| Назад в библиотеку |
|
| B. Chandra, Indian Institute of Technology, New Delhi, India bchandra104@yahoo.co.in |
Sati Mazumdar , Vincent Arena University of Pittsburgh, Pittsburgh, USA maz1@pitt.edu |
and N. Parimi NSIT, New Delhi. |
Деревья решений являются очень оффективными для решения задач классификации в датамайнинге. Данная статья рассматривает модификацию SLIQ алгоритма деревьев решений (Mehta и др.,1996). Недостаток этого алгоритма заключается в том, что на каждом шаге нужно вычислять большое количество индексов в каждом узле дерева решений. Для того чтобы определить какой атрибут должен быть разделен в каждом узле, индексы должны быть вычислены для всех атрибутов и для всех пар значений для всех паттернов, которые не были классифицированы. Модификация SLIQ алгоритма предлагает снизить сложность вычислений. В этом алгоритме индексы вычисляются не для всех пар значений атрибутов, а через разные уровни значений атрибутов. Точность классификации по этой технологии сравнивалась с точностью SLIQ алгоритма и технологией нейронных сетей на трех реальных наборах данных. В результате выявилось, что деревья решений, построенные с использованием предложенной модификации, показали значительно более лучшую точность классификации, чем алгоритм SLIQ и даже нейронные сети. В целом, было выявлено, что данная модификация алгоритма не только уменьшает количество необходимых вычислений, но и приводит к большей точности классификации.
Классификация данных - одна из важных задач датамайнинга. Множество методов классификации были предложены со времени основания деревьев решений и нейронных сетей. CART (Breiman и др., 1984) - это один из популярных методов построения деревьев решений, но он в целом не дает лучших результатов при классификации нового набора данных, так как слишком подогнанных. ID3 алгоритм деревьев решений - был предложен Куинланом (Quinlan) в 1981 году и имеет несколько модификаций, среди которых C4.5 (Quinlan,1993). Алгоритм ID3 направлен на то, как выбрать наиболее подходящий атрибут в каждом узле дерева решений. Определяется единица измерения названная Gain, которая вычисляется накаждом узле. Атрибут с наибольшим Gain выбирается как разделяющий атрибут.
Один из главных недостатков алгоритма ID3 касается использования основания для выбора атрибута. Выбор разделяющего атрибута происходит с предпочтением атрибутов с большим количеством отдельных значений. Этот недостаток преодалевается в некоторых модификациях при помощи введения новой единицы измерения называемой коэффициент Gain, который берет информацию из классификации полученной от разделения на основании текущего атрибута. Gini индексы используются как альтернатива коэффициенту Gain и применяются в SLIQ алгоритме (Mehta и др.,1996). ID3 также неадекватен при обработке потерянной или зашумленной информации. Некоторые модификации были разработаны с целью преодолевания этих препятствих. Таковые появляются в алгоритме SLIQ.
В случае SLIQ - алгоритм вычисляется для каждого атрибута на каждом узле. В данной статье рассматривается модификация SLIQ алгоритма под названием Изящный алгоритм деревьев решений и приводится доказательство, что данная модификация не только уменьшает количество необходимых вычислений, но и приводит к большей точности классификации по сравнению с оригиналом.
SLIQ (Supervised Learning In Quest) и SPRINT (Shaefer и др., 1996) был разработан группой Quest team из IBM. SPRINT изначально носил цель на разпараллеливание SLIQ. Дерево составляется при помощи разделения одного из атрибутов на каждом уровне. Базовая цель - сгенерировать дерево наиболее соответствующее прогнозу. Вводятся Gini индексы, показатель разветвленности дерева. С их помощью решается какой атрибут будет разделен и какая будет точка разделения атрибута. Gini индексы уменьшаются на каждом шаге, поэтому дерево становится менее разветвленное. Класс гистограмм строится для каждой успешной пары значений атрибутов. В любом отдельном узле после получения всех гистограмм для всех атрибутов Gini индексы просчитываются для каждой гистограммы. Та из них, которая получит наименьший индекс получает точку разделения Р для рассматриваемого узла. Метод расчета Gini индексов для гистограммы из примера с двумя классами - А и В - приведен ниже:
Таблица 1 - Пример класса гистограмм
| Значение атрибута< P | A | B |
| L | a1 | a2 |
| R | b1 | b2 |
P - разделяющее значение атрибута
a1 - показывает количество атрибутов, которые меньше чем Р и принадлежат классу A
a2 - показывает количество атрибутов, которые меньше чем Р и принадлежат классу В
b1 - показывает количество атрибутов, которые больше чем Р и принадлежат классу A
b2 - показывает количество атрибутов, которые больше чем Р и принадлежат классу В
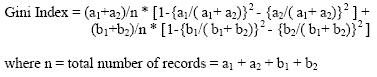
Используя эту формулу, расчитыватся Gini индексы для каждой гистограммы для каждого атрибута. Когда Gini индекс для каждой гистограммы известен, разделяющий атрибут выбран и значение разделения равняется разделяющей точке Р для данной гистограммы. Критерий остановки - случай когда Gini индексы в узле становятся равными 0, что означает, что все данные из данного узла успешно классифицированы.
SLIQ предлагает сканировать каждый атрибут и каждое значение принадлежащее атрибуту для определения наилучшего разделения. Однако в случае работы с большими базами данных с многочисленными записями данный процесс сканирования приводит к большим временным затратам. В модификации алгоритма предлагается вместо вычисления Gini индексов для каждого значения в атрибуте, производить вычисления в конкретном фиксированном интервале значений атрибута. Например, вычисления могут проводиться на интервале 10% от количества записей в каждом узле. Это позволяет значительно сократить объемы и время вычислений. В SLIQ общее количество вычислений в узле вычисляется как произведение количества атрибутов (n) и количества записей в узле (m). В модификации алгоритма общее количество вычислений в узле вычисляется является произведением количества атрибутов (n) и количества групп g=m/k (интервал / размер группы). Следует отметить, что так как количество неклассифицированных паттернов с каждым шагом меняется, следует подбирать другое наиболее подходящее значение размерности групп k. От выбора значения k зависят получаемые результаты вычислений.
Алгоритм
Входные данные : Тренировочный набор, примеры состоят из атрибутов A1 – An и записей R1 – Rm. num - это номер группы в коротом находится атрибут, используется для расчета Gini индексов.
attr stores the splitting attribute
ginival stores the final gini index
splitval stores the final splitting value of attribute attr
Assumed to be c no. of classes
//initializations
ginival = infinity // high value
splitval = 0
attr = 0
Copy records R1– Rm from samples to data.
Maketree(data)
{
Классификация была проведена на основании оригинального алгоритма SLIQ, Изящного алгоритма деревьев решений и нейронных сетей по трем наборам данных.
Первы набор данных (107 записей, или патернов) для тестирования базируется на наборе из 15 атрибутов. Результат ясляется логическим значением и представляется нулем или единицей. Деревья решений были построены с использованием оригинального алгоритма SLIQ, Изящного алгоритма деревьев решений используя 87 записей для тренировки. Оставшиеся 20 записей были использованы для тестирования точности классификации алгоритмов.
Все наборы данных также использвались для тренировки нейросети. Для классификации был использован алгоритм обратного прохода (Rumelhart, 1986). Используемая модель состоит из 15 входящих нейронов и 2 исходящих.
Результаты сравнения классификации с использованием вышеупомянутых трех алгоритмов на основании тестовых наборов данных приведены ниже.
Таблица 2. Сравнение точности классификации с использованием различных алгоритмов
| Технология классификации | SLIQ | Изящное дерево решений | Нейронные сети |
| Данные о загрязнении воды | 60% | 80% | 70% |
| Данные прогноза погоды | 75% | 100% | 90% |
| Данные графического образа | 75% | 95% | 90% |
Из полученных результатов видно, что Изящный алгоритм деревьев решений дает лучшую точность классификации чем оригинальных алгоритм SLIQ. Новый алгоритм дает лучшие результаты, чем даже нейронные сети.
Данная статья представила Изящный алгоритм деревьев решений, который является модификацией алгоритма SLIQ. Главное усовершенствование нового алгоритма - уменьшение объема вычислений Gini индексов в каждом узле дерева, что одновременно привело к повышению результатов точности классификации. Результаты применения алгоритма на трех тестовых наборах данных показывают, что данный алгоритм дает лучшую точность классификации чем оригинальных алгоритм SLIQ и даже нейронные сети.
|