Winston H, Lyndon S
Most semantic video search methods use text-keyword queries or example video clips and images. But such methods have limitations. Here the authors introduce two reranking processes for image and video search that automatically reorder results from initial text-only searches based on visual features and content similarity.
The continuing growth of online video data, digital photos, and 24-hour broadcast news has helped make video and image retrieval an active research area. Current semantic video search usually builds on text search by using text associated with video content, such as speech transcripts, closed captions, or video optical character recognition (OCR) text. Adding multiple modalities such as image features, audio, face detection, and high-level concept detection can improve text-based video search systems.14 Researchers often achieve this using multiple query example images, applying specific concept detectors, or incorporating highly tuned retrieval models for specific query types. However, because it's difficult to acquire the extra image information or build the models in advance, such approaches are impractical for large-scale applications.5
It's also difficult for users to acquire example images for example-based queries. When users provide image examples, the examples are often few in number and fail to capture the relevant regions of high-dimensional feature space that might contain the true positive videos. Practically, users prefer "search by text" rather than "search by examples."6
To address the problems of example-based video search approaches and avoid the use of specialized models, we conduct semantic video searches using a reranking method that automatically reorders the initial text search results based on visual cues and associated context. We developed two general reranking methods that explore the recurrent visual patterns in many contexts, such as the returned images or video shots from initial text queries, and video stories from multiple channels.
Visual reranking
Assume our initial text search returns n visual documents {dlt d2, ..., d„},. These documents might include Web pages, images, and video stories. The visual reranking process improves search accuracy by reordering the visual documents based on multimodal cues extracted from the initial text search results and any available auxiliary knowledge. The auxiliary knowledge can be features extracted from each visual document or the multimodal similarities between them.
Pseudorelevance feedback279 is an effective tool for improving initial text search results in both text and video retrieval. PRF assumes that a significant fraction of top-ranked documents are relevant and uses them to build a model for reranking the search result set.7 This is in contrast to relevance feedback, in which users explicitly provide feedback by labeling results as positive or negative.
Some researchers have implemented the PRF concept in video retrieval. Chua et al., for example, used the textual information in top-ranking shots to obtain additional keywords to perform retrieval and rerank the baseline shot lists.2 Their experiment improved mean average precision (MAP) from 0.120 to 0.124 in the TRECVID 2004 video search task (see http://www-nlpir.nist.gov/ projects/trecvid; MAP is a search performance metric used in TRECVID, a National Institute of Standards and Technology-sponsored conference focused on information retrieval in digital video). Other researchers sampled the pseudonegative images from the lowest rank of the initial query results, used the query videos and images as the positive examples, and formulated retrieval as a classification problem.8 This improved the search performance from MAP 0.105 to 0.112 in TRECVID 2003.
Reranking approaches
Patterns with strong visual similarities often recur across diverse video sources. Such recurrent images or videos frequently appear in image search engines (such as Yahoo or Google) and photo-sharing sites (such as Flickr). In earlier work,10 we analyzed the frequency of such recurrent patterns (in terms of visual duplicates) for cross-language topic tracking (a large percentage of international news videos share common video clips, near duplicates, or high-level semantics). Based on our observations, we propose two general, visual search reranking approaches.
We first propose an image search reranking approach called information bottleneck (IB) reranking.511 This approach explores the fact that in image search, multiple similar images are often spread across different spots in the top-level pages of the initial text search results.5 IB reranking revises the search relevance scores to favor images that occur multiple times with high visual similarity and high initial text retrieval scores. Visual similarity is typically based on matching image features extracted from image frames in video shots. Thus, we can easily apply it to rerank search results at the image or video shot levels.
The preferred search level is sometimes higher than the image or shot level—that is, a semantic level such as news stories or scenes in films. In such cases, feature-based similarity between visual documents isn't well defined. To address this issue, we propose contextual links. For example, two stories share the same or similar contexts if they're related to the same topic and thus share some common or near-duplicate visual footage. Our context-reranking approach explores such contextual similarity among high-level video stories using a random walk framework.12
IB-reranking: Image/video reranking based on recurrent frequency
In image/video search systems, we're given a query or a statement of information need, and must estimate the relevance R(x) of each image or video shot in the search set, x e X, and order them by relevance scores. Researchers have tested many approaches in recent years—from simply associating video shots with text search scores to fusing multiple modalities. Some approaches rely on user-provided query images as positive examples to train a supervised classifier to approximate the posterior probability P(Y\X), where Fis a random variable representing search relevance.9 They then use the posterior probability for R(x) in visual ranking.
Text search results generally put certain relevant images near the top of the return set. In large image or video databases, in particular, some positive images might share great visual similarity, but receive quite different initial text search scores. For example, shows the top 24 shots from a story-level text search for TRECVID 2005 topic 153, "Find shots of Tony Blair." We can see recurrent relevant shots of various appearances among the return set, but they're mixed with some irrelevant shots (for example, anchor or graphic shots).
Thus, instead of user-provided search examples, we consider the search posterior probability, estimated from initial text-based results in an unsupervised fashion, and the recurrent patterns (or feature density) among image features, and use them to rerank the search results. A straightforward implementation of the idea is to fuse both measures—search posterior probability and feature density—in a linear fashion. This fusion approach is commonly used in multimodal video search systems.5 We can formulate the approach as
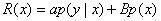
where p(y\x) is the search posterior probability, p(x) is the retrieved image's feature density, and a and p are linear fusion scalars.
Equation 1 incurs two main problems, which our prior experiment confirms.5 The posterior probability p(y\x), estimated from the text query results and (soft) pseudolabeling strategies, is noisy; we need a denoised representation for the posterior probability. In addition, the feature density estimation p{x) in Equation 1 might be problematic because recurrent patterns that are irrelevant to the search (for example, anchors, commercials, and crowd scenes) can be frequent. Instead, we should consider only those recurrent patterns within buckets (or clusters) of higher relevance. To exploit both search relevance and recurrent patterns, we represent the search relevance score R(x) as
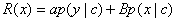
where p(y\c) is a denoised posterior probability smoothed over a relevance-consistent cluster c, which covers image x; and p(x\c) is the local feature density estimated at feature x. The cluster-denoising process has been effective in text search.13 Meanwhile, we use local feature density p{x\c) to favor images occurring multiple times with high visual similarity. The choice of parameter a or p will affect the reranked results. In our preliminary experiments, the denoised posterior probability p{y\c) was more effective and played a more important role in search relevance than the pattern recurrence within the same relevant clusters. Accordingly, an intuitive approach is to let a be significantly larger than (3 so that the reranking process first orders clusters at a coarse level and then refines the image order in each cluster according to local feature density.
Two main issues arise in this proposed approach:
-How can we find the relevance-consistent clusters, in an unsupervised fashion, from noisy text search results and high-dimensional visual features?
-How can we use the recurrent patterns across video sources?
To address the first problem, we adopt the IB principle,5-11 which finds the optimal clustering of images that preserves the maximal mutual information about the search relevance. We iter-atively update the denoised posterior probabilities p(y\c) during the clustering process. We then estimate the feature densities p{x\c) from each cluster с accordingly.
In the figure, the reranking method discovers four relevance-consistent clusters automatically. Images of the same cluster (that is, Q) have the same denoised posterior probability p(y\c), but might have recurrent patterns with different appearances. For example, Cj has three regions with high density in the feature space. We first rank the image clusters by posterior probability p(y\c) and then order with-in-cluster images by the local feature density p{x\c). In short, the visually consistent images that occur most frequently within higher-relevance clusters will receive higher ranks. Note that the visual features we adopted are grid color moments and Gabor texture. More technical details are available elsewhere.
References
[1] E. Chang, K.-T. Cheng, W.-C. Lai, C.-T. Wu, C.-W. Chang, and Y.-L. Wu. PBIR — a system that learns subjective image query concepts. Proceedings of ACM Multimedia, http://www.mmdb.ece.ucsb.edu/~demo/corelacm/, pages 611-614, • October 2001.
[2] E. Chang and B. Li. Mega — the maximizing expected generalization algorithm for learning complex query concepts (extended version). Technical Report http://www-db.stanford.edu/~echang/mega-extended.pdf, November 2000.
[3] A. Gersho and R. Gray. Vector Quantization and Signal Compression. Kluwer Academic, 1991.
[4] B. Li, E. Chang, and C.-S. Li. Learning image query concepts via intelligent sampling. Proceedings of IEEE Multimedia and Expo, August 2001.
|


