCASH barrier operation generates large overhead in the case of Ethernet. Although the performance of the barrier operation in Ethernet itself is about 9 msec, strange behavior was found during page transmission in barrier operations. This is because SCASH uses all-to-all barrier algorithm. In the algorithm all threads broadcasts a message simultaneously, so it is thought that the message has collided and the elapsed time has not been stable.


4.2. Overhead of OpenMP translation and Optimization with Affinity Scheduling
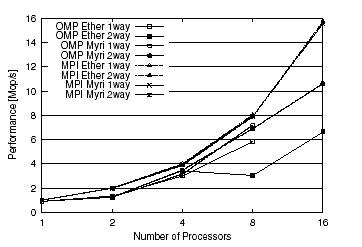
To measure the overhead of converting OpenMP programs to SCASH, the performance of an Omni/OpenMP program was compared to that of a similar program written directly using the SCASH library. The program “laplace” is a simple Laplace equation solver written in C using a Jacobi 5-point stencil operation. The number of iterations is .xed at 50. Matrix size is 1024 x 1024, with double precision .oating points used as matrix elements. Figure 6 and 7 show execution times achieved using Myrinet and Ethernet for a various number of processors. The line labeled ’SCASH’ shows execution times obtained using the SCASH library directly, and the line labeled ’OMP’ shows the execution time of Omni/SCASH programs.
To examine the impact on performance of data mapping and affnity loopdi rectives, the Omni/SCASH program was modified to use af.nity scheduling, as shown by the line labeled ’OMP-afn’. In this case, affinity scheduling was not found to improve performance significantly. For comparison, the performance of the MPI program is also shown in the figures. The difference is quite large, es-

pecially when the number of processors is small, and when using the Ethernet. This may be due to the slowness of barrier operations over Ethernet, as noted in the previous subsection. In the case of Myrinet, the performances of all the programs became closer as the number of processors was increased to 16.
In all programs, execution times achieved using two processors per node were slower than using a single processor. This is because the performance of the dual processor nodes is limited by memory bandwidth.
4.3. Performance of NPB BT, SP and EP
The BT, SP and EP programs from version 2.3 of the NAS parallel benchmark suite were parallelized using OpenMP directives. For parallelization, OpenMP directives were added without any other modi.cations to the original code. Unnecessary barrier operations were eliminated by adding “nowait” clauses to some parallel loops to reduce unnecessary synchronization traf.c. For variables that are referenced locally within a thread, the variable “threadprivate” was de.ned to reduce the amount of shared data. In addition, data mapping directives and af.nity loop scheduling were used to improve performance.
Figures 8, 9 and 10 show execution times of the BT, SP and EP benchmarks for Myrinet and Ethernet. For comparison, ’MPI’ indicates the performance of the MPI versions as provided with the standard NAS parallel benchmark suite. The problem size is class A. Although OpenMP version and MPI version perform same the same caluculation, since they are fundamentally different programs, they are compared for the reference. We measured BT and SP of the MPI version on 1,4,9, and 16 processors because of restriction of the programs.
The BT benchmark scales better than the SP benchmark because BT contains more computations than SP. BT and SP are similar in many respects. Both benchmarks solve multiple independent systems in three dimensional

space which are stored in multi-dimensional arrays. Each sub-dimension of the array is accessed in three phases: x_solve, y_solve and z_solve. To parallelize these programs, the arrays are mapped using block mapping on the largest dimension. Although this mapping makes two routines, x_solve and y_solve faster, the z_solve routine does not scale, especially in SP, because the data mapping does not match the access pattern of the routine. It is noted that in some cases, especially BT, Omni/SCASH achieved better performance than MPI. Unfortunately, good performance and scalability were not achieved when using Ethernet due to the large overhead of SCASH.
5 Related Work
H. Lu, et.al. [6] have presented an OpenMP implementation for the TreadMarks[1] software DSM. Although, the compiler only supports a subset of OpenMP, modi.cations to the OpenMP standard were proposed to make OpenMP programs run more efficiently. This approach may result in the loss of portability of OpenMP programs. Our compiler supports the full set of OpenMP directives so that OpenMP compliant programs can run on SDSMs without modification. In this paper, the serial version of the NAS parallel benchmarks were parallelized without making any modi.- cations to the original code. PBN (Programming Baseline for NPB)[5] is a new OpenMP benchmark suite, part of the NAS parallel benchmarks published by the NASA Ames Lab. Programs in this suite are optimized from NPB 2.3 for OpenMP.
Keleher and Tseng have combined the SUIF parallelizing compiler and CVM software DSM[9]. They presented techniques for reducing synchronization overhead based on compile-time elimination of barriers. Results show that the performance of DSM system can approach that of message passing system by a few simple enhancements to the compiler/ system interface.
6 Conclusion and Future Work
An implementation of “cluster-enabled” OpenMP, Omni/SCASH, was presented, enabling OpenMP programs to be run transparently in cluster environments. As mapping of pages to home nodes is one of the keys to achieving good performance in the SDSM, a set of data mapping directives were supported, allowing an application to pass relevant implementation information to the compiler. Loop scheduling to exploit locality of data mappings can be used to tune performance by reducing the cost of synchronization. Performance of Omni/SCASH on clusters of both Myrinet and Ethernet was tested. Although good performance was achieved on Myrinet, with the exception of the EP benchmark, which involves low communication to computation, performance over Ethernet was poor. When using Omni/SCASH in Ethernet-based cluster, it is therefore important to know how much communication is required to estimate performance. In the case of Ethernet, barrier operations were found to generate large overhead, so that page transmissions cost over ethernet were about 6 times that in Myrinet. Since fast Ethernet is a very commonly used network, we believe it is worth investigating ways of improving the ef.ciently of Omni/SCASH over Ethernet. We are currently working on performance analysis and improvement to SCASH over Ethernet.
Since networks communications involved in shared memory systems are triggered implicitly and are transparent to the programmer, it is generally dif.cult to analyze a program using SDSM. To improve the performance of a program, the locations of bottlenecks need to be analyzed . We thus intend to developp erformance tuning tools, such as performance counters and a pro.ler, to make performance tuning easier.
Acknowledgement
We wish to thank all members of Omni OpenMP compiler project for their fruitful discussion and support. This research was partially supported by the Ministry of Education, Culture, Sports, Science and Technology, Grand-in-Aid for Scienti.c Research (A), 14208026, 2002.
References
[1] C. Amza, A. Cox, S. Dwarkadas, P. Keleher, H. Lu, R. Rajamony, W. Yu,W. Zwaenepoel. “Treadmarks: Shared memory computing on networks of workstation”, IEEE Computer, 29(2):18-28, Feb. 1996.
[2] H. Harada, Y. Ishikawa, A. Hori, H. Tezuka, S. Sumimoto, T. Takahashi, “Dynamic Home Node Reallocation on Software Distributed Shared Memory”, In Proc. of HPC Asia 2000, pp. 158–163, Beijing, China, May, 2000.
[3] A. Hori, H. Tezuka and Y. Ishikawa. “Highly Ef.cient Gang Scheduling Implementation”, SC’98 (CD-ROM),Nov. 1998. See also http://www.pccluster.org
[4] J. Bircsak, P. Craig, R. Crowell, Z. Cvetanovic, J. Harris, C.A. Nelson and C.D. Offner. “Extending OpenMP For NUMA Machines”, SC2000 (CD-ROM), Nov. 2000.
[5] H. Jin, M. Frumkin and J. Yan. “The OpenMP Implementation of NAS Parallel Benchmarks and Its Performance”, NAS Technical Report NAS-99-011,Oct., 1999.
[6] H. Lu, Y. C. Hu, W. Zwaenepoel. “OpenMP on Network of Workstations”, SC’98 (CD-ROM), Nov. 1998.
[7] M. Sato, S. Satoh, K. Kusano, Y. Tanaka. “Design of OpenMP Compiler for an SMP Cluster”, In Proc. of 1st European Workshop on OpenMP (EWOMP’99), pp. 32-39, Lund, Sweden, Sep. 1999. See also http://www.hpcc.jp/Omni/
[8] H. Tezuka, A. Hori, Y. Ishikawa and M. Sato. PM: An Operating System Coordinated High Performance Communication Library. Lecture Note in Computer Science, High- Performance Computing and Networking, pages 708–717, 1997.
[9] P. Keleher and C. Tseng. “Enhancing Software DSM for Compiler-Parallelized Applications”. 11th International Parallel Processing Symposium (IPPS’97), Geneva, Switzerland, April 1997.
Автобиография
Автореферат
Перечень ссылок
Отчёт о поиске
Библиотека
Моделирующая программа
ДонНТУ
Магистры ДонНТУ