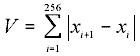
Email:gorunova.elena@gmail.com
As computer systems develop, it becomes more and more clear that usage of these systems will be much broader if employment of human speech is possible while direct working with a computer. Namely, it will be possible to operate the computer by ordinary voice in real time regime, as well as to introduce and take out information in the form of normal human speech. Natural interaction of a man and a computer, alike the communication between two people, appears to be one of the most important and complicated tasks in the field of developing artificial intelligence. Researchers took up enthusiastically solving this problem as early as the daybreak of informatics as a science, together with the problem of automatic translation from one language into another. The existing models of speech understanding are sufficiently inferior in comparison with speech abilities of a man, which proves their inadequacy and limits usage of speech technologies in industry and in everyday life. Natural languages appeared being more complex object than they seemed from the very beginning. In particular, discerning of oral speech by a person is based mostly on his mental activity connected with understanding of the contents of the pronounced material in real time. It is known that without it a person can properly identify no more than 30% of the heard flow of phonemes. But he is able to repeat the word, which was pronounced distinctly in a strange language (certainly, interpreting the sounds in the framework of the phonetic system habitual for him). It means that phoneme recognition should be taken as the basis if we do not want to be limited to identification of words by models, i.e. to work on the level of sound hieroglyphs. The given paper is aimed at the development of phoneme recognition of Russian speech, namely, the phonemes The created program can make with high reliability the correct decision or refuses recognition. Thus for the received system the probability of refusal of recognition is small enough. "Ж" "З", providing for input of Russian speech independently from announcer.
The goal and tasks of the work:
The investigations in the field of speech recognition have sufficient background, and presently they are still urgent, develop actively and are practically employed in numerous fields.
Such systems are very useful in practice, and the demand for them grows constantly. Primarily it is connected with the appearance of numerous appliances of various types (personal, mobile and pocket computers, communicators and mobile telephones, devices for games, multifunctional multimedia units with sufficient calculating capacity) accessible for a person, with which he has to interact.
Because of traditionally high importance of the information reaching us through the vision organs and its high share (about 85%) among the entire sensor information, this "channel of perception" of a human being is sufficiently over laden. The primary alternative here is communication through the acoustic channel. Besides, speech recognition systems are extremely important for the people with limited vision. First of all, this trend is actively developed in the field of mobile telephony (small dimensions of telephones’ screens do not allow these people to use them with enough degree of convenience), and in consumer servicing (for operating different household appliances). To help such people, producers introduce into their products the possibility to operate them by voice commands (while dialing telephone number or while navigating menu items), as well as to duplicate screen information by voice.
To raise the efficiency of work of modern speech recognition systems using Russian phonemes, in the given Master’s paper the algorithm of recognition of the phonemes "Ж" and "З" is realized, which demonstrated better results in comparison with former analogues. The system is developed, which appears to be the most important element of the general recognition system.
To raise the efficiency of work of modern speech recognition systems using Russian phonemes, in the given Master’s paper the algorithm of recognition of the phonemes "Ж" and "З" is realized, which demonstrated better results in comparison with former analogues. The system is developed, which appears to be the most important element of the general recognition system.
Practical Importance of the got results
The problem of announcer-independent speech recognition appears to be urgent. For many years voice commands are one of the possible options of personal computers’ software – being a typical example of usage of speech recognition technique. Introduction of speech recognition function into some systems and text processors is not a novelty at the software products market for a long time. Numerous speech recognition commercial programs work well in speech services systems, beginning with reference bureaus and up to registration for medical treatment. This technology improved the efficiency of telephone centers of orders’ processing and allowed many companies to enlarge the number of their transactions and to expand their business. The market of voice recognition grew and proceeds to grow with the impressing speed. One of the reasons of such rapid growth is the demand for this technology among ordinary users of modern computers. The growth is also stimulated by the sufficient increase of calculating capacity and accessible memory volume of the average desktop personal computer. Now there are no problems with hardware necessary for functioning of the voice recognition system. The increasing number of providers of this technology and competition among them caused reduction of prices for such developing to the quite acceptable level.
Review of the existing researches in the field of speech recognition
Regretfully, there are no reliable Ukrainian firms engaged in creation of speech recognition software or speech synthesis. There are either research institutions, which hold researches in the field of recognition and synthesis, or independent developers.
Russian professionals of the field are very competent in symbol recognition (the products of the companies ABBYY and Cognitive Technologies are well-known in the whole world), and one could expect that in speech recognition they would be a success too. But at the moment the only PC package allowing dictating in Russian is "Combat" created by the Moscow firm "White Group" – the russified version of the program Dragon Dictate (information about the first variant of the package called "Gorynych" see in "Мир ПК", № 9/1997, p. 181). "Combat" provides for the input of Russian texts as well as for control of working table of Russian versions of Windows 3.x, 95/98 and NT. The volume of its vocabulary is 26000 of word forms with the possibility to broaden it till 30000 word-forms.
Creation of the own dictating system under the today’s Russian conditions would not be compensated, they suppose in the Petersburg center of speech technologies – but speech recognition has many other useful applications. There they actively work at the systems of speech control (controlling not only computers – the controlling panel "Trufaldino" developed by the center is intended for speech control of domestic electronic equipment like video recorder), voice recognition, computer processing of notes. Voice recognition is used in criminalistics, and for the defense of computers (and not only computers) by the "voice parole". And the special text editor "Ceasar" developed by the center can be helpful for everybody who has to interpret records "written down" poorly: it allows not only numerous "turning over" the same fragment of digital recording of speech, but listening to it slowly without distortion of timbre, and finding the necessary part of the record according to the introduced text.
Moscow Club of voice technologies concentrated its efforts on speech synthesis. In cooperation with the linguists of the Laboratory of Experimental Phonetics of the Philological Department of the MSU it produced a disk "Speaking Mouse" (the International Fiction Center was the publisher). "Mouse" is suggested as an entertaining product (and the advertisement of programming instrument for synthesis developed by the Club), but can be employed by the people with weak eye sight, for whom it is difficult to read inscriptions in the screen.
But probably the most interesting things happen in the company "IstraSoft" (www.istrasoft.ru) being primarily known due to the package for teaching English with visual control of pronunciation "Professor Higgins". Developing "Higgins" the "IstraSoft" staff made a technological break through, the importance of which it is hard to overestimate: they learnt to divide words into elementary segments corresponding to the speech sounds independent from announcer and from the language! (the existing systems of speech recognition do not do segmentation: a word is the smallest unit for them). Meanwhile the demonstration of the new technology does not look very effective: it is just packaging and unpacking of sound files with speech recording – but with extremely high compression factors. If a file was greatly compressed, after unpacking the clearly heard borders between segments appear in it; certainly, they hamper the usage of the program, but allow professionals making sure of reading accuracy.
IBM not only introduced the speech recognition function into its operational system OS/2 Warp 4, known under the code name "Merlin" (the end of 1996), but produces it as a separate product. The IBM package for recognition of continuous speech "Via Voice" www.ibm.com/viavoice) is characteristic of its ability to recognize 80% of words from the very beginning, without training. After training the probability of proper recognition arises to 95%, at that, parallel to "tuning" the program to the definite user, the future operator masters working skills with the system. It is interesting that while advertising the package IBM asserts that an average girl-typist prints 80 words per minute, and Via Voice reaches the speed of 150 words per minute.
Dragon Dictate Naturally Speaking – is the first commercial product for continuous speech recognition produced in the beginning of 1997. It allows dictating into the programs Word, WordPerfect, Netscape Navigator, Internet Explorer and application, and it has a rich set of controlling commands. Using only your voice you can correct and replace words, mark out text and even change the size of the print and place the cursor with absolute accuracy. The initial tuning for a special user’s voice is obligatory, but the program can learn in the process of further dictating; the working quality of recognition can be achieved in a couple of weeks of the system‘s usage.
In 1997 Lernout&Hauspie Speech Products (Burlington, Massachusetts) purchased KurzWeil Applied Intelligence, the founder of which, Ray Kurzweil, became the chief technical instructor in L&H. After this the firm has got investments from Microsoft, which staked on its products, and then produced "Voice Commands" – the program for voice control with different possibilities. Somewhat later this company created its own speech recognition system Voice Xpress Plus, which quality of recognition is only slightly inferior to Dragon Dictate Naturally Speaking, but while working with office programs (e.g. Word) realizes more "natural" interface (one can command something like "change the print of the last sentence for Arial" or "add the last column of figures").
The firm Charles Schwab&Co (San-Francisco) supplemented the existing systems IVR (Interactive Voice Response – an interactive system with voice response implying input of requests by telephone with tone dialing) with the software created on the basis of the technology Conversational Transaction Technology developed by the company Nuance Communications (www.nuance.com). The united system Voice Broker created as a result of this joining allows automatic getting information on the current quotations of stocks and securities by telephone using only voice interface. The database contains information on over 15000 of securities’ kinds, and Voice Broker provides for over 100000 types of different information requests taking into consideration, for example, various speech formulas of the names of firms. The voice recognition unit (Voice Recognition Unit – VRU) is installed on working station with the processor SPARC of the firm Sun and interacts with several recognition blocks on the machines UltraSPARC, which provide the VRU for the ordered information. Users get the answers in 2 seconds. After Schwab, the recognition programs found their usage in Sears, Roebuck and Co, and in United Parcel Service of America.
Basic speech recognition methods
The ideal system of speech recognition must satisfy the following requirements:
There exist several basic technologies of speech recognition:
The ones depending on voice – i.e. functioning of the system is based on its dependence from a special user, requiring the preliminary adaptation to the announcer. Such systems have higher accuracy and are rather simple in their development, but the absence of necessary flexibility in the usage hampers their universal distribution.
The ones independent from voice – such technology implies independence from the speaking person, but has its contrary qualities. Alongside with high flexibility it has low accuracy, high price and is complicated in development.
The mixed type, or the adaptive systems – as it is clear from the name, this technology implies tuning for new users. It makes the system rather flexible, but practically excludes the possibility to install it in widely accessible information systems.
On the basis of the input signal we distinguish intermittent and continuous systems. The announcer must make certain intervals between words in the case of intermittent systems. The realization of the like system has no special difficulties, but creates quite understandable discomfort.
Main obstacles in the introduction of voice and speech recognition systems:
In spite of good mathematic and instrumental base, the problem of noise - killing is not solved, which fact makes users to work under the terms of minimal noise background or to use garniture with microphone very near to their mouths.
Three basic language models are used for speech recognition:
From the viewpoint of recognition, the most exact systems are those, which are based on the word model, but their field of usage is limited by the systems of control having little number of commands. For the recognition of continuous speech in the systems of mass servicing the phonetic, syllable or mixed models are more suitable, i.e. the ones where both phonemes and syllables and whole words (figures, numbers, some commands) are employed.
For phoneme, phoneme groups and words recognition, such methods as hidden Markov modeling, or HMM (hidden Markov modeling), artificial neural networks (ANN), or their combinations are used.
The given paper is devoted to the development of the program of recognition of some Russian language phonemes, namely, the phonemes "Ж" and "З", independently from the announcer.
The given paper is devoted to the development of the program of recognition of some Russian language phonemes, namely, the phonemes "Ж" and "З", independently from the announcer.
Sections of signals are divided into segments equal to 256 counts. Before this, those sections are rejected, which correspond to hushing sounds and pauses, then V value is calculated on every of them.
|
|
(1) |
where V is numerical analogue of full variation.
Then 20 of such segments are taken from the beginning of the section (or less, as many as the length of the section allows), and average value of corresponding quantities – threshold – is calculated. To those segments, for which the value is higher than the average one, the symbol "В" is given (higher than the threshold), the rest receive the symbol "Н" (lower than the threshold). To eliminate incidental single inclusions for every i-element of the got symbol succession S the processing by "threes" is done:
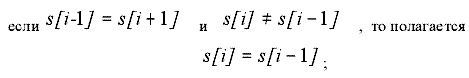
|
(2) |
and the processing by "fours" is done:
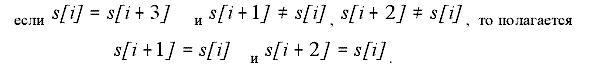
|
(3) |
After this the interval, on which the described procedure was done, is moved to the right for one window, and the procedure is repeated. It is done until the mentioned interval is within limits of the signal. As the result, the table appears, which consists of lines of the symbols В and Н.
Then all the lines of the got table are looked through, and the new symbol succession S1 is formed. If the current i – line of the table begins and ends with the same symbol ("Н" or "В"), then in S1 the corresponding symbol is written down into the i – position. Otherwise, the number of entries of every symbol in the given line is counted. If the number of "B" is higher than the number of "H", or equals to it, then in S1 "B" is written down into the corresponding position, if differently – "H". The processing "by threes" and "by fours" is applied to the got succession. Segmentation marks are put, where the change of the symbols "H" for "B", or "B" for "H" takes place.
Further on it is necessary to process the signal successively for m times by the three - point smoothing filter:
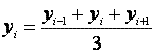
|
(4) |
taking as m the minimal number, at which the section of hushing sound turns into a straight line. After this for the recorded speech signal the full variation array of values, which are calculated for the succession of windows of 256 counts, is formed. For this array the "B" – "H" processing is done with the threshold 0,1, and the processing by "threes" and "by fours". The beginning and the end of "H" section is marked by markers. They are the ends of the corresponding hushing sound and the pause.
We proceed from the concept that a phoneme and a word are acoustically absolutely different phonetic objects. A phoneme (and even a class of similar phonemes) is an object comparatively homogeneous in spectrum; a word, on the contrary, consists of heterogeneous parts, from the spectrum viewpoint. That is why recognizing a word as a whole, we must use one or another vector of features. To recognize phonemes (and their classes) it is more reasonable to use the appropriate scalar feature or the set of independent scalar features, every of which should provide for its result in recognizing. As a rule, on the basis of several examples one can point out the intervals, into which the values of the features of every member of the regarded pair of classes or phonemes fall the most often. It is reasonable to interpret the values beyond the limits of these intervals as rejection of recognition. So, while creating a teachable system of recognition of a pair of classes using one scalar feature X, we assign two numbers a, b. If
| X < a | (5) |
we consider that the recognition object belongs to the first class; if
| X > b | (6) |
- that it belongs to the second class. If
| a < X < b | (7) |
neither first, nor second condition is not fulfilled, and we have a case of rejection of recognition.
First, a rather small initial value a and rather big initial value b are set. If using them for recognition the system would not recognize the first class object, it means that the value a is too small. After the user’s pointing out the true result, the system must change a for a calculated value of the feature enlarging the latter one by, say, 0,1. So, in the process of teaching the value a can only grow. Similarly, the value b can only decrease. Alongside with this, more and more reliability is provided for in the case of making a decision. If, beginning with a certain moment, it appears that
| a > b | (8) |
then in the case of X falling in (b, a) both inequalities are fulfilled for the object being recognized, i.e. it must be referred to the both classes immediately, which is impossible, so we suppose that the class must be determined unambiguously. So, in the case of a > b, X’s falling into (b, a) must mean the rejection of recognition. Summing up everything said, we come to the fact that at
| X < min(a,b) | (9) |
the object refers to the first class, at
| X > max(a,b) | (10) |
refers to the second class, at
| min(a,b> < X < max(a,b) | (11) |
the system rejects recognition. Teaching consists in modification of the constant a, b and proceeds until the system works without mistakes during, say, five cycles of recognition. Then the recognizer either will make proper decisions with high reliability, or will reject recognition. Now let us imagine that the possibility of rejection is rather small for the got system. If for the same pair we introduce several more of such systems using other features, then according to the scheme of independent tests of Bernully the possibility of the fact that all of them will simultaneously reject recognition will become sufficiently less. All together the built systems will give the desired recognizer for the considered pair of classes if the case of contradiction in results of separate systems we shall interpret too as the rejection of recognition.
Among other approaches at the moment the best results are given by usage of neural networks and features based on wavelet conversions.
Further we shall introduce the following values, which are calculated on the windows being 256 counts long:
| V | - signal variation; | |
| Va | - signal variation after a – divisible smoothing; | |
| C | - the number of constancy points, i.e. the moments, for which at the next moment the signal value remains the same; | |
| V/C | - ratio of full variation to the number of constancy points; | |
| V2/V5 | - ratio of the squared full variation to the full variation of fivefold smoothed signal; | |
| Vf | - full variation of high-frequency constituent of signal. |
Filtration was held with the usage of the discrete Fourier transform.
Parameters V/C, V2/V5 and Vf - the threshold values used for training of the program and for allocation of phonemes >Ж> and >З>
Intellectual processing of speech on the level of phonemes has great potential not only as the way of compression, but as a step on the way of creation of a new generation of speech recognition systems. Speech recognition is one of the fields of greatest demand at the current stage of development of global digital computer technologies. It is wanted in production, controlling robots, automation of different processes, in medical and military applications, while keeping look-out from satellites and working with personal computers, namely, in searching digital images. The paper is built in the form of collection of articles (independent as much as possible) touching on different problems connected with speech recognition.
In the process of training the program regards the teaching selection in a certain order. The order of consideration can be successive, accidental, and so on. Being trained the program considers the selection only once. The set of starting data is subdivided into two parts – special teaching selection and test data. The principle of subdivision into the groups can be arbitrary. Teaching data are given for training, and testing ones are used for calculation of the program’s mistakes. The created program can make with high reliability the correct decision or refuses recognition. Thus for the received system the probability of refusal of recognition is small enough.