Email:gorunova.elena@gmail.com
По мере развития компьютерных систем становится все более очевидным, что использование этих систем намного расширится, если станет возможным использование человеческой речи при работе непосредственно с компьютером, и в частности станет возможным управление машиной обычным голосом в реальном времени, а также ввод и вывод информации в виде обычной человеческой речи. Взаимодействие человека с компьютером в естественной форме, подобной общению между людьми, является одной из самых важных и сложных задач искусственного интеллекта. Ею стали с энтузиазмом заниматься еще на заре возникновения информатики как науки так же, как и задачей автоматического перевода с одного языка на другой. Существующие модели понимания речи пока еще значительно уступают речевым способностям человека, что свидетельствует об их недостаточной адекватности и ограничивает применение речевых технологий в промышленности и быту. Естественные языки оказались значительно более сложным объектом, чем это казалось с самого начала. В частности, распознавание устной речи человеком в значительной степени основывается на умственной деятельности, связанной с осмыслением в реальном времени содержания произносимого. Известно, что без этого человек способен правильно идентифицировать не более 30 % услышанного потока фонем. Однако он способен повторить слово, которое четко произнесено на незнакомом языке (конечно, интерпретируя звуки в рамках привычной для него фонетической системы). И это означает, что пофонемное распознавание все-таки должно приниматься за основу, если мы не хотим ограничиться распознаванием слов по эталонам, то есть работать на уровне звуковых иероглифов. Данная работа направлена на разработку системы пофонемного распознавания русской речи, в частности, фонем «Ж» и « З», обеспечивающей дикторонезависимый ввод русской речи.
Работы в области систем распознавания речи имеют уже довольно долгую историю и в настоящее время они не только не потеряли актуальности, но и развиваются широким фронтом, находя для себя множество областей для практического применения.
Такие системы весьма полезны на практике, и необходимость в них постоянно растёт. В первую очередь это связано с появлением большого количества доступных человеку разнообразных устройств (персональные, мобильные и карманные компьютеры, коммуникаторы и мобильные телефоны, игровые и многофункциональные мультимедийные устройства с достаточной вычислительной мощностью), с которыми ему приходится взаимодействовать.
При традиционно высокой значимости информации, поступающей к нам через органы зрения, и её высокой доле (порядка 85%) среди всей сенсорной информации, этот канал восприятия человека становится в значительной степени перегружен. Первоочередной альтернативой здесь видится коммуникация именно по акустическому каналу. Кроме того, системы распознавания речи крайне важны для людей с ограниченным зрением. Это направление активно развивается прежде всего в области мобильной телефонии (малые размеры экранов телефонных аппаратов не дают таким людям возможности пользоваться ими с достаточной степенью комфорта), а также в бытовой технике (для управления разнообразными домашними устройствами). Для помощи таким людям производители вводят в свои устройства возможности управления посредством голосовых команд (при наборе номера в телефоне или во время навигации по пунктам меню), а также дублирования экранной информации голосом.
В целях повышения эффективности работы современных систем распознавания речи, использующих русские фонемы, в магистерской работе реализован алгоритм фонемного распознавания «Ж» и «З», который показал лучшие результаты по сравнению с ранее существовавшими аналогами. Разработана система, которая является важнейшим элементом общей системы распознавания.
Практическое значение полученных результатов
Проблема дикторонезависимого распознавания речи является актуальной. Уже многие годы голосовые команды являются одной из возможных опций программного обеспечения персональных компьютеров — это типичный пример использования техники распознавания речи. Включение функций распознавания речи в некоторые системы и текстовые процессоры — уже давно не новость на рынке программных продуктов. Многие коммерческие программы распознавания речи хорошо работают в системах речевых услуг, от справочных столов до записи медицинских процедур. Эта технология повысила эффективность работы телефонных центров обработки заказов и позволила многим компаниям увеличить объемы сделок и расширить свой бизнес. Рынок систем распознавания голоса рос и продолжает увеличиваться с впечатляющей скоростью. Одна из причин такого бурного роста — потребность в этой технологии обычных пользователей современных компьютеров. Росту также способствуют значительное увеличение вычислительной мощности и доступные объемы памяти среднего настольного персонального компьютера. Теперь нет никаких проблем с техническим обеспечением, необходимым для работы систем распознавания голоса. А увеличение количества поставщиков этой технологии и конкуренция снизили цены разработок до вполне приемлемого уровня.
Обзор существующих разработок в области распознавания речи
К сожалению, солидных украинских фирм, которые занимаются созданием программных продуктов на основе распознавания или синтеза речи не существует. Существуют или научные учреждения, которые занимаются исследованиями в области распознавания и синтеза, или одинокие разработчики.
Российские разработчики весьма сильны в распознавании символов (продукты компаний ABBYY и Cognitive Technologies известны всему миру), можно было бы ожидать, что и в распознавании звучащей речи они преуспеют не меньше. Однако на настоящий момент единственным пакетом для ПК, позволяющим диктовать по-русски, является "Комбат" московской фирмы "Вайт Груп" - русифицированная версия программы Dragon Dictate (о первом варианте пакета, называвшемся "Горыныч", см. "Мир ПК", № 9/97, с. 181). "Комбат" обеспечивает ввод русских текстов, а также управление Рабочим столом русских версий Windows 3.x, 95/98 и NT. Объем его словаря - 26 тыс. словоформ с возможностью расширения до 30 тыс.
Создание собственной системы диктовки в нынешних российских условиях не окупится - считают в петербургском Центре речевых технологий, - но у распознавания речи есть масса других полезных применений. Там активно занимаются системами речевого управления (причем не обязательно компьютером - разработанный Центром пульт "Труффальдино" предназначен для речевого управления бытовой электроникой типа видеомагнитофона), распознаванием голоса, компьютерной обработкой записей. Распознавание голоса находит применение в криминалистике, а также для защиты компьютера (и не только компьютера) "голосовым паролем". А разработанный Центром специальный текстовый редактор "Цезарь" пригодится всем, кому часто приходится расшифровывать некачественные записи: он позволяет не только любое число раз "прокручивать" тот или иной фрагмент оцифрованной записи речи, но и прослушивать его в замедленном темпе без искажения тембра, а также находить требуемое место записи по введенному тексту.
Московский Клуб голосовых технологий сосредоточил свои усилия на синтезе речи. В сотрудничестве с лингвистами из Лаборатории экспериментальной фонетики Филологического факультета МГУ он выпустил диск "Говорящая мышь" (издателем выступил Международный центр фантастики). "Мышь" позиционируется как развлекательный продукт (и реклама разработанного Клубом программистского инструментария для синтеза), но вполне может пригодиться людям с ослабленным зрением, которым трудно читать надписи на экране.
Но самое интересное происходит, пожалуй, в "ИстраСофт" (www.istrasoft.ru) - компании, известной в первую очередь пакетом для обучения английскому языку с визуальным контролем произношения "Профессор Хиггинс". Развивая "Хиггинса", сотрудники "ИстраСофт" совершили технологический прорыв, значение которого трудно переоценить: они научились членить слова на элементарные сегменты, соответствующие звукам речи, независимо от диктора и от языка! (Существующие системы распознавания речи не производят сегментации: наименьшей единицей для них является слово.) Демонстрация новой технологии выглядит пока не очень эффектно: это всего-навсего упаковка и распаковка звуковых файлов с записью речи - правда, с необычайно высокими коэффициентами сжатия. Если файл был сжат сильно, то после распаковки в нем появляются отчетливо слышные границы между сегментами; использованию программы по прямому назначению они, конечно, мешают, но специалисту позволяют убедиться в правильности членения.
Функцию распознавания речи IBM не только встроила в свою операционную систему OS/2 Warp 4, известную под кодовым названием Merlin (конец 1996 г.), но и выпускает в качестве отдельного продукта. Пакет для распознавания слитной речи Via Voice (www.ibm.com/viavoice) от IBM отличается своей способностью с самого начала, без обучения, распознавать до 80% слов. При обучении вероятность правильного распознавания повышается до 95%, причем параллельно с настройкой программы на конкретного пользователя происходит освоение будущим оператором навыков работы с системой. Небезынтересно, что, рекламируя этот пакет, IBM утверждает, будто средняя машинистка набивает примерно 80 слов в минуту, a Via Voice достигает скорости 150 слов в минуту.
Dragon Dictate Naturally Speaking — первый коммерческий продукт для распознавания слитной речи, вышедший в начале 1997 года. Позволяет непосредственно диктовать в программы Word, WordPerfect, Netscape Navigator, Internet Explorer и приложения, причем ему доступен богатый набор управляющих команд. Пользуясь только голосом, можно исправлять и переставлять слова, выделять текст и даже менять размер шрифта и позиционировать курсор с абсолютной точностью. Первоначальная настройка на конкретный голос пользователя является обязательной, но программа способна обучаться и в процессе дальнейшего диктанта; рабочее качество распознавания может быть достигнуто спустя примерно пару недель пользования системой.
Lernout&Hauspie Speech Products (Берлингтон, шт. Массачусетс) в 1997 г. приобрела KurzWeil Applied Intelligence, основатель которой Рей Курцвайль стал в L&H главным техническим руководителем. После этого фирма получила инвестиции от Microsoft, делающей на ее продукты ставку, а затем выпустила Voice Commands — программу для голосового управления с развитыми возможностями. Несколько позже эта компания создала и свою систему распознавания речи Voice Xpress Plus, которая по качеству распознавания незначительно уступает Dragon Dictate Naturally Speaking, но зато при работе с офисными программами (например, с Word) реализует более "естественный" интерфейс (можно подавать команды вроде "изменить шрифт последнего предложения на Arial" или "сложить эту колонку цифр").
Фирма Charles Schwab&Co (Сан-Франциско) имеющиеся системы IVR (Interactive Voice Response — интерактивная система с голосовым ответом, подразумевающая ввод запросов через телефон с тональным набором номера)дополнила программным обеспечением, созданным на базе технологии Conversational Transaction Technology, разработанной компанией Nuance Communications (www.nuance.com). Созданная в результате этого объединения система Voice Broker позволяет в автоматическом режиме по телефону, используя только голосовой интерфейс, получать информацию о текущих котировках акций и ценных бумаг. База данных содержит свыше 15 тысяч разновидностей ценных бумаг, и Voice Broker обеспечивает более 100 тысяч видов различных информационных запросов, учитывая, например, различные речевые формулировки названий фирм. Модуль распознавания голоса (Voice Recognition Unit, VRU) смонтирован на рабочей станции с процессором SPARC фирмы Sun и взаимодействует с несколькими блоками распознавания на машинах UltraSPARC, которые снабжают модуль VRU запрошенной информацией. Пользователь получает ответ в пределах 2 секунд. Вслед за Schwab программы для распознавания нашли свое применение в Sears, Roebuck and Co и United Parcel Service of America.
Основные методы распознавания речи
Идеальная система распознавания речи должна удовлетворять следующим требованиям:
Существует несколько основных технологий распознавания речи:
Голосозависимые - принцип функционирования системы, зависящий от конкретного пользователя, требующий предварительной адаптации к диктору. Такие системы обладают более высокой точностью и относительно просты в разработке, однако отсутствие необходимой гибкости в использовании затрудняет повсеместное распространение.
Голосонезависимые - такая технология подразумевает независимость от говорящего человека, однако обладает противоположными свойствами. При высокой гибкости имеем пониженную точность, высокую стоимость и сложность в разработке.
Смешанный тип или адаптивные системы. Как понятно из названия, эта технология предполагает подстройку к новым пользователям. Это делает ее достаточно гибкой, однако практически исключает возможность инсталляции в широкодоступных информ-системах.
По типу входного сигнала различают дискретные и непрерывные системы. Диктор должен выдерживать определенные промежутки между словами в дискретном случае. Реализация системы такого типа не представляет особых сложностей, однако создает вполне понятные неудобства.
Основные препятствия на пути внедрения систем распознавания голоса и речи:
Несмотря на хорошую математическую и аппаратную базу, не решена проблема шумоподавления, что вынуждает пользователей работать в условиях минимального шумового фона, либо использовать гарнитуру с микрофоном у самого рта.
Для распознавания речи используют три основные модели языка:c
Наиболее точными с точки зрения распознавания являются системы, основанные на словарной модели, но их область применения ограничена системами управления, имеющими небольшое количество команд. Для распознавания слитной речи в системах массового обслуживания населения более пригодна фонетическая, слоговая или смешанная модель, где используются как фонемы и слоги, так и целые слова (цифры, числа, некоторые команды).
Для распознавания фонем, групп фонем и слов используются такие методы, как скрытая марковская модель или НММ (hidden Markov modelling), искусственные нейронные сети (ИНС) или их комбинации.
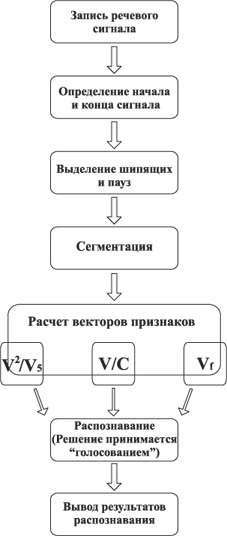
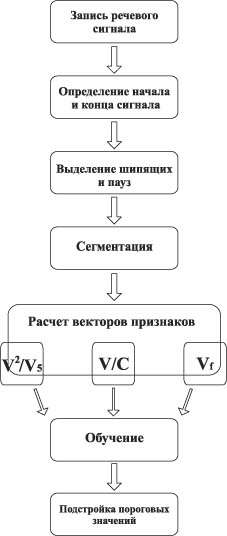
Данная работа посвящена разработке программы дикторонезависимого распознавания некоторых фонем русского языка, в частности, фонем «Ж» и «З». Программа может работать в одном из двух режимов - обучения или распознавания.
|
|
| Рисунок 1. Схема работы программы в режиме распознавания. | Рисунок 2. Схема работы программы в режиме обучения. |
Участки сигнала разбиваются на отрезки по 256 отсчетов. Перед этим отбрасываются участки, соотвествующие шипящим и паузам, затем на каждом из них вычисляется значение V.
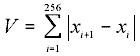
|
(1) |
где V - численный аналог полной вариации.
Затем от начала участка последовательно берется 20 таких отрезков (или менее, столько, сколько позволяет длина участка) и вычисляется среднее значение соответствующих величин - порог. Тем отрезкам, для которых величина больше среднего присваивается символ «В» (выше порога), остальным символ «Н» (ниже порога). Для устранения случайных единичных включений для каждого i-го элемента полученной символьной последовательности S выполняется обработка «тройками»:
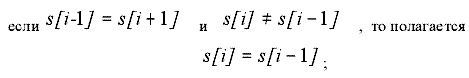
|
(2) |
и обработка «четверками»:
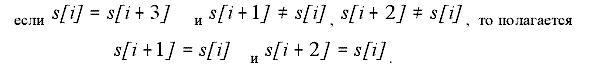
|
(3) |
После этого интервал, на котором выполняются описанная процедура, сдвигается вправо на одно окно и процедура повторяется. Это делается до тех пор, пока упомянутый интервал находится в пределах сигнала. В результате возникает таблица, состоящая из строк символов В и Н.
Затем просматриваются все строки полученой таблицы и создается новая символьная последовательность S1. Если текущая i-я строка таблицы начинается и заканчивается одним и тем же символом («Н» или «В»), то в S1 на i-ю позицию записывается соответствующий символ. Иначе считается количество вхождений каждого из символов в данной строке. Если количество «В» превышает количество «Н» или равно ему, то в S1 на соответствующую позицию записывается «В», иначе «Н». К полученой последовательности применяется обработка «тройками» и «четверками». Метки сегментации ставятся там, где происходит смена символов «Н» на «В», или «В» на «Н».
Далее необходимо m раз последовательно обработать сигнал трехточечным сглаживающим фильтром:
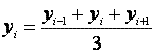
|
(4) |
взяв в качестве m минимальное число, при котором участок шипящей превращается в прямую. После этого для записанного речевого сигнала формируется массив величин полной вариации, вычисляемых для последовательности окон по 256 отсчетов. Для этого массива осуществляется «В-Н»-обработка с порогом 0,1 а также обработка «тройками» и «четверками». Начало и конец «Н»-участка отмечаются метками. Они являются концами соответствующей шипящей или паузы.
Мы исходим из представления, что фонема и слово – это акустически принципиально разные фонетические объекты. Фонема (и даже класс близких фонем) – объект спектрально сравнительно однородный, слово же, напротив, состоит из спектрально разнородных частей. Поэтому, распознавая слова целиком, мы должны использовать тот или иной вектор признаков. Для распознавания же фонем (и их классов) более целесообразно использовать подходящий скалярный признак или набор независимых скалярных признаков, каждый из которых должен обеспечивать свой результат распознавания. Как правило, на основе нескольких примеров можно указать интервалы, куда чаще всего попадают значения признака для каждого члена рассматриваемой пары классов или фонем. Значения за пределами этих интервалов разумно интерпретировать как отказ от распознавания. Итак, создавая обучаемую систему распознавания пары классов, использующую один скалярный признак X , задаем два числа a,b . При
| X < a | (5) |
считаем, что объект распознавания принадлежит первому классу, при
| X > b | (6) |
- второму. При
| a < X < b | (7) |
не выполняется ни первое, ни второе условие, и мы имеем отказ от распознавания.
Вначале задаются достаточно малое инициальное значение a и достаточно большое инициальное значение b. Если, пользуясь ими при распознавании, система не определит объект первого класса, то число a слишком мало. После того, как пользователь укажет истинный результат, система должна заменить a вычисленным значением признака, увеличив последнее скажем на 0,1. Таким образом, в процессе обучения число a может только расти. Аналогично число b может только убывать. При этом обеспечивается все большая надежность в случае принятия решения. Если, начиная с некоторого момента, окажется
| a > b | (8) |
то при попадании X в (b,a) для распознаваемого объекта выполняются оба неравенства, то есть он должен быть отнесен к обоим классам сразу, что невозможно, так как предполагается, что класс должен определяться однозначно. Таким образом, в случае a > b попаданиеX в (b,a) должно означать отказ от распознавания. Суммируя сказанное, получаем, что при
| X < min(a,b) | (9) |
объект относится к первому классу, при
| X > max(a,b) | (10) |
- ко второму классу, при
| min(a,b> < X < max(a,b) | (11) |
система отказывается от распознавания. Обучение состоит в модификации констант a,b и продолжается до тех пор, пока система не проработает без ошибок на протяжении, скажем, пяти циклов распознавания. Тогда распознаватель будет либо с высокой надежностью принимать правильное решение либо отказываться от распознавания. Теперь представим себе, что для полученной системы вероятность отказа достаточно мала. Если мы для той же пары введем еще несколько таких систем, использующих другие признаки, то ввиду схемы независимых испытаний Бернулли, вероятность того, что все они одновременно будут отказываться от распознавания, станет существенно меньше. Все вместе построенные системы дадут желаемый распознаватель для рассматриваемой пары классов, если случай противоречия в результатах отдельных систем мы также будем интерпретировать как отказ от распознавания.
Из других подходов наилучшие результаты на сегодняшний день даёт использование нейросетей и признаков, построенных на основе вейвлет-преобразований.
Далее введем следующие величины, которые вычисляются на окнах длины 256 отсчетов:
| V | - вариация сигнала; |
| Va | - вариация сигнала после а - кратного сглаживания |
| C | - количество точек постоянства, то есть моментов времени, для которых в следующий момент величина сигнала остается той же самой; |
| V/C | - отношение полной вариации к количеству точек постоянства; |
| V2/V5 | - отношение квадрата полной вариации к полной вариации пятикратно сглаженного сигнала; |
| Vf | - полная вариация высокочастотной составляющей сигнала. |
Фильтрация проводилась с использования дискретного преобразования Фурье.
Параметры V/C, V2/V5 и Vf - порговые значения, используемые для обучения програмы и для выделения фонем «Ж» и «З.
Интеллектуальная обработка речи на уровне фонем перспективна не только как способ сжатия, но и как шаг на пути к созданию нового поколения систем распознавания речи. Распознаване речи одна из самых востребованных областей на данном этапе развития глобальных цифровых компьютерных технологий. Оно требуется на производстве, при управлении роботами, при автоматизации процессов, в медицинских и военных приложениях, при наблюдении со спутников и при работе с персональными компьютерами, в частности поиске цифровых изображений. Работа построена в форме сборника статей (по возможности независимых), посвященных разнообразным вопросам связанными с распознаванием речи.
В процессе обучения програма в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Программа обучаясь просматривает выборку только один раз. Набор исходных данных делят на две части — собственно обучающую выборку и тестовые данные. Причем принцип деления на группы может быть произвольным. Обучающие данные подаются для обучения, а проверочные используются для расчета ошибки програмы. Созданная программа может с высокой надежностью принимать правильное решение либо отказывается от распознавания. При этом для полученной системы вероятность отказа от распознавания достаточно мала.