Перевод статьи выполнила Лобачева М.В.|
Источник: http://citeseer.ist.psu.edu/cache/papers/cs/733/http:zSzzSzwww.brunel.ac.ukzSz~cspgsskzSzdocumentszSztech-reportszSzCNES-96-04.pdf/diagnosis-of-oral-cancer.pdf
Саймон Кент
Диагностика рака горла с использованием генетического программирования
Резюме
Генетическое программирование - относительно новый способ для автоматического открытия компьютерных программ, которые предлагают решения сложных проблем. Он имеет хорошие результаты применения во многих областях.
Эта статья является вводной работой, связанной с проблемой классификации. Способ генетического программирования используется для эволюционных программ, которые диагностируют рак горла и предраковые состояния. Чтобы обучить и проверить систему, используются реальные данные, касающиеся привычек и образа жизни пациентов.
Несмотря на несогласованности во входных данных, и низком проценте положительных данных, эволюционная программа делает точные предсказания, и успешно конкурирует с другим методом решения данной проблемы - методом нейронной сети.
1 Введение
Генетическое Программирование (ГП) использует эволюционные принципы, заимствованные у природы, и применяет их в программировании для генерации программ, решающих сложные проблемы. Этот сбособ до сих пор находится в состоянии развития, его появление связано с именем Koзa (1989), однако, он находит все более широкое применение в различных областях применения. Эта статья посвящена рассмотрению использования ГП для генерации программ, способных диагностировать рак горла.
Такая задача успешно решалось с использованием других методов таких, как нейронные сети. Данные, используемые в данной статье применялись Эллиоттом (1993) для решения такой же диагностической проблемы с использованием нейронных сетей. Работа Эллиотта является удачным эталоном, с которым можно сравнить результаты, полученные с помощью ГП.
2 Генетическе Программирование
Для получения решений проблемы генетическое программирование использует дарвинистский принцип естественного отбора.
Животным и растениям в природе приходится сталкиваються со сложными ситуациями для того, чтобы выживть в своей среде обитания. Было бы чрезвычайно полезно, если бы компьютеры могли обеспечить решения хотя бы с долей сложности простого млекопитающего. Использование ГП дает возможность применять компьютерную технологию для решения проблем, которые являются слишком сложными для решения их человеком – программистом, использующего обычные компьютерной науки.
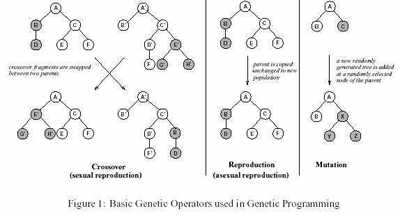
Для воспроизводства потомков особи используют половой и бесполый способы размножения, при этом каждая особь берет некоторые из особенностей своих родителей. Самые удачные особи воспроизводят больше потомков, чем менее приспособленные. Т.о., характеристики, которые делают особь удачной, будут переданы последующим поколениям. Более приспособленная особь, имеет большую вероятность репродукции. Поэтому, 'хороший' генетический материал передается через последующие поколения. Это – тот путь, которым человечество и другие млекопитающие достигли настоящего, развитого состояния.
В GP особи, которые принимают участие в развитии – это компьютерные программы, которые предлагают решение данной проблемы. Компьютерные программы могут быть представлены как деревья, и производство последующих поколений достигается применением генетических операторов, как показано на рисунке1. Они подражают процессу скрещивания.
Развитие происходит в повторении вычислительного процесса. Начальная популяция генерируется случайным образом как начальная точка процесса. Каждая особь производится для того, чтобы измерить соответствие или способность решить проблему, для которой она предназначена. Новая популяции затем генерируется из предыдущего поколения, используя генетические операторы. Вероятность того, что конкретная особь будет участвовать в генерации особей для нового поколения, увеличивается сувеличением меры приспособленности особи. Этот процесс оценки приспособленности и развития повторяется до тех пор, пока решение не будет найдено или пока не истечет время ожидания.
В этой статье метод генетического программирования описан очень кратко. Более глубокий обзор по ГП можно найти у Koza (1993).
3 Исходные данные
Данные, используемые в этом проекте, были первоначально собраны в Институте Истман Дентал в Лондоне. Эти данные собирались на основе анкетных опросов, которые были даны пациентам до процесса скрининга. Каждый анкетный опрос также содержал данные от двух человек, проводивших диагностику состояния пациентов. Один диагноз ставился неспециалистом-диагностом, в то время как другой был сделан специалистом. Специалист ставил диагноз, используя диагностические пособия типа биопсии.
Общее количество анкет составляло 2027, однако некоторые из них были отброшены, как описано ниже в подразделе 3.3.
3.1 Данные анкетного опроса
Вопросы, задаваемые пациентам, имели несколько вариантов выбора. Например, для нижепреведенного пятого вопроса, для пациента были приведены следующие варианты ответов: никогда; не более десяти лет; в течение последних десяти лет; в настоящее время. Вопросы анкетирования были следующие:
- Пол
- Дата Рождения
- Дата диагностирования
- Отделение, в котором поводилось диагностирование
- Курили или жевали табак
- Как долго курите или жуете табак
- Курите сигареты с фильтром
- Курите сигареты без фильтра
- Курите сигары
- Количество сигарет, выкуриваемых за день
- Курите самокрутки
- Курите трубку
- Жуете табак
- Едите орехи
- Унции, выкуриваемые за день
- Пьете алкоголь
- Пьете пиво
- Пьете вино
- Пьете крепленое вино
- Пьете алкоголь
- Количество выпитого за неделю
- Время, прошедшее с последнего раза посещения дантиста
- Название обследования
- Результат обследования
- Локализация заболевания во рту (согласно обследованию)
- Тип заболевания (согласно обследованию)
- Результат Специалиста
- Локализация заболевания во рту (согласно специалисту)
- Тип заболевания (согласно специалисту)
3.2 Представление Данных
Данные анкетного опроса, собранные в базе данных, были представлены в форме, неподходящей для непосредственного использования программным обеспечением GP. Они также содержали лишние данные, например ‘название обследования’, которые были бы неуместны для постановки правильного диагноза.
Данные экспортировались из базы данных как разграниченный текст, и были конвертированы в 13-битовые поля для каждой записи. Каждый бит представляет истинностное значение одного из тринадцати предикатов о пациенте. Вопросы или предикаты базируются на используемых Эллиоттом (1993) в его проекте MSc. Его вопросы были разработаны им совместно с Джоанной Жюлиан, которая была специалистом-дантистом, ставящим диагнозы пациентам.
Эти тринадцать предикатов следующие:
1. Пол - женский (0=мужской, 1=женский)
2. Возраст >40
3. Возраст > 55
4. Возраст >70
5. Возраст >85
6. Курили в течение последних 10 лет
7. В настоящее время курю >=20 сигарет в день
8. Курили более 20 лет
9. Пьете пиво и/или винно
10. Пьете крепленное вино и/или алкоголь
11. Пьете много спиртного (Мужчина>21, Женщина> 14)
12. Не посещали дантиста последние 12 месяцев
13. Положительный диагноз специалиста
3.3 Корректность
Не было сделано никаких проверок, чтобы подтвердить правильность ответов в анкетных опросах. Полагались только на честность в ответах пациентов. Выполнить детальный анализ данных и найти несогласованности в данных довольно трудно.
Была выполнена некоторая проверка данных. Во-первых, была выполнена быстрая визуальная проверка, чтобы выявить явно неправильные данные, например, такие, как возраст пациентов 0.17 или даже -0.01.
После того, как данные были конвертированы к бит-полям (см. раздел 4), они были пропущены через программу, которая проверяла их на несогласованность. Проверка состояла в том, что идентичные записи входных битовых полей сравниваются с противоречащим диагнозом эксперта. Такое могло возникнуть в результате неправильных данных в первоначальных анкетных опросах, или же в результате потери информации, вызванной преобразованием в битовое поле. Битовое поле явялется более низким решением представления характеристик пациента, чем первоначальные данные анкетного опроса. Например, битовое поле не содержит какую-либо информацию о типе табака, в то время как первоначальные данные анкетного опроса содержат эту информацию.
Найденные данные включали 37 групп особей, содержащих несогласованности. Большинство из этих групп имели от 2 до 4 записей в размере. Всего было найдено 110 таких особей. Две из этих групп имели особенно большое количество особей; 10 и 11 соответственно. Эти две группы были удаленны из набора данных. Другие меньшие группы, в которых имелись несогласованности, оставили в данных, поскольку они представляли собой помехи, которые естественно всегда будут появляться в таких данных.
В результате проверок, сделанных в данных, из них был удалена 31 особь, остался набор из 1996 особей, из которых 54 имели положительные диагнозы, и 1440 имели отрицательные диагнозы. Эти особи были разбиты в обучающий набор и тестовый набор. Обучающий набор содержал 1483 записи (43 положительные, 1440 отрицательные) и тестовый набор содержал 513 записей (11 положительных, 502 отрицательных). В обучающий набор входили 29 групп несогласованностей и в тестовый набор – 8.
4 Схемы Представления ГП
Генетическое программирование требует такой схемы представления, с помощью которой можно точно выразить решение конкретной проблемы. Такие решения в ГП представлены в виде программ или деревьев. Эти деревья состоят из функций, которые являются внутренними узлами деревьев, и терминалов, которые формируют листья деревьев.
4.1 Набор Терминалов
Набор терминалов для рассматриваемой проблемы состоит из тринадцати битовых полей, которые отражают образ жизни и привычки пациента. То есть, значение листа представляет верное значение для одного из тринадцати предикатов в 3.2.
4.2 Набор Функции
Набор функции состоит из трех логических операторов: И, ИЛИ, и НЕ. Поэтому решением будет являться логическое выражение, использующее признаки пациента в качестве переменных.
5 Мера Соответствия
Генетическое программирование генерирует варианты решения поставленной задачи. Поэтому необходимо следить за тем, насколько эффективно программа решает задачу. То есть необходимо следить за мерой соответсивия. Важным является то, что эта мера точно оценивает работу программы.
5.1 Процент Точности и Средняя Квадратичная Ошибка
При диагностике рака горла программа оценивается относительно записей данных для каждого пациента в обучающем наборе. Рассмотрим два метода:
- Средняя квадратичная ошибка диагностики пациентов.
- Количественное соотношение правильно продиагностированных пациентов.
Для данной задачи, эти два метода являются эквивалентными, поскольку один из них равен 1.0 минус второй метод. Поэтому они, к сожалению, имеют тот же самый недостаток, что и некоторые деревья решений ГП, предполагающие, что они являются более достоверными, чем те, которые в конечном счете будут способствовать развитию оптимальных особей.
Например СКО для данной задачи определена:
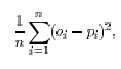
В теории может показаться, что это представляет подходящую меру соответствия, однако на практике появляется проблема, которая ухудшает выполнение эволюционного процесса. Проблема вызвана некоторыми особями, которые неизбежно появляются в популяции. Это такие особи, которые выводят отдельное истинностные значение независимо от входных переменных. Простой пример такогй особи показан на рисунке 3. Здесь представлено противоречивое дерево, которое будет всегда выводить значение ложь.
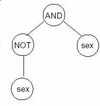
Рисунок 3 - Противоречивое дерево
Если противоречащую особь оценить относительно набора обучения, рассмотренного в разделе 3.3, то СКО будет равна 0.029. Такие противоречащие особи имеют намного лучшую фитнес-функцию, чем другие особи, поэтому их генетический материал быстро доминирует в популяции и вызывает быструю сходимость к субоптимальному решению, вместо того, чтобы поддерживать постепенное развитие оптимального решения. Такие решения должны обеспечить высокий общий процент правильных диагнозов, однако все они –являются отрицательными диагнозами, которые доминируют над входными данными, в то время как ни один из положительных случаев не будет когда-либо распознаваться.
Использование процента правильно продиагностированных пациентов в качестве меры соответствия приводит к той же самой проблеме. Противоречащая особь, которая является верной, способна правильно диагностировать 97 % особей (отрицательных). Другие особи могут содержать важный генетический материал, который в последствии мог бы способствовать эффективному решению, но они угнетаются превосходящим противоречивыми особями.
Эта проблема подчеркивает необходимость в более подходящей мере соответствия.
5.2 Изменение фитнес-функции
Проблему фитнес-функции можно представить, используя схему, показанную на рисунке 4. Здесь, противоречащие особи, которые являются причиной преждевременной сходимости, расположены возле 0.5, таким образом относительно уменьшается их фитнес-функция . Оптимальной целью является 1.0, а худшим случаем - 0.0, когда особь неправильно диагностирует всех пациентов. Это метод вознаграждает за правильные диагнозы и наказывает за неправильные диагнозы более эффективно, чем предыдущие два метода. Этот метод изменения фитнес-функции единственный, который использовался во всех диагностических экспериментах.

| размер популяции | 500 |
| максимальная глубина особей в начальной популяции | 6 |
| максимальная глубина особей в развивающейся популяции | 17 |
| метод генерации | ramped half-and-half |
| вероятность функционального узла | 0.80 |
| вероятность терминального узла | 0.20 |
| вероятность кроссинговера | 0.90 |
| вероятность репродукции | 0.10 |
| вероятность мутации | 0 |
| вероятность выбора функционального узла для кроссинговера | 0.90 |
| метод селекции | турнирный |
Таблица 1: Параметры ГП по диагностики рака горла
6 Параметры Генетического Программирования
Базовый процесс ГП может регулироваться, используя множество параметров. В таблице 1 приведен список главных параметрв, используемых при создании статьи.
6.1 Размер популяции
Размер популяции определяется количеством генетических программ в каждом поколении процесса генетического программирования. Как правило, более сложная проблема должна иметь большую популяцию.

Рисунок 5 – Полное и растущее дерево
6.2 Генерация популяции
Границы установливаются для того, чтобы предотвратить размеры структур данных, становящихся слишком большими. Одна граница устанавливается для определения глубины программы в начальной, беспорядочно сгенерированной совокупности, а другая устанавливается для определения глубины тех программ, которые получены в результате генетических операций типа скрещивания, репродукции или мутации (см. 2).
Метод условия половины-к-половине для генерации популяции производит различные начальные генерации с множеством различных типов деревьев. Половина сгенерированной популяции будет содержать полные деревья, у которых все узлы-листья находятся на одной глубине. В этих деревьях, функциональный узел генерируется на каждом уровне де тех пор, пока не будет достигнут самый глубокий допустимый уровень, в точке которого генерируется терминальный узел. Пример полного и растущего деревьев показан на рисунке 5.
Другая половина популяции содержит растущие деревья. Формы растущих деревьев определены вероятносто с использованием вероятностей функционального и терминального узла. При создании каждого узла с использованием растущего метода, принимается решение о генерирации типа узла - функционального или терминального. В этом случае, 80 % узлов будут функциональными и 20 % будут терминальными. Как и в случае полных деревьев, когда достигается максимальная глубина, генерируется терминальный узел.
Во время генерации каждой из половин популяции, максимальная глубина программ увеличивается от 2 до максимальной глубины (в данном случае 6) для того, чтобы гарантировать самое широкое разнообразие особей в термах по форме и размеру. Необходимо отметить, что для дополнительной уверенности в разнообразии начальной популяции, выполняется проверка с целью гарантиии того, что каждый индивидуум является уникальным.
6.3 Развитие
Вероятность кроссинговера, репродукции и мутации является вероятностью каждого из соответствующих генетических операторов, используемых в развитии от одного поколения к следующему поколению. В данном случае используется 90 % вероятности скрещивания, 10 % вероятности репродукции, и мутация никогда не используется.
Параметр, управляющий вероятностью выбора функционального узла для скрещивания установлен высоким с целью обеспечить больше случаев, когда применяется скрещивание, фрагменты скрещивания представляют собой скорее маленькие поддеревья, чем узлы-листы особей. Это поощряет генерацию больших структур, а не обмен отдельными узлами.
При выполнении процесса развития, особи должны быть выбраны из популяции для участия в генетических операциях. Конкурирующий отбор, во-первых, включает случайный выбор двух особей из родительской популяции. Пары с самыми высокими фитьнес-функциями побеждают, и, следовательно, могут участвовать в генетических операциях. Этот метод подражает соревновонию между животными за право создания для себя пары.
7 Результаты
Необходимо было выполнить ГП несколько раз с различными начальными популяциями. Это проводилось потому, что было необходимо представить произвольную последовательность выполнения. Не было никакого фильтрования для особенно плохих серий. Результаты предназначены для демонстрации последовательности, с которой система ГП может наилучшим образом решать данную проблему.
График результатов из 13 серий системы показан рисунке 6, который демонстрирует выполнение лучшей особи относительно набора обучения. Соответствующий график на рисунке 7 показывает выполнение относительно тестирового множества. Для каждой серии присутствуют три области. Первая представляет процент всех правильных диагнозов, вторая показывает процент правильных положительных диагнозов и третья показывает процент правильных отрицательных диагнозов.
Решения, которые нас интересуют - это те, которые способны правильно диагностировать высокое число положительных и отрицательных случаев. Также интересны решения, которые способны дать хорошее обобщение случаев, где есть близкая корреляция между результатами в наборе обучения и тестовом множестве. Хорошее решение может быть, когда есть большое количество данных тестового множества. Сравнение результатов между набором обучения и тестовым множеством показано на рисунке 8.
На этом основании, серии 3, 8 и 10 предлагают хорошие решения, но лучшие решения появляются в сериях 6 и 13. Наилучшее решение в серии 6 правильно предсказывает 63 % положительных диагнозов и 71 % отрицательных диагнозов в наборе обучения, в тестовом множестве правильно диагностируется 64 % положительных случаев, и 65 % отрицательные случаев. Серия 13 правильно предсказывает 63 % положительных случая и 69 % отрицательных случаев в наборе обучения, и в тестовом множестве предсказывает 64 % положительных случаев и 61 % отрицательных.
Лучшее решение в серии 6 это 96-узловая программа, которая имела глубину 12, и в серии 13 – 75-узловая программа с глубиной 16.
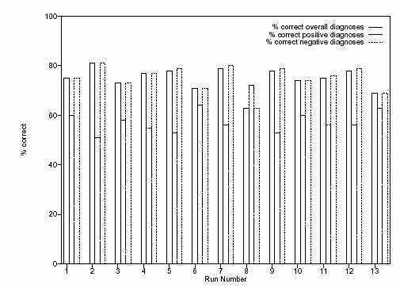
Рисунок 6 – Результаты 13 серий обучающего набора
8 Заключение
Результаты ясно демонстрируют, что генетическое программирование может эффективно использоваться для диагноза рака горла по результатам данных анкетного опроса пациентов.
Результаты являются особенно важными в свете проблемы несогласованностей в исходных данных. Это показывает, что такая система как ГП может быть использована на практике в реальном приложении диагностики, где такие помехи были бы неизбежны.
Другой момент, который может запретить работу системы - это то, что было относительно моло положительных примеров, на которых система могла учиться. Фактически только 2.7 % особей в исходных данных были положительно продиагностированы дантистом.
В работе Эллиотта (1993) говорится о том, что его система была способна правильно диагностировать 73 % положительных случаев, и 71 % отрицательных в его тестовом множестве. Результаты системы ГП поэтому благоприятны по сравнению с его результатами. Необходимо отметить, что проводить сравнение методов трудно, поскольку точные результаты Эллиотта не известны и обучающее и тестовое множества, используемые этими двумя системами, отличаются.
Предположение, что система ГП способна диагностировать рак горла подобно ситеме нейронной сети является главным преимуществом. Лучшее производимое ею решение может быть исследовано человеком, который способен понять логику принятия решения программой.
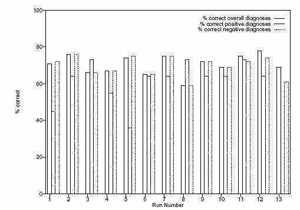
Рисунок 7 – Результаты 13 серий тестового множества
9 Дальнейшая работа
9.1 Сравнение с нейронными сетями
Неопределенное сравнение между системой генетического программирования и решением Нейронных сетей давалось в секции 8. Саяран Эллиотт осуществляет проект (Эллиотт, 1996), для получения инструмента диагностики для нейронных сетей, используя такие же данные, как и в данной статье. Учитывая полный доступ к его методам и результатам, надеемся, что в будующем будет сделано более надежное сравнение.
9.2 Применение для диагностики в медицине
Генетическое Программирование показало эффективность диагностирования рака горла. Нет никаких причин, которые мешают применению этого метода для диагностики других состояний и болезней в медицине.
В этой статье переменные, соответствующие диагнозу, были известны заранее. Возможно расширить диагностическую систему, взяв большое количество данных о прациентах, собранных например в медицине, и использовать GP, чтобы определить, какие из этих данных уместны при постановке диагноза конкретной болезни.
Быстрая диагностическая система, которая могла бы приспособиться за определенное время, была бы неоценима для быстрой диагностики пациентов с большим количеством проблем и низкой по стоимости по сравнению с существующими методами диагностики.
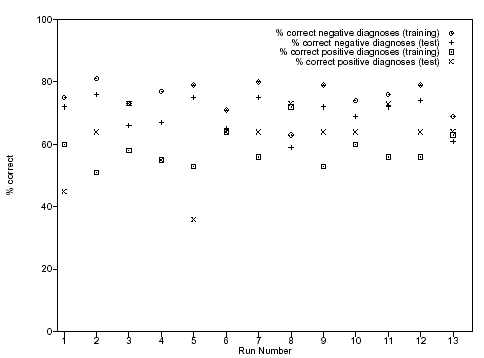
Рисунок 8 – Сравнение между обучающими и тестовым множеством 13 серий
Благодарности
Я хотел бы благодарить Eastman Зубной Институт, который обеспечил данные для этой статьи, и доктора Димитриса Дракопулуса за его поддержку и советы.
Ссылки
Elliott, A. (1993). The use of neural networks in medical statistical analysis, Master’s thesis, Eastman Dental
Institute.
Elliott, C. (1996). The use of inductive logic programming and data mining techniques to identify people at
risk of oral cancer and precancer, Master’s thesis, Brunel University.
Koza, J. R. (1989). Hierachical genetic algorithms operating on populations of computer programs,
Proceedings of the 11th International Joint Conference on Artificial Intelligence .
Koza, J. R. (1993). Genetic Programming: on the Programming of Computers by means of Natural Selection,
MIT Press.




