Formally, to each task t , a non-negative duration d(t) and a resource use(t) are associated. For precedence relations, precede(t1, t2 ) denotes that t2 cannot be performed before t1 is completed. The problem is then to find a set of starting times {time(t)}, that minimizes the total makespan of the schedule defined as Makespan := max{time(t) + d(t)} under the following constraints:

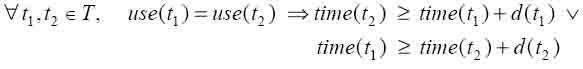
Job-shop scheduling is a special case where the tasks are grouped into jobs j1,..., jn . A job ji is a sequence of tasks j1i,..., jmi that must be performed in this order, i.e., for all
 ,
one has precede( jki , jk+1i).
Such problems are called n x m problems, where n is the
number of jobs and m the number of resources. The precedence network is
thus very simple: it consists of n “chains”. The simplification does not
come from the matrix structure (one could always add empty tasks to a
scheduling problem) but rather from the fact that precedence is a functional
relation. It is also assumed that each task in a job needs a different machine.
For a task jki , the head will be defined as the sum of
the durations of all its predecessors on its job and similarly the tail as the
sum of the durations of all its successors on its job, e.g.:
,
one has precede( jki , jk+1i).
Such problems are called n x m problems, where n is the
number of jobs and m the number of resources. The precedence network is
thus very simple: it consists of n “chains”. The simplification does not
come from the matrix structure (one could always add empty tasks to a
scheduling problem) but rather from the fact that precedence is a functional
relation. It is also assumed that each task in a job needs a different machine.
For a task jki , the head will be defined as the sum of
the durations of all its predecessors on its job and similarly the tail as the
sum of the durations of all its successors on its job, e.g.: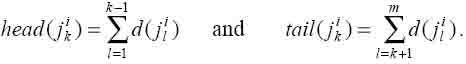
When one allows the precedence relations to form a more complex network, the problem is referred to as a disjunctive scheduling problem. Although general disjunctive scheduling problems are often more appropriate for modelling real-life situations, little work concerning them has been done (they have been studied more by the AI community than by Operations Researchers and most of the published work concerns small instances, like a famous bridge construction problem with 42 tasks [VH89]) The interest of n x m scheduling problems is the attention they have received in the last 30 years. The most famous instance is a 10 x 10 problem of Fisher & Thompson [MT63] that was left unsolved until 1989 when it was solved by Carlier & Pinson [CP89]. Classical benchmarks include problems randomly generated by Adams, Balas & Zawak in 1988 [ABZ88], Applegate & Cook in 1990 [AC91] and by Lawrence in 1984 [La84]. Of the 40 problems published by Lawrence, one is still unsolved (a 20 x 10 referred to as LA29). The typical size of these benchmarks ranges from 10 x 5 to 30 x 10.