УДК 681.3
Алгоритмы с возможностью обучения для выполнения теоретико-множественных операций над грамматиками для создания интеллектуальных САПР
Фоменко А.А., Григорьев А.В.
Донецкий национальный технический университет
САПР ПО имеют достаточно высокую актуальность в наше время. В данной работе будет рассмотрено САПР ПО в экономической области работы с клиентом.
Осуществляется выбор модели по параметрам запрошенным клиентом. Клиент вводит нужные ему данные, система выбирает подходящие под этот шаблон бизнес планы и предлагает их на рассмотрение пользователю.
Определим некоторые понятия:
Прототип – результат работы программы Project Expert – готовый вариант бизнес плана промышленного предприятия, отражающий его создание, развитие и все показатели со структурой на протяжении жизненного цикла.
ЦПС – целевое пространство систем – набор решений (прототипов)
Техническое задание – заданные пользователем ограничения на бизнес план, на жизненный цикл, на параметры предприятия в течение жизненного цикла.
Для удобства работы в системе бизнес планы на входе системы будут представляться в виде текстов. Над ними будут производиться теоретико-множественные операции, для большего удобства тексты будут представлены в виде и - или деревьев внутри системы.
Существуют несколько вариантов алгоритмов работы с представлением текстов в виде дерева :
- бинарный алгоритм;
- алгоритмы лексического анализа;
- рассматриваемый в данной работе[1];
Алгоритм, умея производить теоретико-множественные операции над текстами, выполняет объединение текстов в один[2]. Технические задания также объединяются в одно дерево. Затем путем обхода дерева прототипов по всем или узлам будет строиться выходная последовательность параметров.
Обычные алгоритмы работают по принципу общения с некомпетентным пользователем, то есть пользователь не знает о предметной области ничего заранее и не может указать самостоятельно желаемые для него данные, может только отвечать на вопросы ЭС. В этом случае склеивание идет без анализа, сплошным методом. В данной работе будет рассмотрен модифицированный алгоритм обработки входных текстов – когда ЭС содержит базовую грамматику для анализа текстов и пользователь компетентен для указания начальных ограничительных параметров.
Рассмотрим на примере различия алгоритмов на основных вариантах входных данных.
1. Грамматика отсутствует полностью, пользователь некомпетентен
В этом случае система не знает ничего
о наборе символов и ключевых слов текстов
и объединение будет идти «вслепую».
Обычное
объединение с преобразованием в и –
или дерево идет по принципу сравнения
до нахождения первого различающегося
элемента. Например рассмотрим склеивание
двух текстов представляющих собой
простой список цифр. Объединение
производится как показано на рисунке
1.
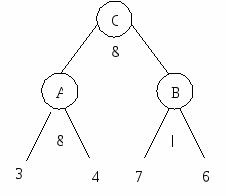
В результате будет сформировано и-или дерево как показано на рисунке 2. При выводе целевой последовательности по дереву система будет вынуждена спрашивать у пользователя какие параметры нужны. Например при обходе слева направо система в точке «B» уже построив список { 3,4 } спросит у пользователя какой должен быть третий параметр и в зависимости от ответа, на выходе будет нужная последовательность параметров.
Этот алгоритм не способен на обучение, то есть для него не важна суть встретившегося символа, он просто сравнивается по своему номеру с соответствующим элементом другого текста. Таком образом при наличии часто повторяющихся элементов возможно нецелесообразно громоздкое дерево, так как в него будут включены все элементы столько раз сколько они встретились во всех текстах.
|
3 |
= |
3 |
|
|
|
4 |
= |
4 |
|
|
|
7 |
!= |
6 |
|
|
|
|
|
|
|
|
|
|
A= |
& |
3 |
4 |
|
|
B= |
V |
7 |
6 |
Рисунок 1 - Объединение множеств
Рисунок 2 - И-ИЛИ дерево
В этом случае на том же примере пользователь заранее может задать нужный ему параметр, к примеру чтобы один из параметров A был равен 4 а параметр B был равен 6. Тогда система просто объединит множества и при обходе дерева построит правильно выходную последовательность параметров.
К недостаткам данного варианта также относится склеивание сплошным методом, то есть без сортировки и фильтрации, включая все повторения, что влечет за собой увеличение количества памяти, занимаемой деревом.
3. Грамматика присутствует частично, пользователь компетентен
Если пользователь задаст начальные данные о синтаксисе, базовом наборе термов, синтермов, которые встречаются в текстах, то система сможет распознавать тексты по ключевым данным, что упростит задачу.
Рассмотрим элементарный пример – тексты представляют собой некоторый код программы. Как известно в коде много повторяющихся ключевых слов. И при использовании грамматики можно будет при нахождении определенного синтерма просто дописывать в список повторений этого синтерма в текстах идентификатор прототипа из которого взят данный синтерм и место где он встретился (строка или последовательный номер). То есть алгоритм будет способен разбирать что за синтерм поступил на вход. Этап объединения всех текстов в одно и-или дерево с запоминанем зависимостей и повторений будем называть обучением, так как система окончательно создает полное представление о ЦПС. Затем будет строиться выходная последовательность с учетом повторений и зависимостей и будет легче отсекать неверные варианты. К примеру если встретился синтерм который присутствует только в первом третьем из пяти текстов, то второй, четвертый и пятый тексты будут отброшены и более рассматриваться не будут.
4. Грамматика присутствует полностью, пользователь компетентен
Если пользователь достаточно квалифицирован, то он задает полностью всю грамматику, то есть все возможные термы, синтермы, встречающиеся в текстах и зависимости, где и когда они встречаются. В таком случае этап обучения пропускается, так как уже вся грамматика ЦПС уже известна, и начинается вывод нежной последовательности исходя из технического задания.
Литература
1. Григорьев А.В. Алгоритм выполнения теоретико-множественных операций над грамматиками в среде специализированной оболочки для создания интеллектуальных САПР. Науковi працi нацiонального технiчного унiверситета. Серия «Проблемы моделирования и автоматизации проектирования динамических систем» (МАП -2002). Выпуск 52: Донецк: ДонНТУ, 2002. - С.83-93.
2. Григорьев А.В. Теоретико-множественные операции над грамматиками как механизм работы со знаниями в интеллектуальных САПР. Вiсник Схiдноукраiнського нацiонального унiверситету iменi Володимира Даля, N 2(48). Луганск, ВУТУ, 2002. С. 186-194.