И.А. Чернов, О.А. Мандрикова, О.И.Федяев Автоматизированное извлечение знаний из баз данных. Информатика и компьютерные технологии 2005/Сб. трудов первой международной студенческой научно-технической конференции. Ссылка: http://masters.donntu.ru/2006/fvti/ichernov/library/my_donetsk05.htm
Рассматривается задача автоматического извлечения знаний из баз данных, решение которой ускорит создание интеллектуальных систем принятия решений. В настоящее время для ее решения предложено много методов, составляющих новую технологию Data Mining[1,2]. Автоматизация извлечения знаний из баз данных должна учитывать следующую специфику:
- Данные имеют неограниченный объем.
- Данные являются разнородными (количественными, качественными, текстовыми).
- Извлеченные знания должны быть конкретны и понятны.
- Инструменты обнаружения знаний должны быть просты в использовании и работать при наличии «сырых» данных.
В основу современных методов технологии Data Mining (discovery-driven data mining) положена концепция шаблонов, отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам(классам) данных, которые могут быть компактно выражены в понятной человеку форме. Методы поиска шаблонов не ограничиваются рамками априорных предположений о структуре выборки и вида распределения значений анализируемых показателей. Важным достоинством технологии Data Mining является нетривиальность разыскиваемых шаблонов, т.е. они должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge)[1].
Существующие системы Data Mining [1] дорогостоящие и не ориентированы на решение задач принятия решений. Самыми известными являются See5/С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Стоимость этих систем варьируется от 1 до 10 тыс. долл. Поэтому в данной работе рассматривается создание подобной системы автоматического извлечения знаний из баз данных разного формата с возможностью принятия решения на основе выявленных знаний. Структура разрабатываемой системы приведена на рис. 1.
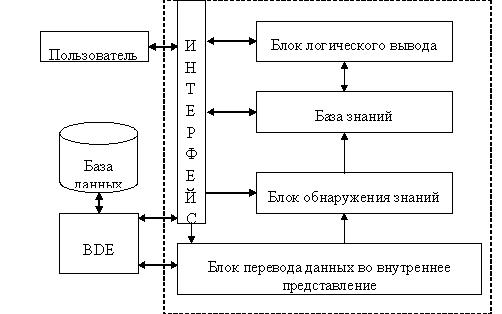
Пользовательский интерфейс обеспечивает доступ ко всем возможностям системы и управляет процессами извлечения знаний и принятием решений. Качество обнаружения знаний во многом зависит от участии пользователя. Первичная подготовка данных осуществляется в блоке перевода данных во внутреннее представление, учитывающие особенности алгоритмов извлечения знаний. Блок обнаружения знаний основан на алгоритме CLS [1,2], который выявляет скрытые закономерности в данных. Эти закономерности формируются в виде деревьев решений и сохраняются в базе знаний в форме продукционных правил. Извлечённые знания могут пополнять существующую базу знаний некоторой экспертной системы или сразу использоваться для выработки рекомендаций по достижению поставленных целей.
Алгоритм CLS циклически разбивает обучающие примеры на классы в соответствии с переменной, имеющей наибольшую классифицирующую силу. Каждое подмножество примеров (объектов), выделяемое такой переменной, вновь разбивается на классы с использованием следующей переменной с наибольшей классифицирующей способностью и т. д. Разбиение заканчивается, когда в подмножестве оказываются объекты лишь одного класса. В ходе процесса формируется дерево решений. Пути движения по этому дереву от его корня к листьям определяют логические правила в виде цепочек конъюнкций.
Оценка эффективности алгоритма выполнялась на интеллектуальном анализе медицинских данных небольшого объёма - 74 записи. Из них были выявлены знания в количестве 9 продукций. Для увеличения практической значимости разрабатываемой системы (EasyGetKnowledge) намечается расширить ориентацию алгоритма извлечения на базы данных различного формата.
- Дюк В.А., Самойленко А.П. Data Mining: учебный курс – СПб: «Питер», 2001 – 368 с.
- Дюк В.А. Обработка данных на ПК в примерах. – СПб: "Питер", 1997 – 240 с.